Download to read offline





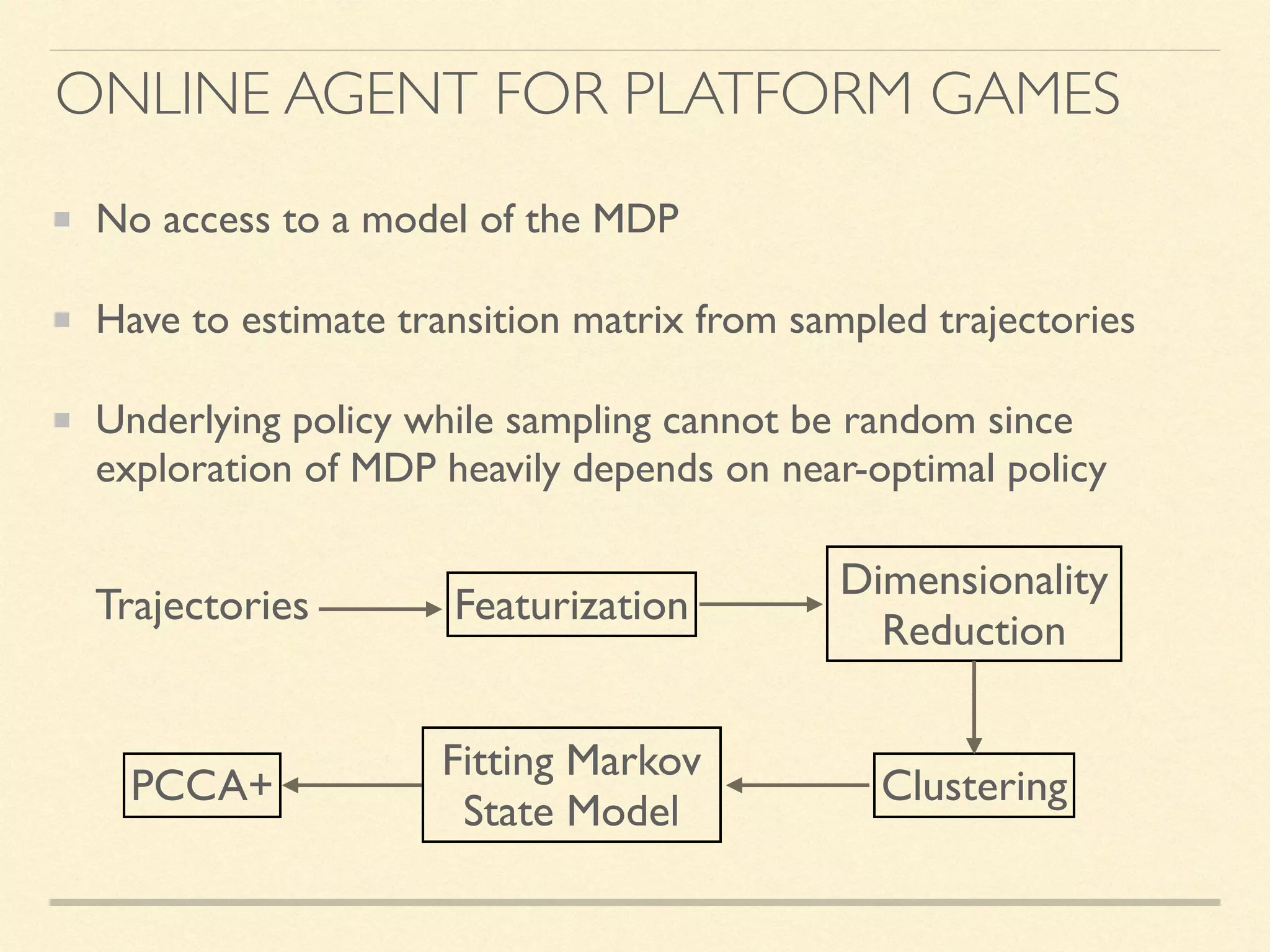



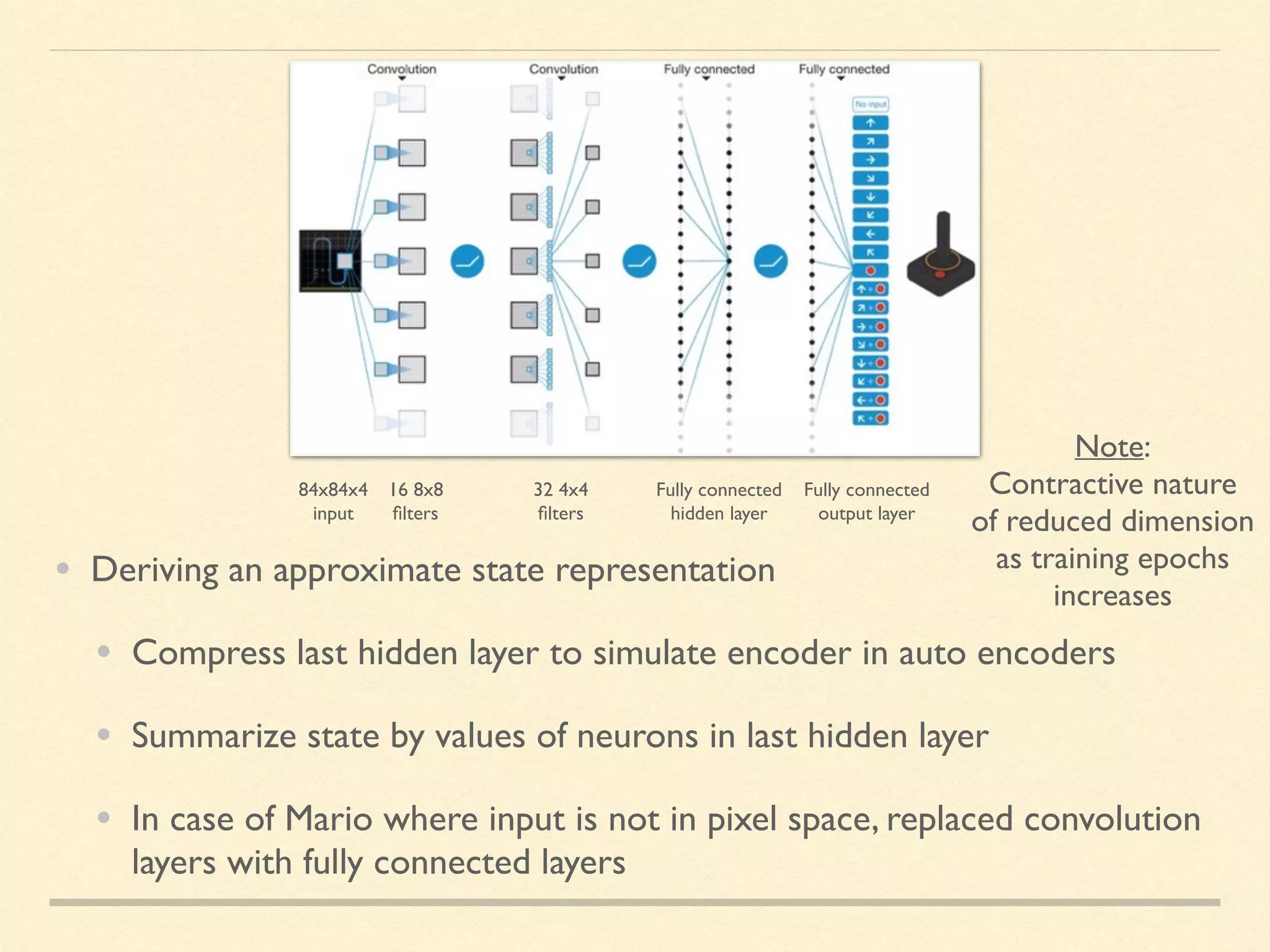
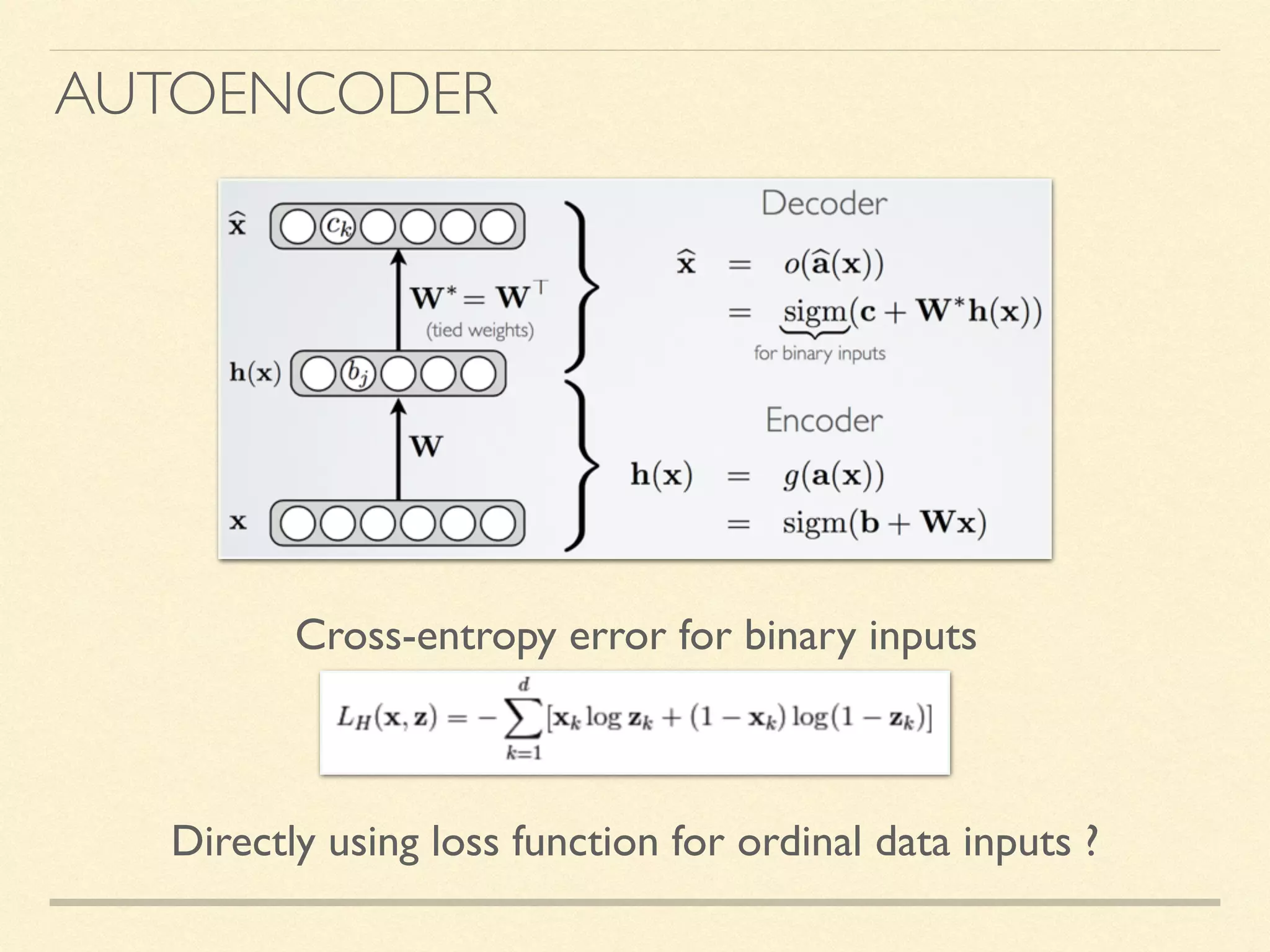

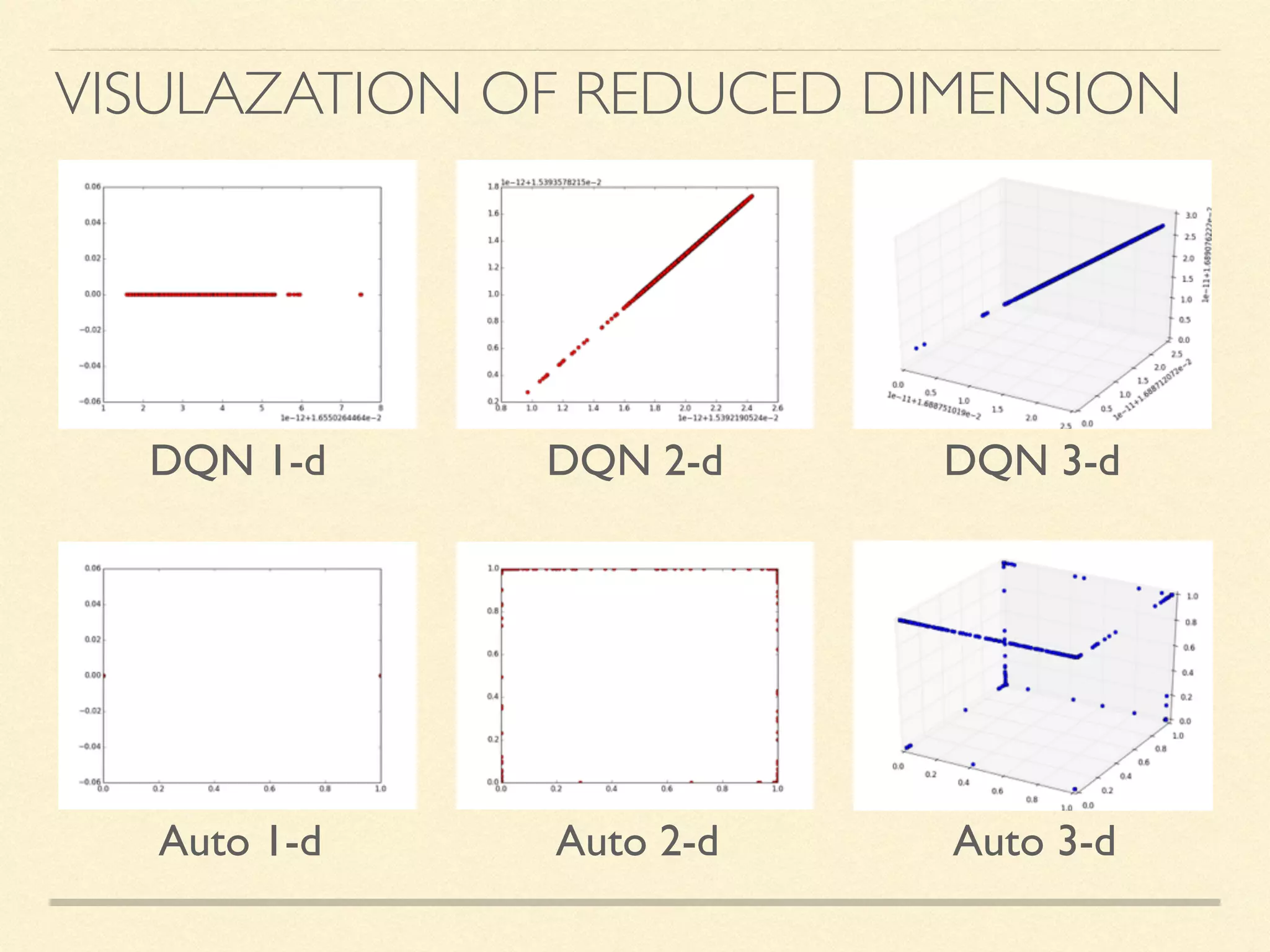
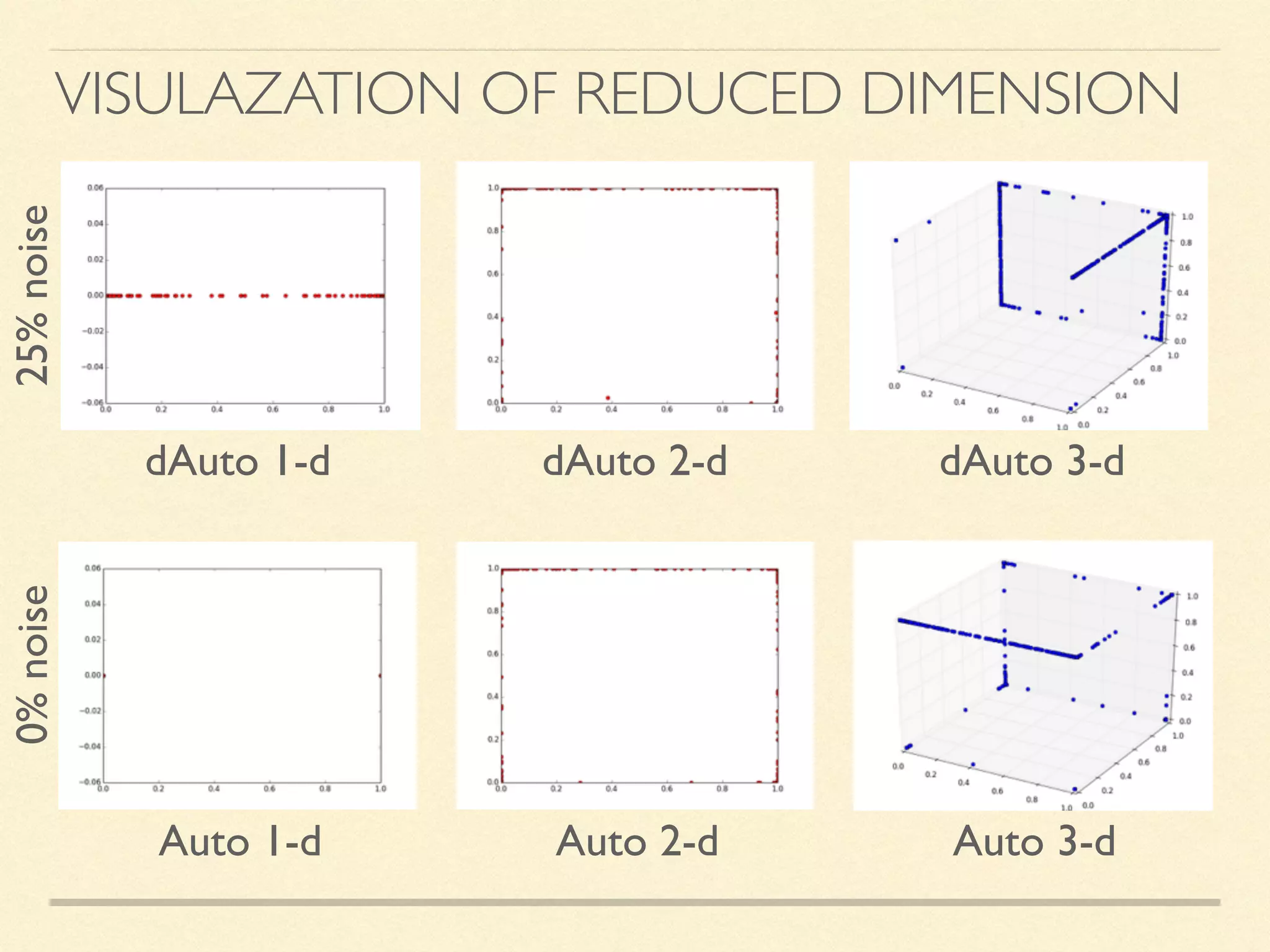
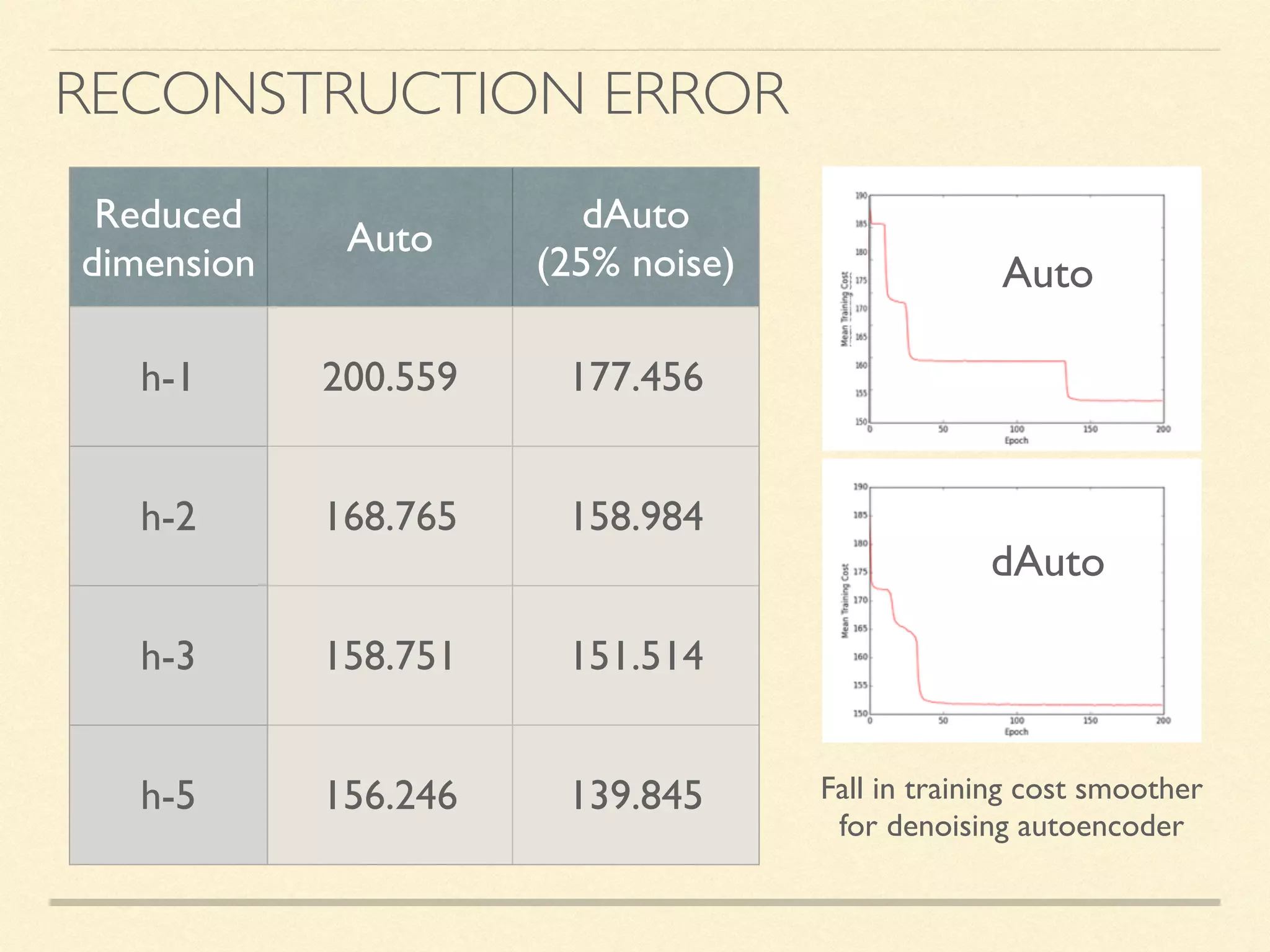
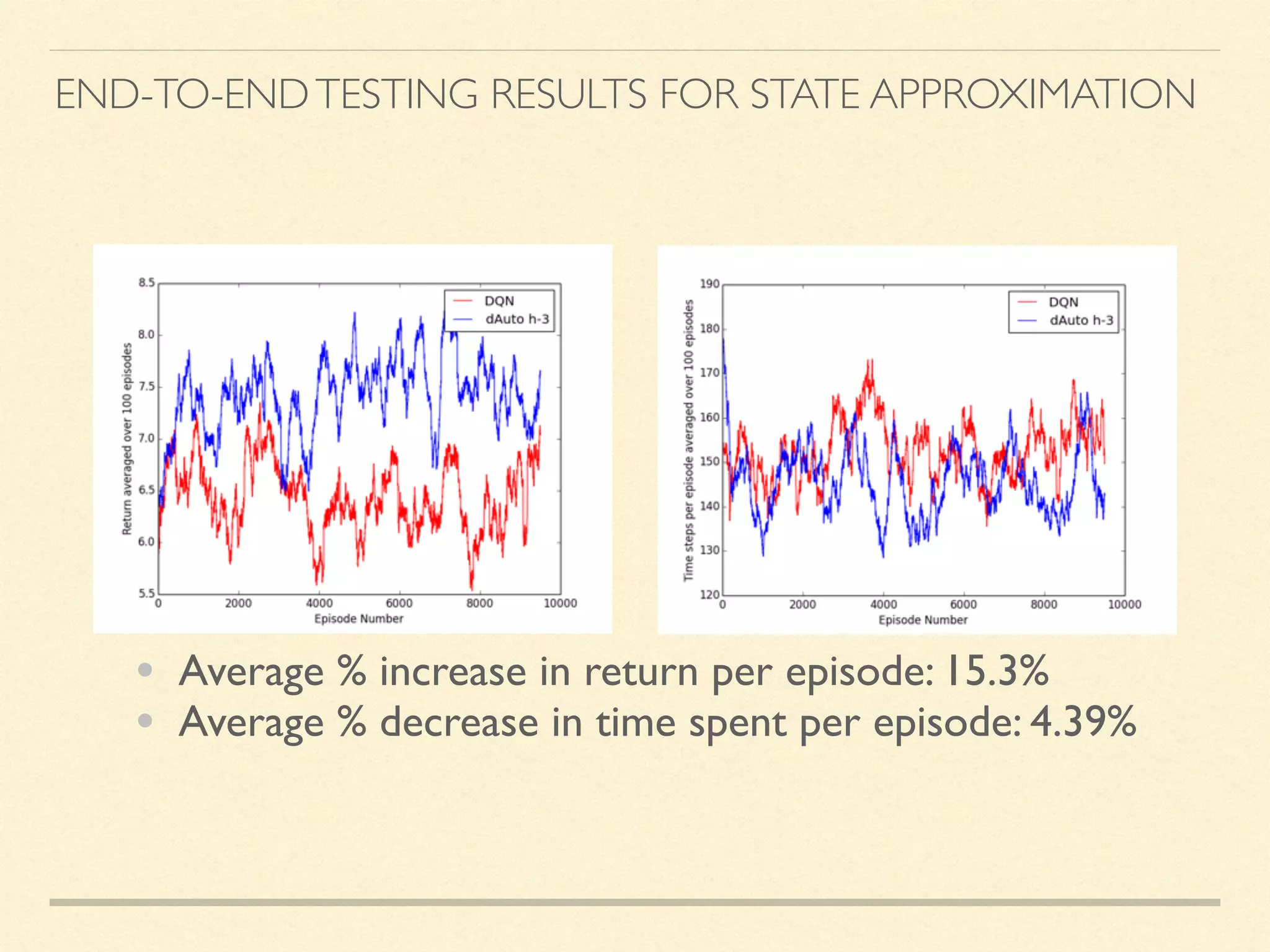



The document discusses hierarchical decision making in platform games using spatio-temporal abstraction and representation learning, emphasizing spatial and temporal abstractions to simplify state approximation. Techniques such as spectral clustering and deep Q-networks for dimensionality reduction are applied, particularly in environments with high state spaces like Mario and Montezuma's Revenge. The results indicate improved performance and efficiency in approximating states through methods like denoising autoencoders across various game scenarios.























































































