Downloaded 133 times




























![www.citeulike.org Richard Cameron Kevin Emamy Picture from http://network.nature.com/people/mfenner/blog/2009/01/30/interview-with-kevin-emamy and http://www.citeulike.org/faq/faq.adp The reason I wrote the site [citeulike.org] was, after recently coming back to academia, I was slightly shocked by the quality of some of the tools available to help academics do their job. I found it preferable to start writing proper tools for my own use than to use existing software.](https://image.slidesharecdn.com/defrosted-090316094940-phpapp01/75/Defrosting-the-Digital-Library-A-survey-of-bibliographic-tools-for-the-next-generation-web-43-2048.jpg)
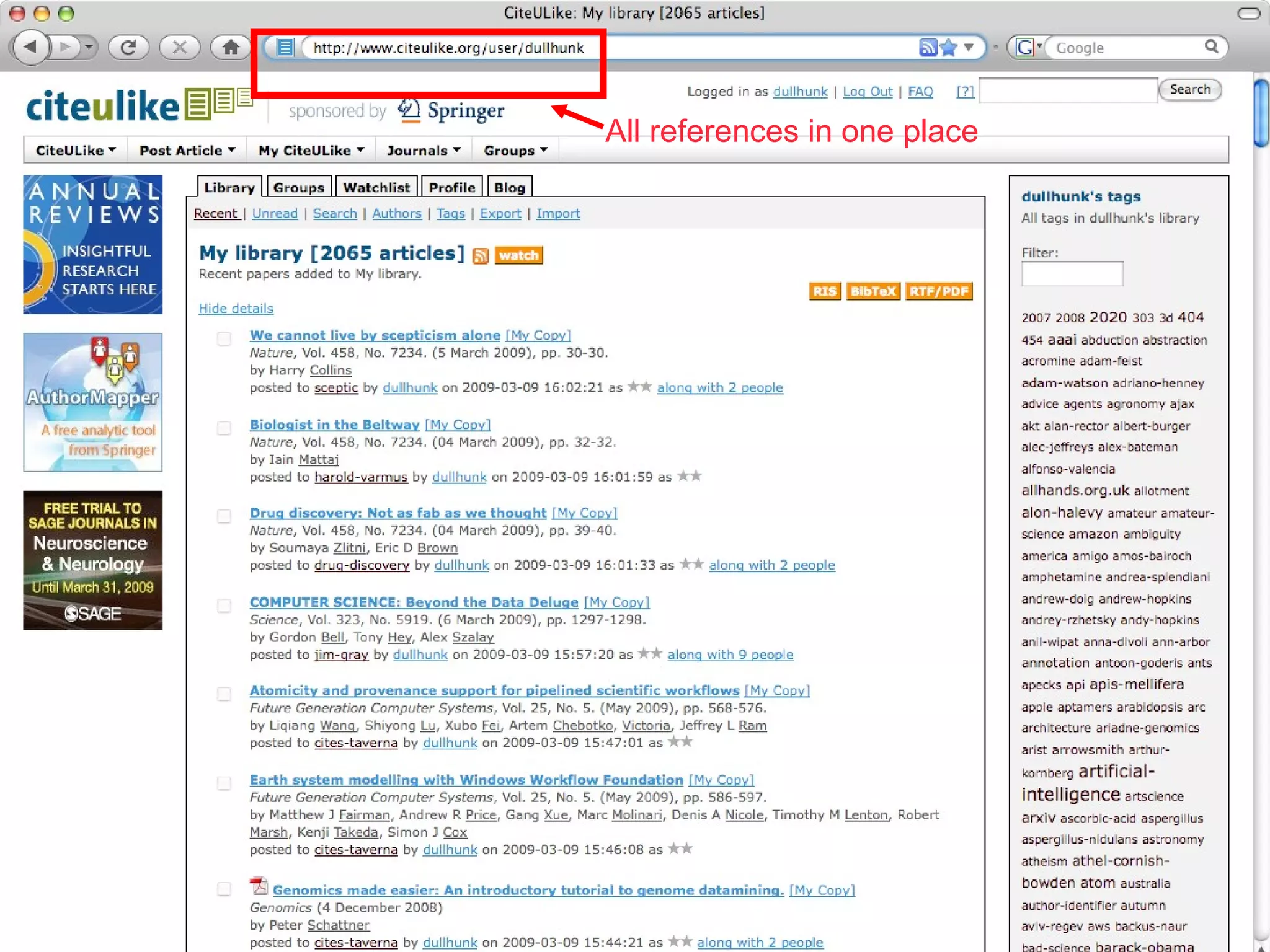
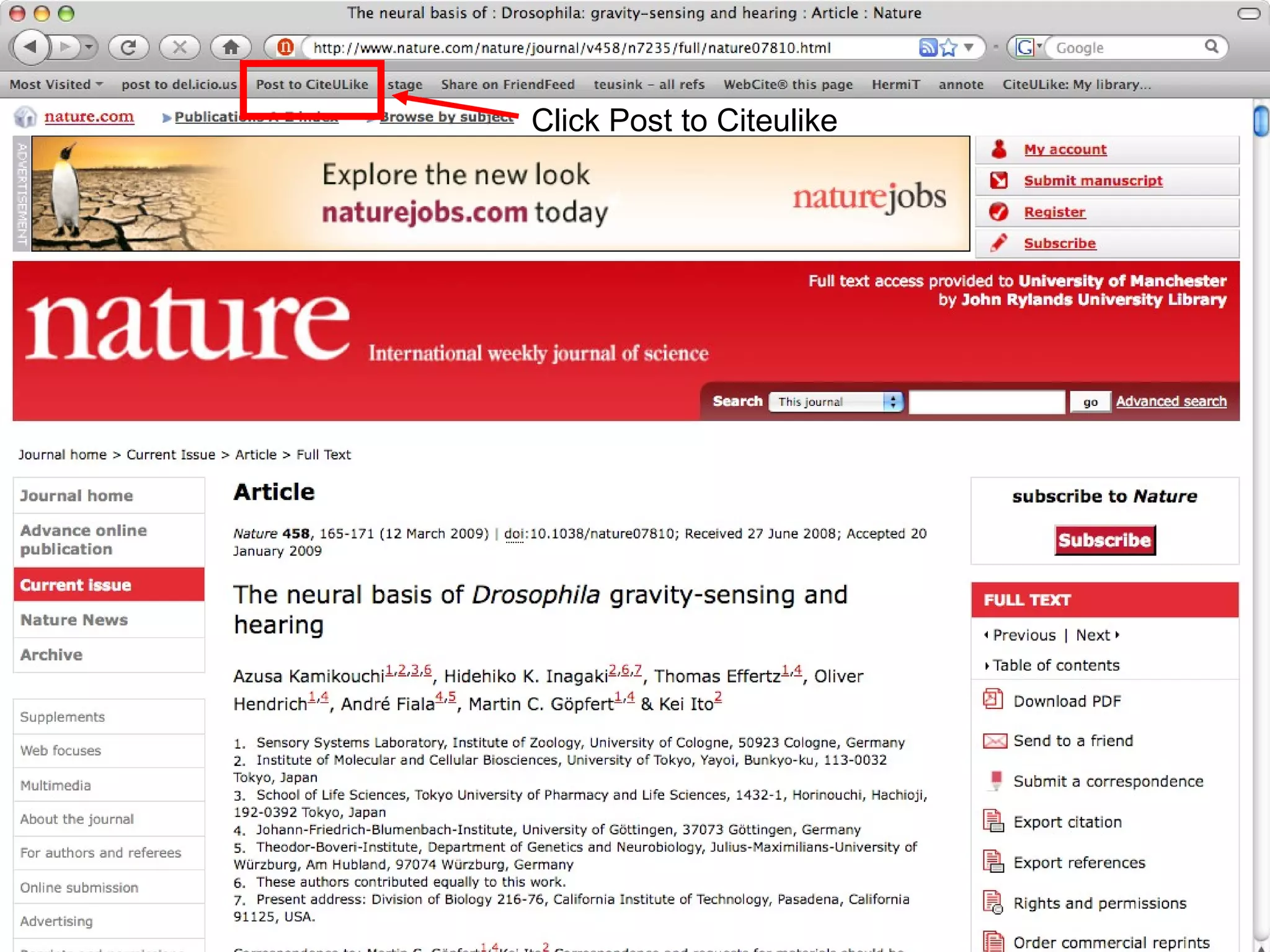
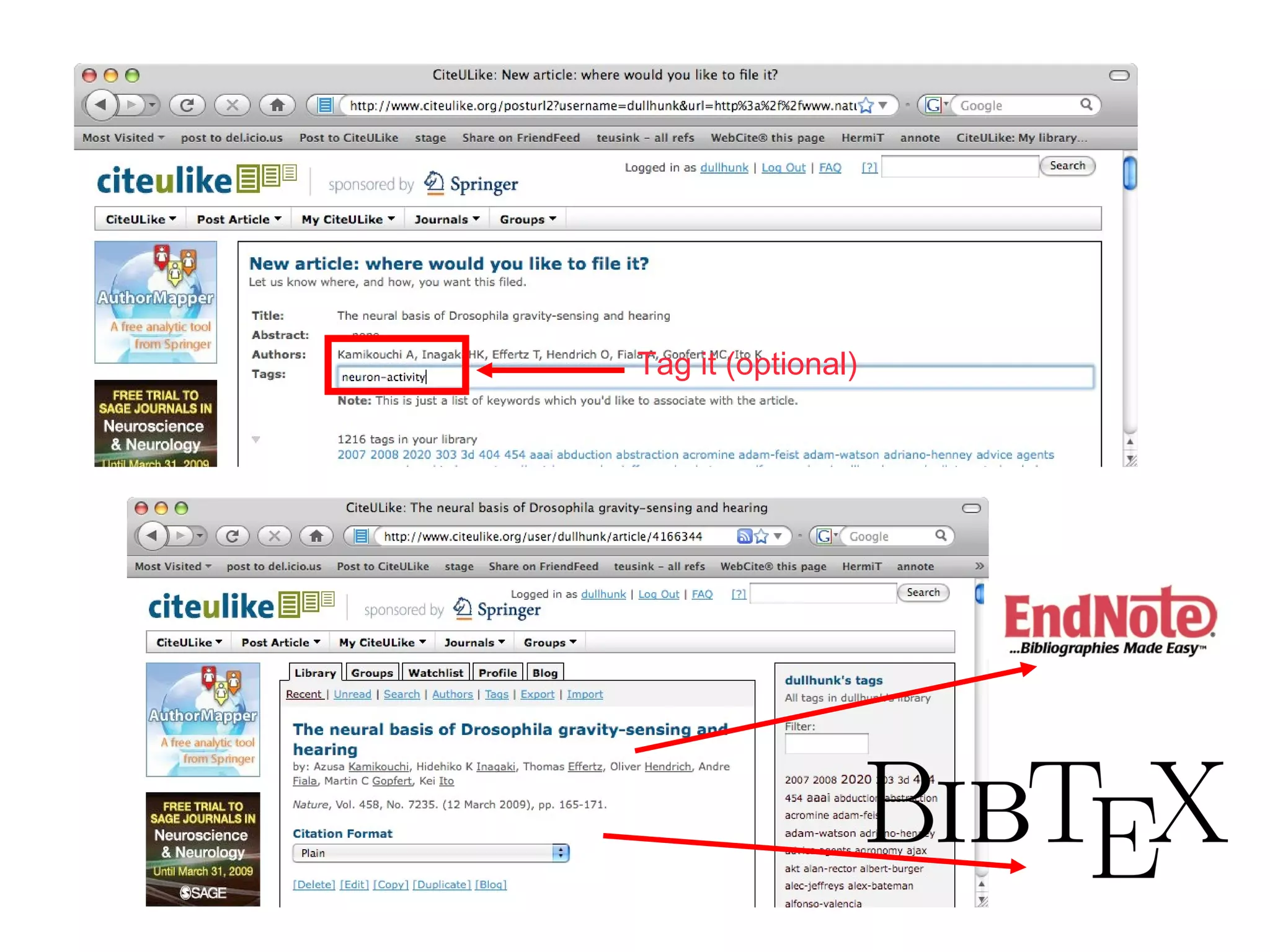
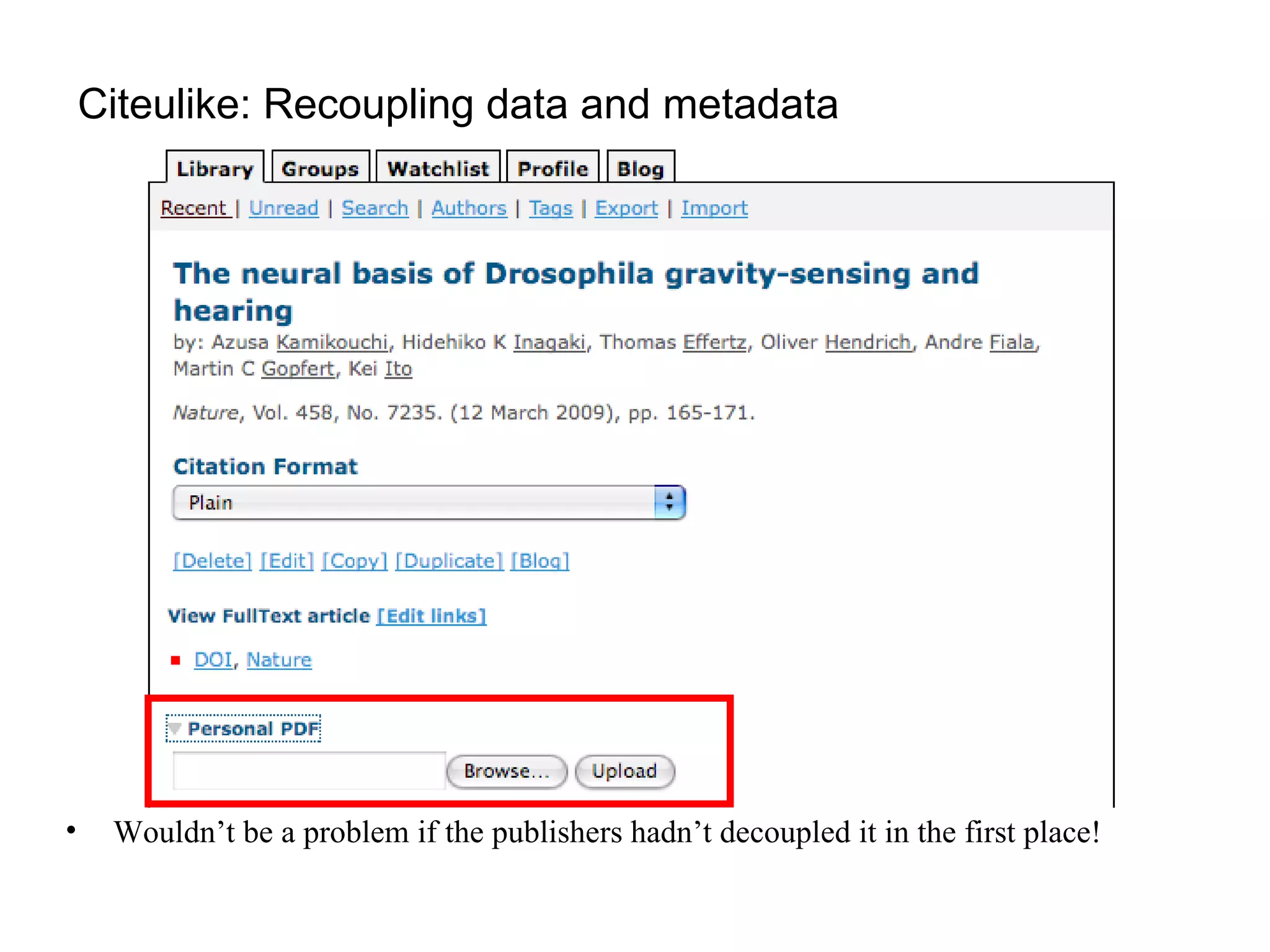

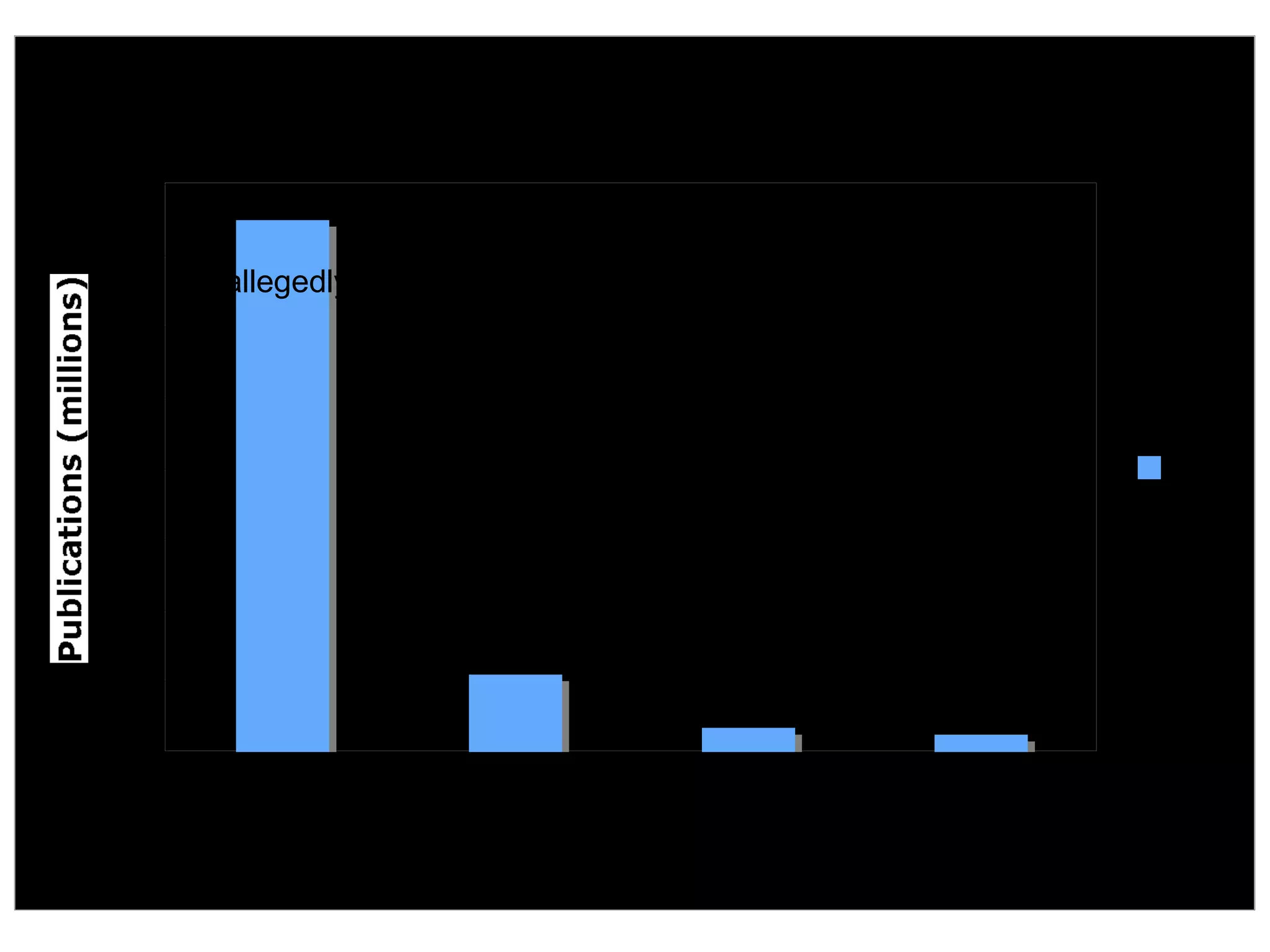


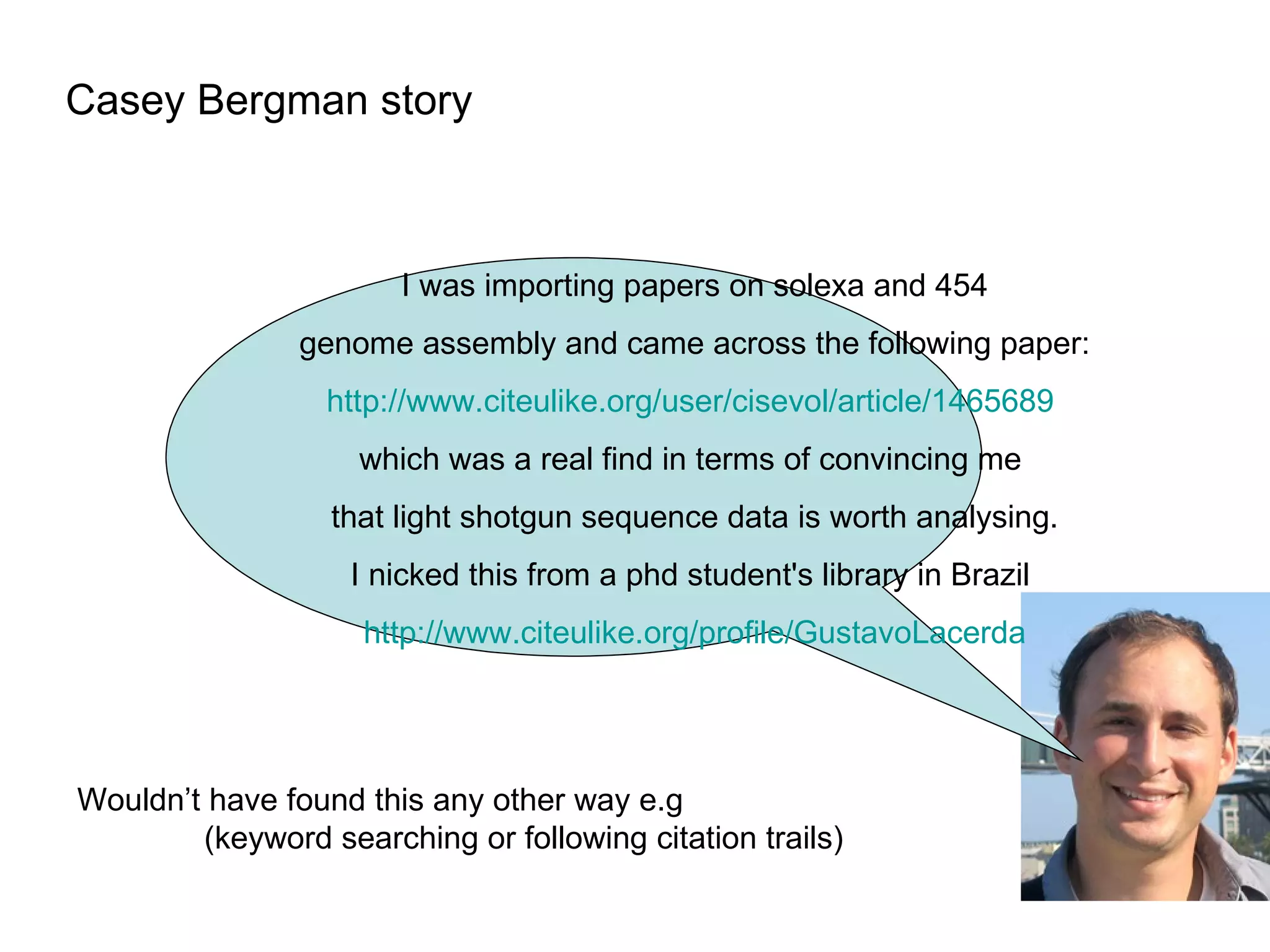

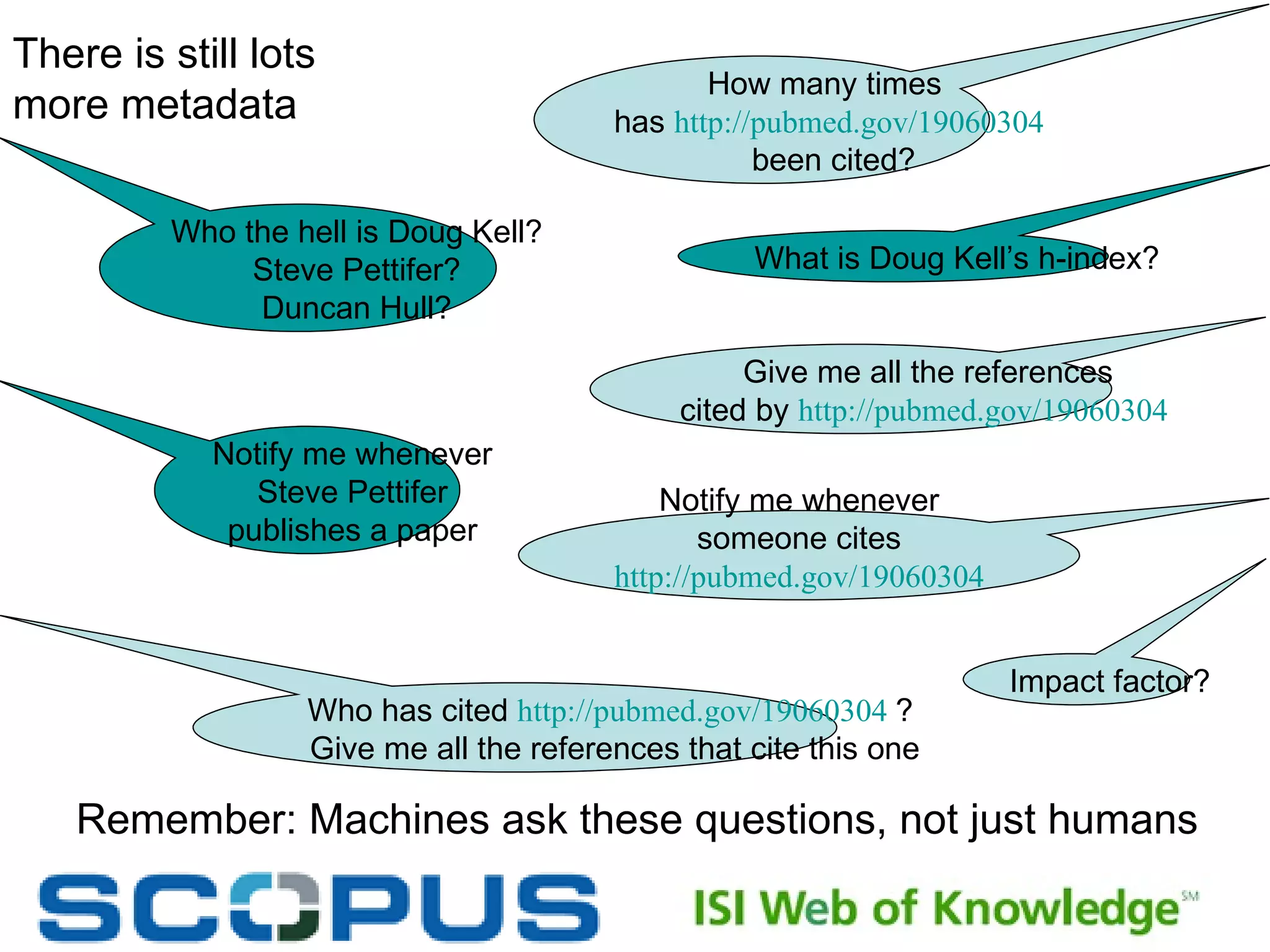








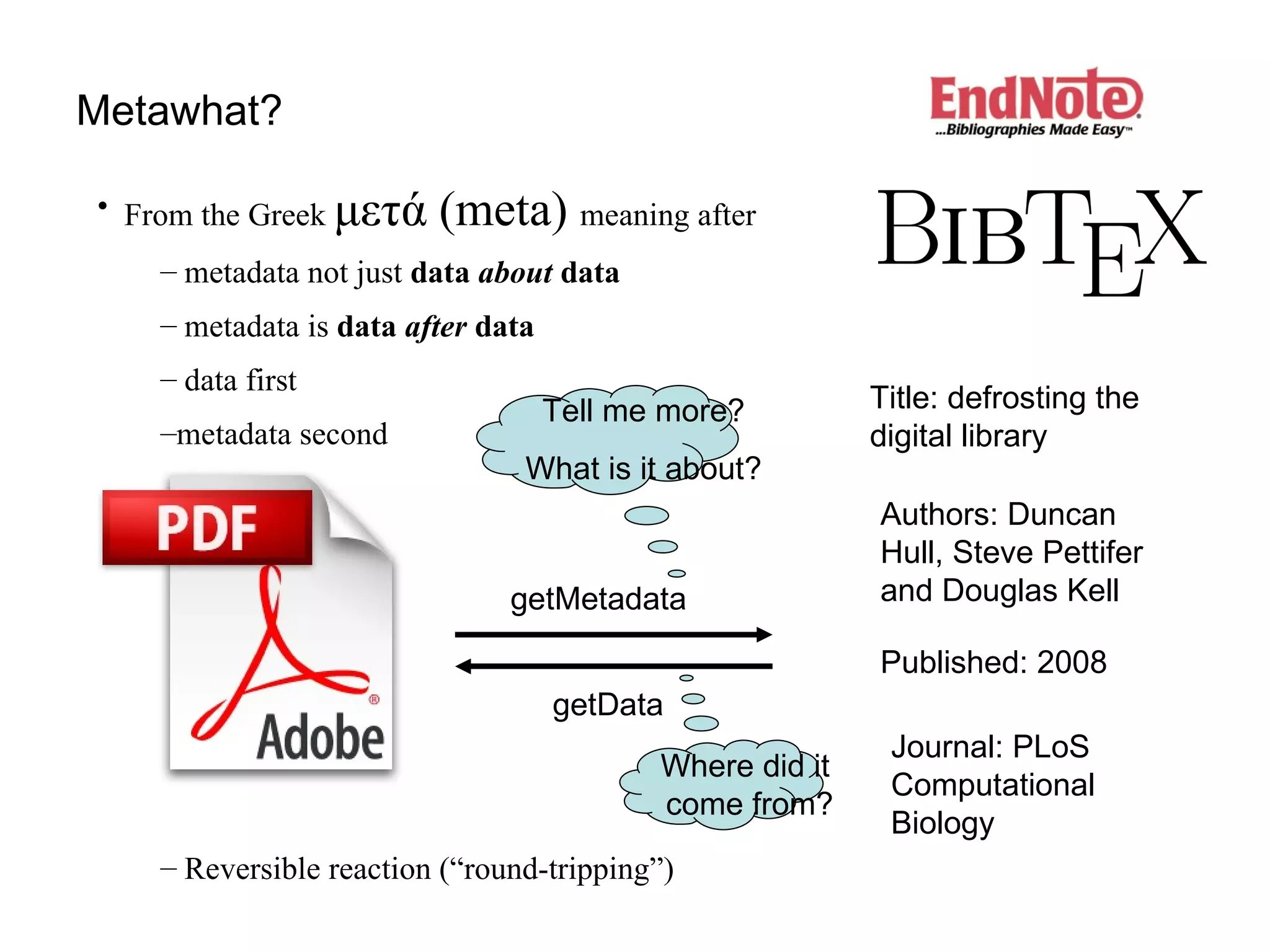
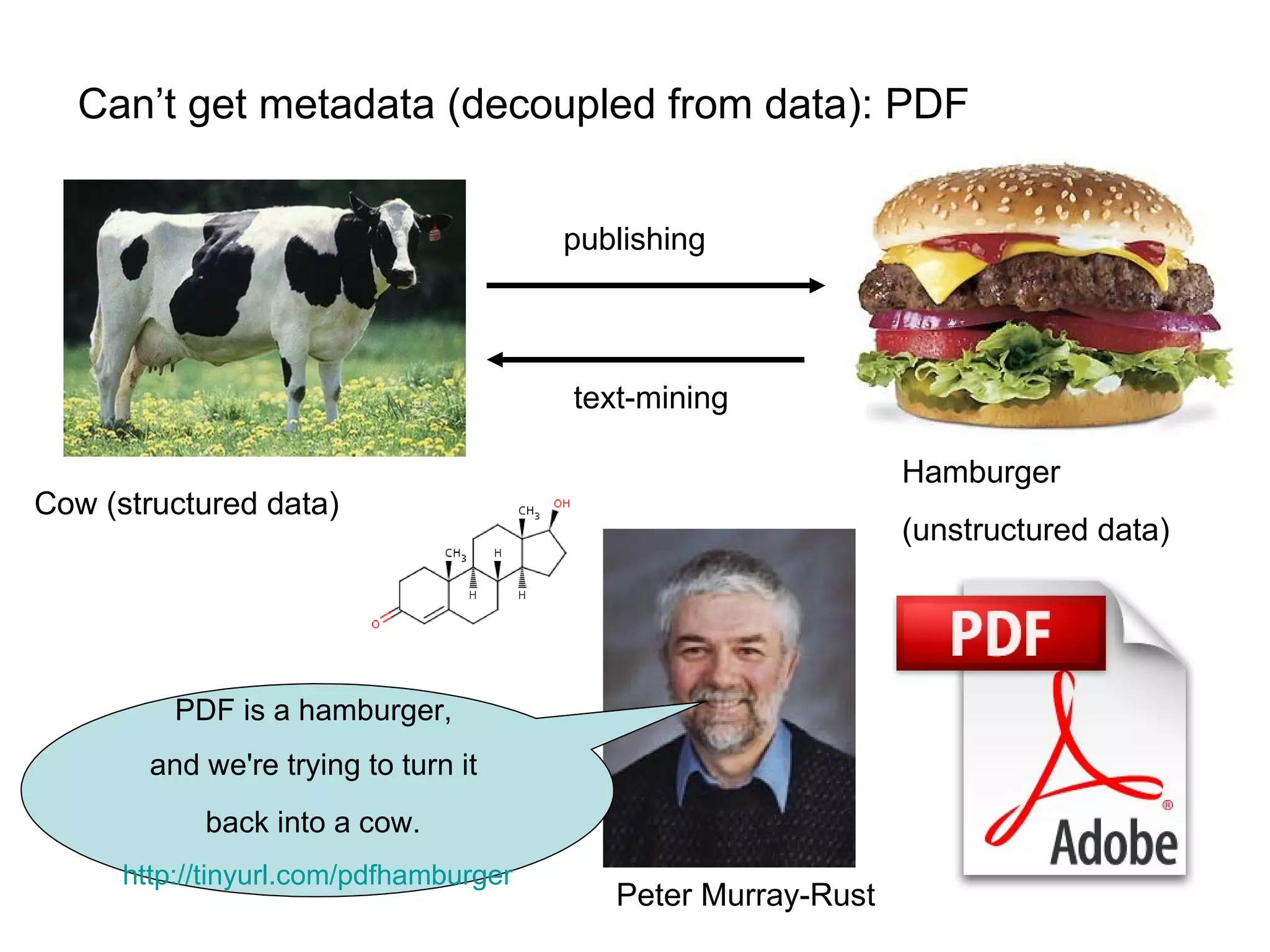
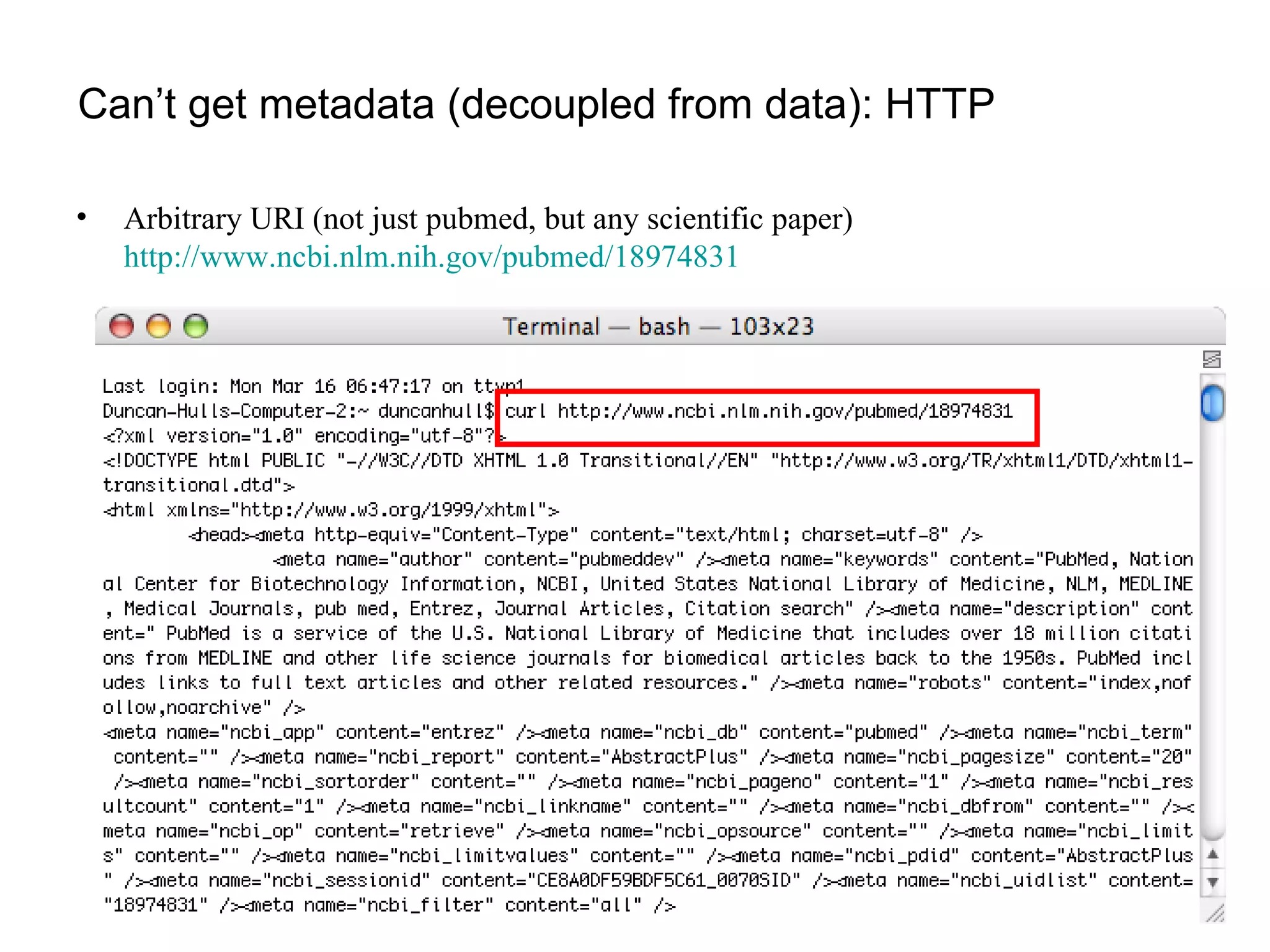
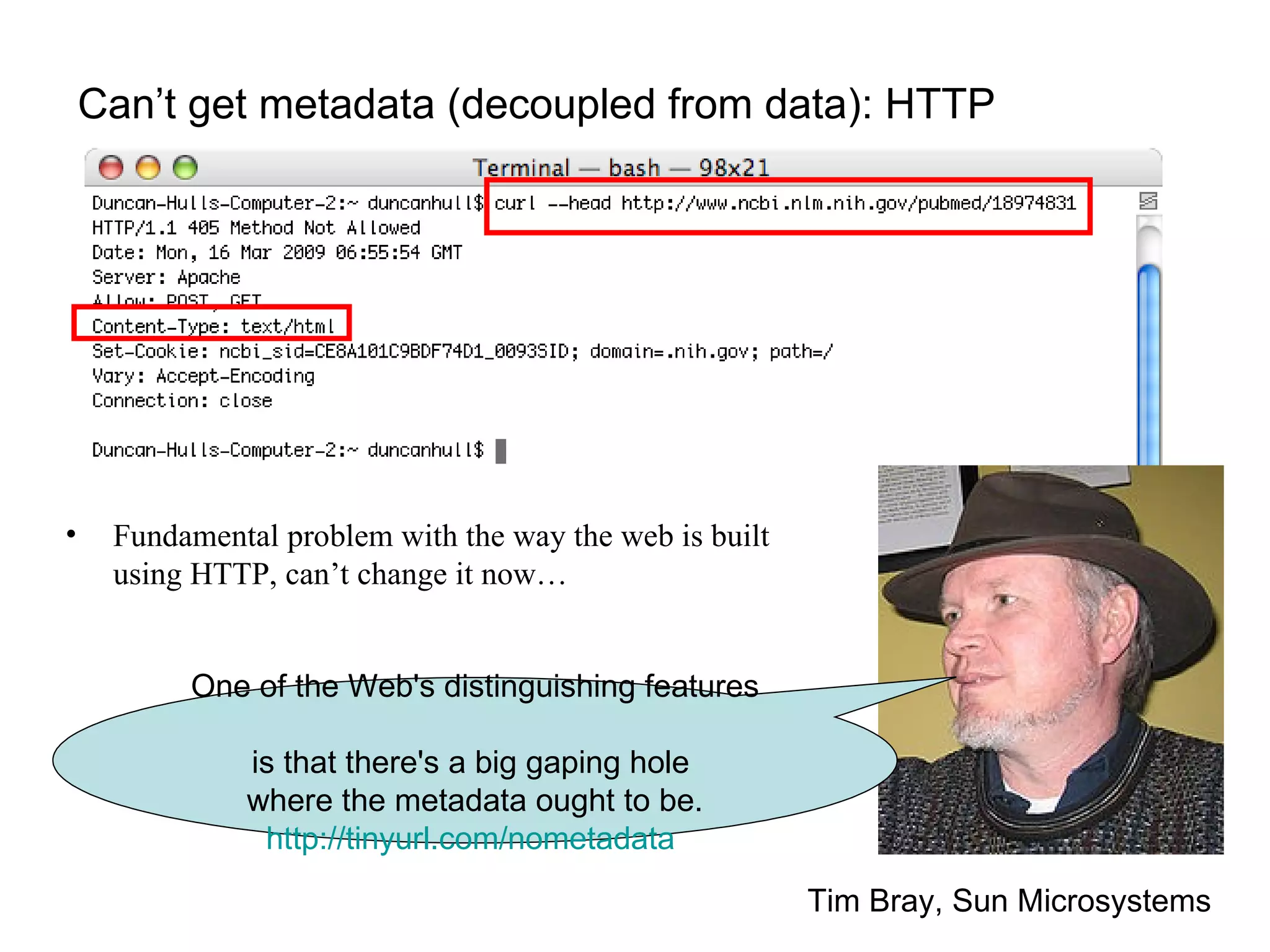
The document discusses the challenges and inefficiencies within digital libraries for scientists, particularly issues surrounding accurate identification of authors and publications as well as data and metadata management. It highlights various bibliographic tools aimed at improving these processes, such as Citeulike and Mendeley, while emphasizing the need for better metadata practices to enhance usability. The author calls for a more engaged approach towards metadata among scientists, as its quality significantly influences decision-making in the academic landscape.























































































