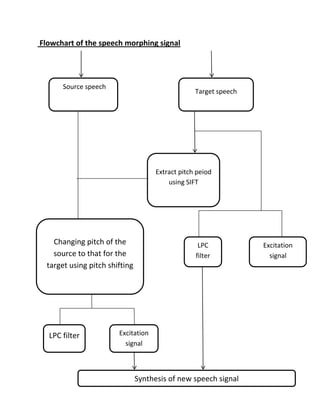
Voice morphing is a technique that modifies a source speaker's speech to sound like it was spoken by a target speaker. It works by analyzing the source speech into an excitation signal and filter components, then resynthesizing it with the pitch and vocal characteristics of the target speaker. The key steps are detecting the pitches of the source and target speakers, scaling the source pitch to match the target, then resynthesizing the source speech using the target's vocal filter characteristics and the pitch-scaled excitation signal. Voice morphing was developed in 1999 and has applications in text-to-speech, dubbing, voice disguising, and public announcement systems.