Download as PDF, PPTX






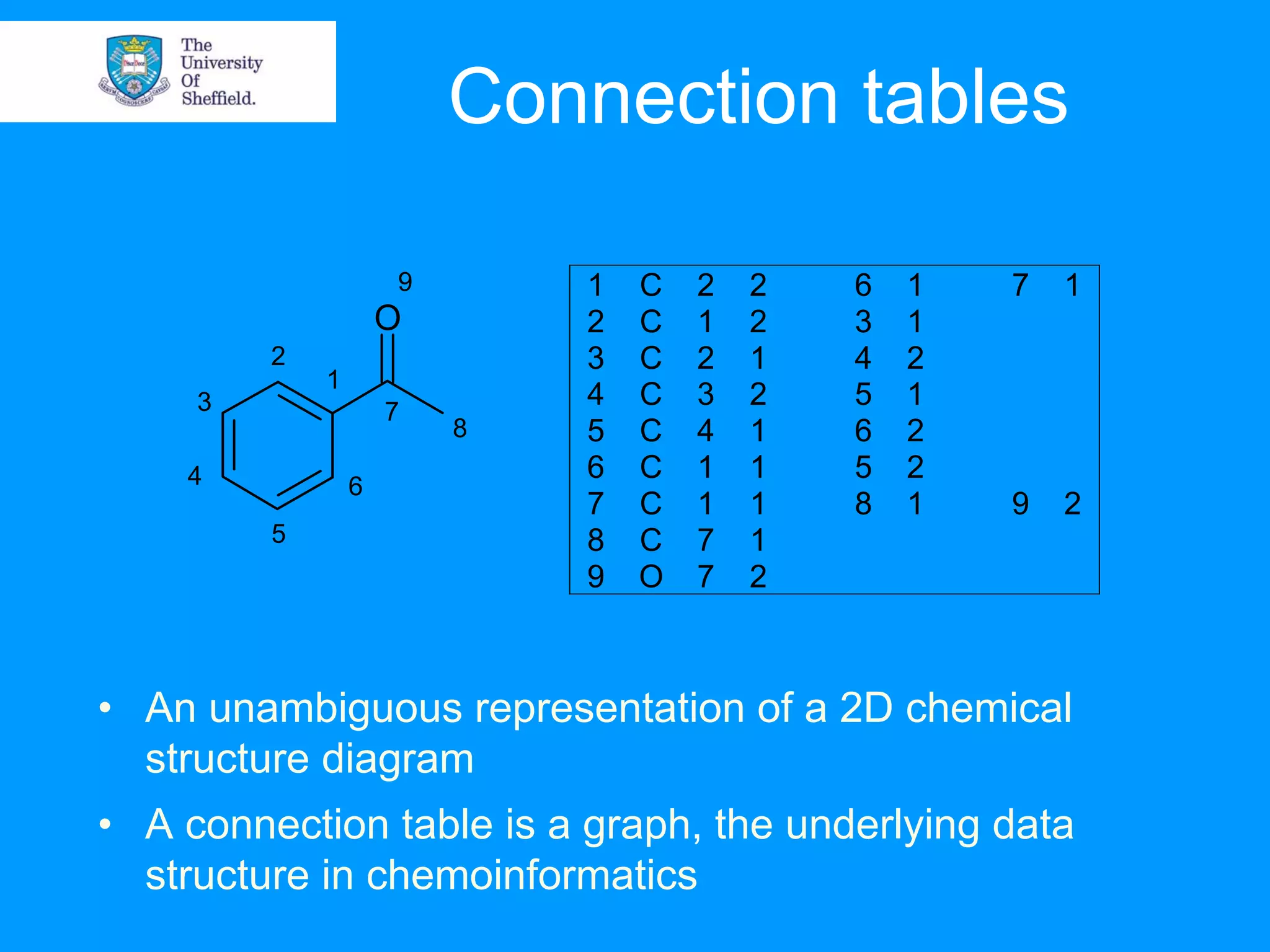
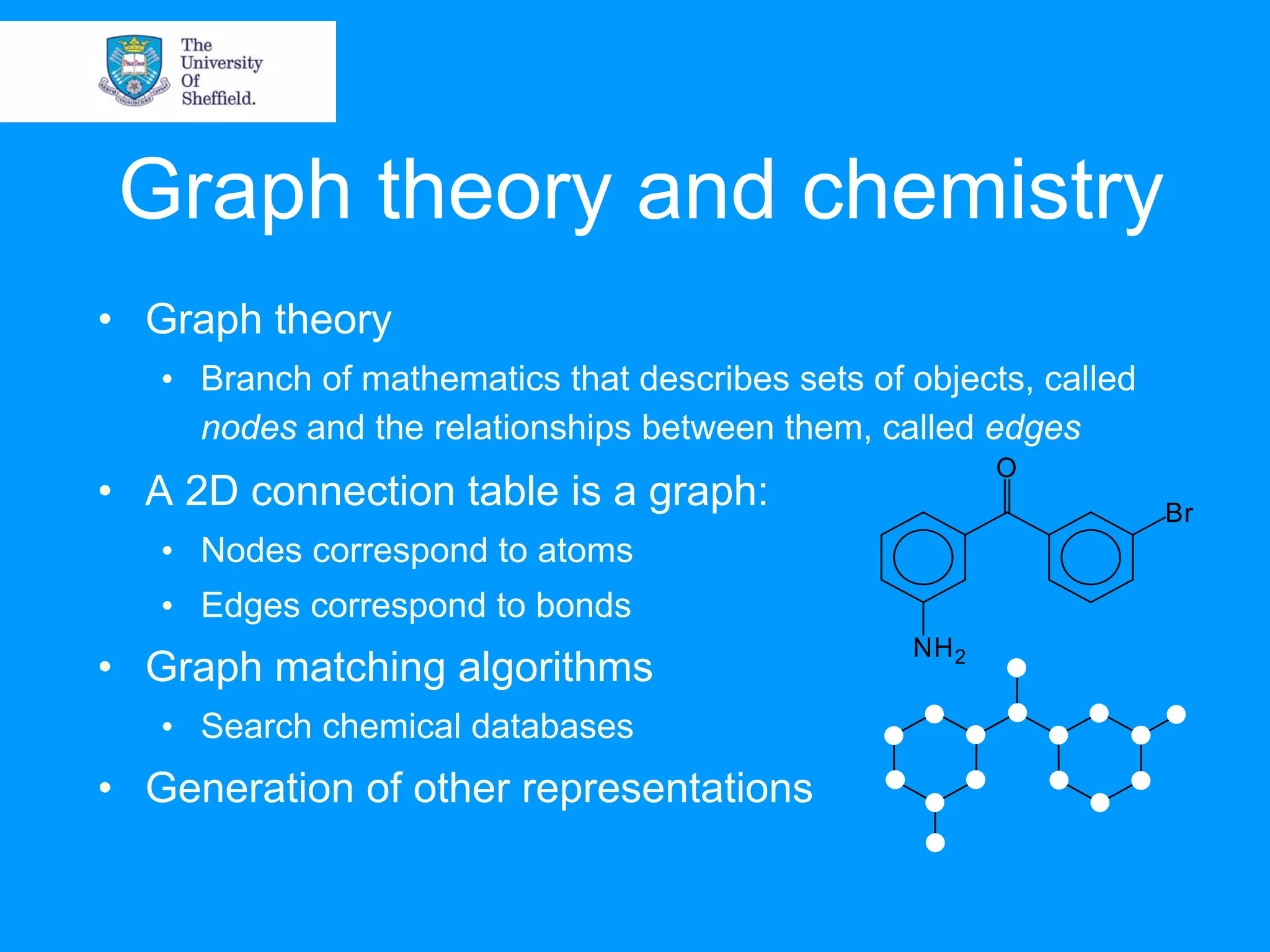

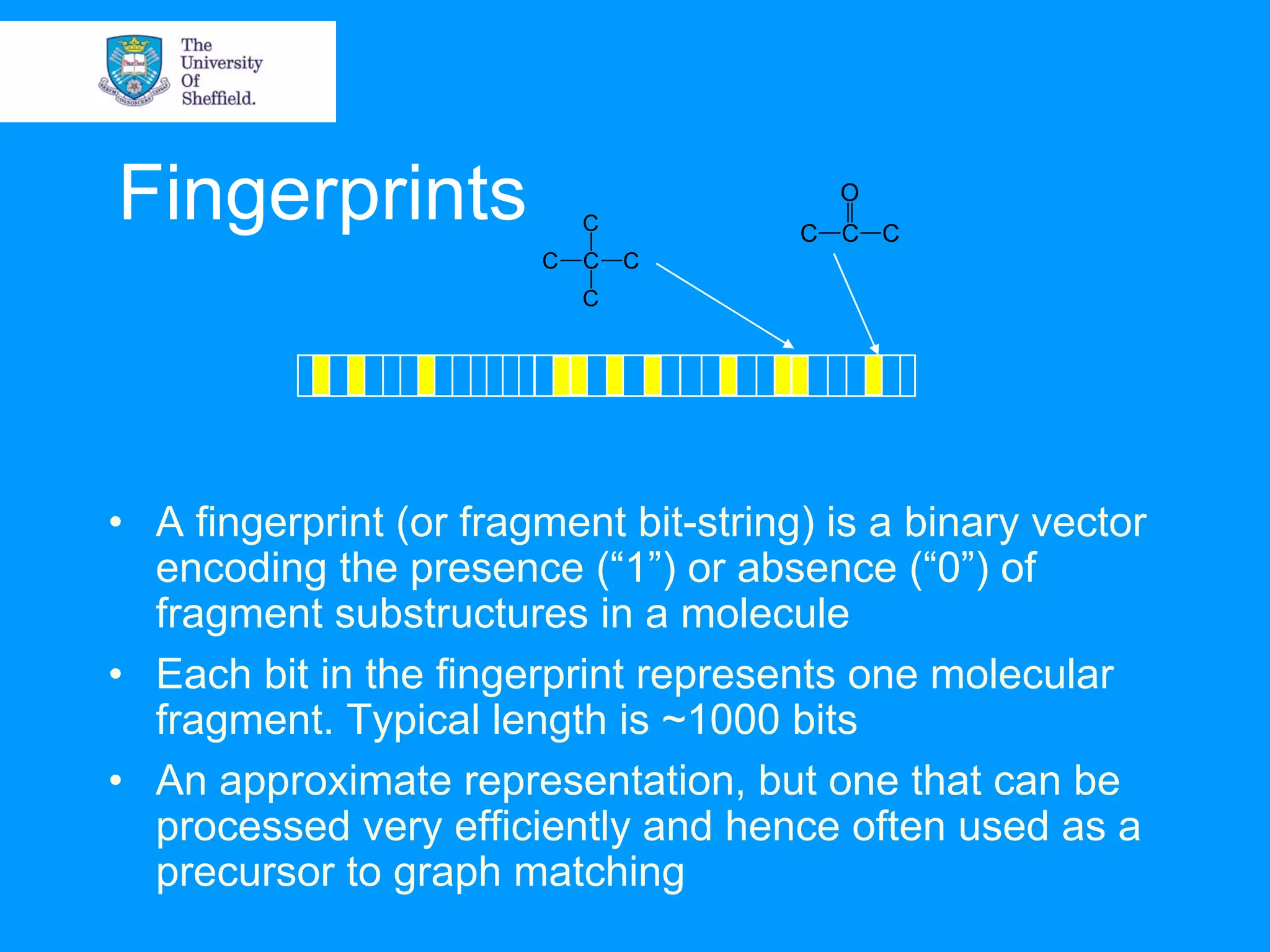

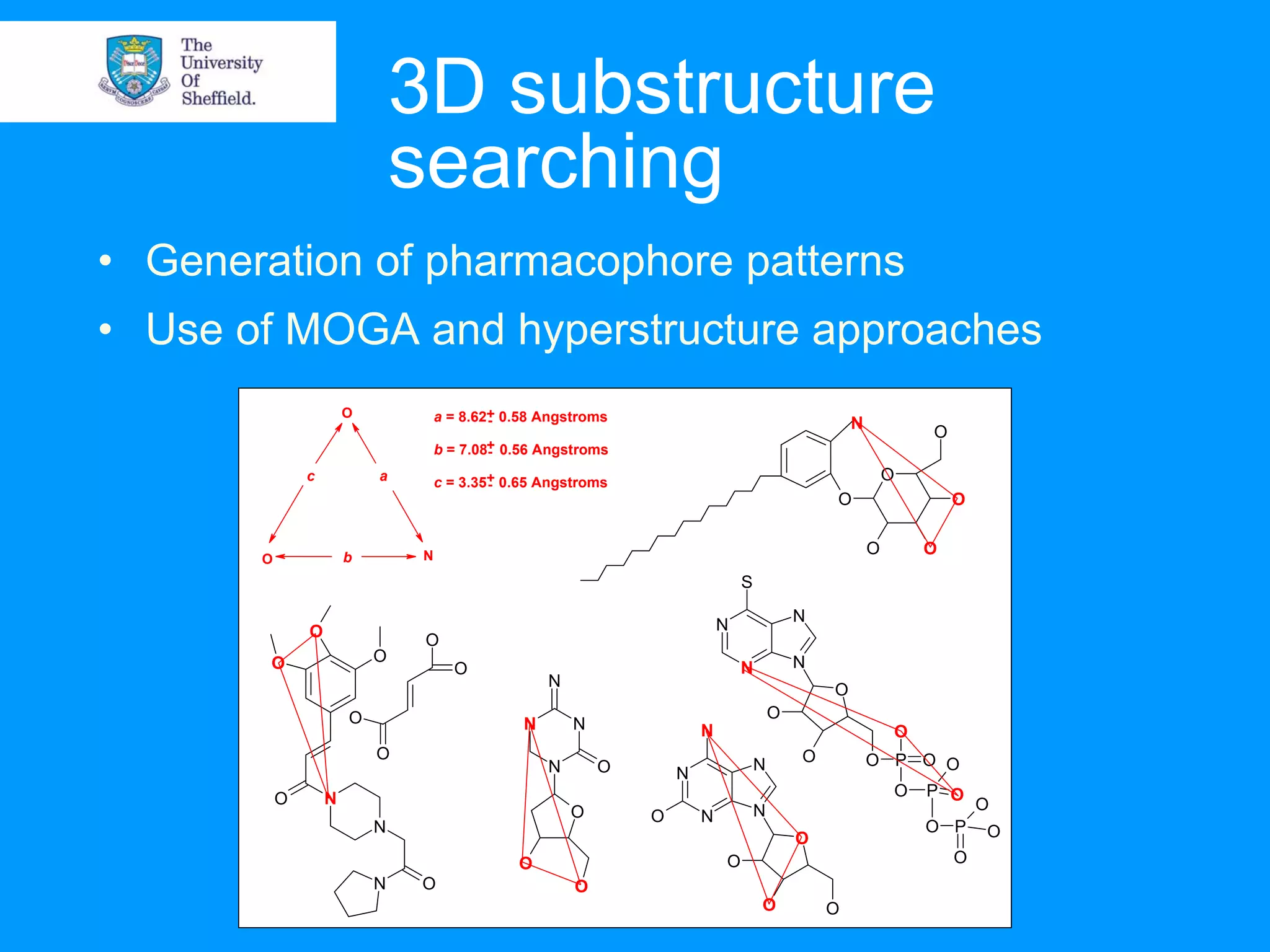




Chemoinformatics involves the management and analysis of chemical structure data to help accelerate the drug discovery process. It uses computer representations of molecules and applies techniques like database searching, fingerprinting, and molecular modeling to efficiently screen large numbers of chemical structures. This helps identify potential drug leads and reject non-drug candidates more quickly compared to traditional sequential drug screening. Key applications of chemoinformatics include structure and substructure searching of databases, molecular similarity analysis and virtual screening to predict molecular properties and activity.
































![1.[1 9]use of 2-{[5-(2-amino-4-oxoquinazolin-3(4 h)-yl)-1,3,4-thiadiazol-2-yl...](https://cdn.slidesharecdn.com/ss_thumbnails/1-1-9useof2-5-2-amino-4-oxoquinazolin-34h-yl-134-thiadiazol-2-ylmethyl-1h-isoindole-132h-dioneinthesynthesisofnovelquinazolinonederivatives-111207105117-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








































