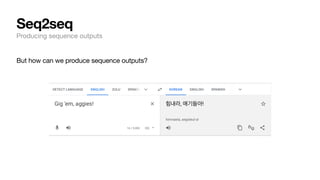
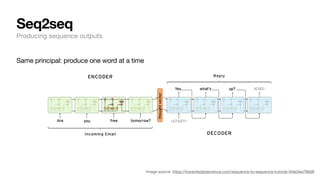
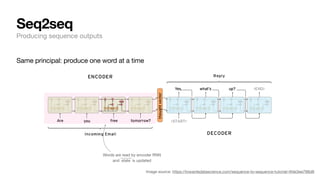
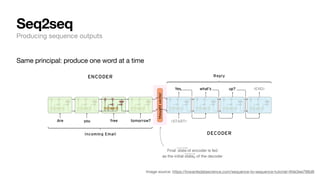
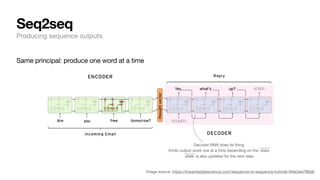
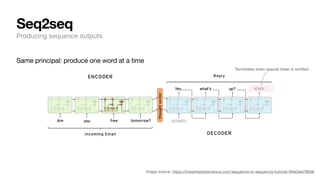
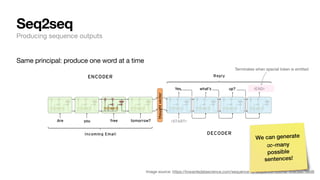
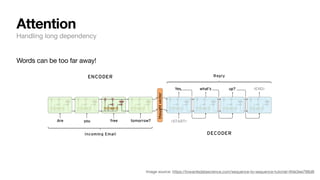
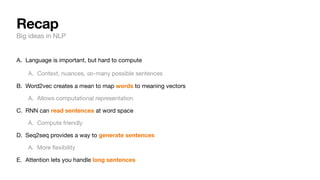
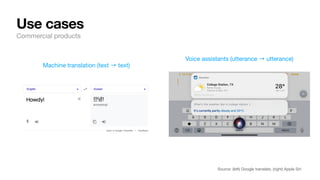
The document discusses key concepts and techniques in Natural Language Processing (NLP), including word2vec, recurrent neural networks, and the sequence-to-sequence framework for language understanding and generation. It highlights the importance of deep learning in understanding and processing human language, as well as advancements like attention mechanisms that improve model performance on complex language tasks. Additionally, it touches on the relevance of these advancements in various applications such as machine translation and voice assistants.
















![Word2Vec
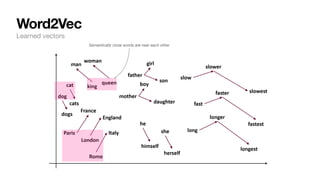
Language representation in computers
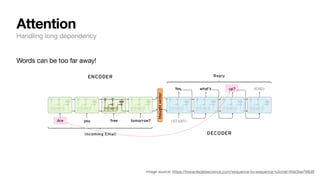
Words are represented as vectors of numbers in NLP. How?
1. Words are associated with random vectors:
2. We go through many sentences and learn that predicts prev/next word probability correctly.
θ
Example from: https://web.stanford.edu/class/cs224n/slides/cs224n-2022-lecture01-wordvecs1.pdf
brown = [+0.3, − 0.4, + 0.2, − 0.3,...]T
fox = [−0.2, − 0.1, − 0.1, + 0.3,...]T](https://image.slidesharecdn.com/csce181nlpseminarsophomores-221116023352-130f74e5/85/CSCE181-Big-ideas-in-NLP-23-320.jpg)
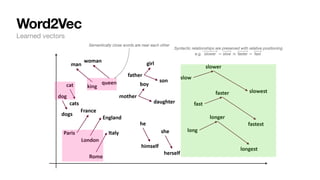
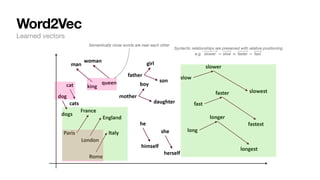
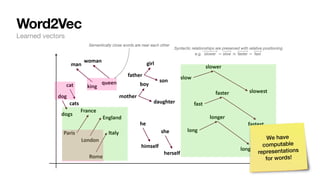
![Word2Vec
Example from: https://web.stanford.edu/class/cs224n/slides/cs224n-2022-lecture01-wordvecs1.pdf
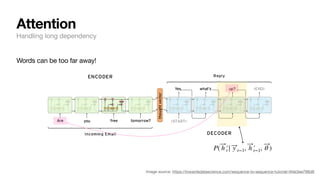
Words are represented as vectors of numbers in NLP. How?
1. Words are associated with random vectors:
2. We go through many sentences and learn that predicts prev/next word probability correctly.
3. The result?
• Word vectors populated in n-d space that holds semantic/syntactic meaning
θ
brown = [+0.3, − 0.4, + 0.2, − 0.3,...]T
fox = [−0.2, − 0.1, − 0.1, + 0.3,...]T
Language representation in computers](https://image.slidesharecdn.com/csce181nlpseminarsophomores-221116023352-130f74e5/85/CSCE181-Big-ideas-in-NLP-24-320.jpg)


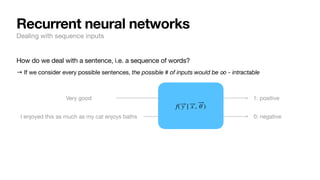
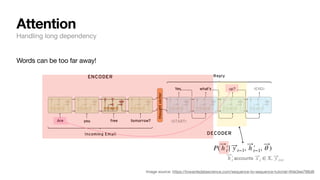
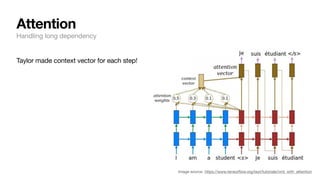
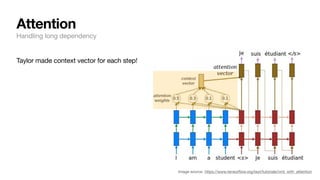
![How do we deal with a sentence, i.e. a sequence of words?
→ Break it down to word level: then the possible # of words wouldn’t be that many (~30K) - tractable!
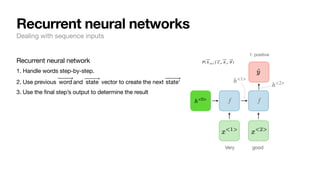
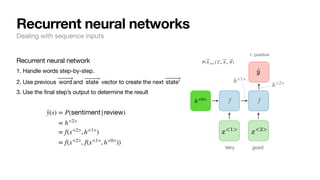
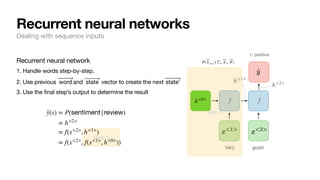
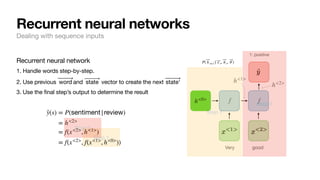
Recurrent neural networks
Dealing with sequence inputs
[“Very”, “good”] 1: positive
[“I”, “enjoyed”, “this”, “as”, “much”, “as”, “my”,
“cat”, “enjoys”, “baths”]
0: negative
f( ⃗
y | ⃗
x , ⃗
θ )](https://image.slidesharecdn.com/csce181nlpseminarsophomores-221116023352-130f74e5/85/CSCE181-Big-ideas-in-NLP-32-320.jpg)