Downloaded 26 times







![Gene names: e.g. Hexokinase, HK1, HK2, HK3 Protein names: e.g. Hexokinase, HK1, HK2, HK3 Chemical names: e.g. Glucose-6-phosphate, G6P, Glu, Gluc Author names: e.g. Mark Baker (see next slide) Poor precision and recall 21.05.10 Why bury it [data] first and then mine it again? Barend Mons, Wikiproteins http://proteins.wikiprofessional.org Which gene did you mean? BMC Bioinformatics. 2005 Jun 7;6:142 DOI:10.1186/1471-2105-6-142](https://image.slidesharecdn.com/nesc-100521045934-phpapp02/85/Bibliography-2-0-A-citeulike-case-study-from-the-Wellcome-Trust-Genome-Campus-10-320.jpg)
![Identity crisis: Mark Baker http://pubmed.gov?term=Baker+M[author] http://pubmed.gov?term=Mark+Baker[author] etc 21.05.10 Until we have unique author identifiers, it is difficult or impossible to reliably find the papers published by a particular person Open Researcher and Contributor ID http://orcid.org “ Tell me whenever Mark Baker publishes a paper”](https://image.slidesharecdn.com/nesc-100521045934-phpapp02/85/Bibliography-2-0-A-citeulike-case-study-from-the-Wellcome-Trust-Genome-Campus-11-320.jpg)


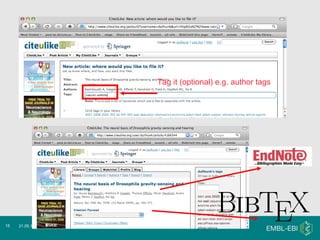
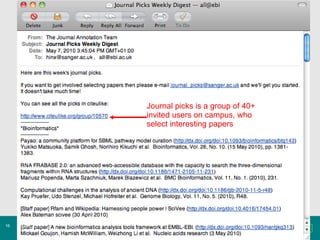
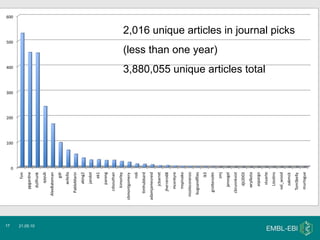
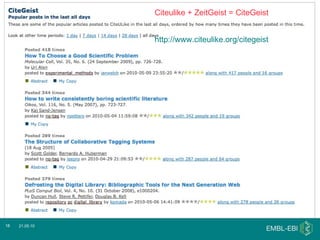







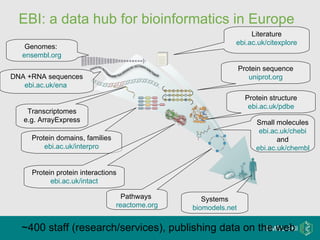
The document discusses Bibliography 2.0, a case study of using the citation management tool Citeulike at the Wellcome Trust Genome Campus. It describes how current publishing incentives encourage "burying" data in publication silos and obscure author identities. Citeulike provides a solution by allowing users to organize citations, see what others are reading, and increase visibility of their work. However, adoption faces barriers from privacy concerns, fragility of tools, and lack of academic rewards for participation.






















































































