Downloaded 86 times



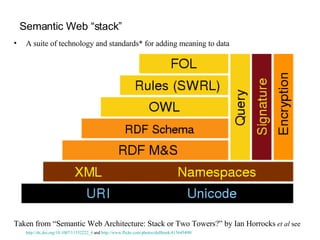




















The document summarizes the use of semantic web standards and ontologies to add meaning and enable discovery of bioinformatics web services. It provides examples using the InterProScan protein domain identifier service, described through standards like XML, RDF and OWL. Registries like BioMOBY and myGrid are discussed that annotate services with ontologies to enable more powerful searches beyond just name or description. Reasoners can also check annotations for consistency and infer new facts to further enhance discovery.
















































































