Downloaded 125 times





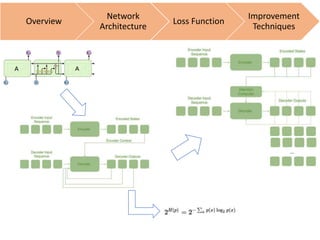

![Cross Entropy Loss:
Cross-Entropy:
Cross-Entropy for a sentence w1, w2, …, wn:
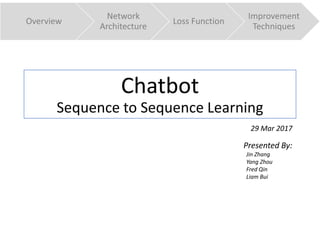
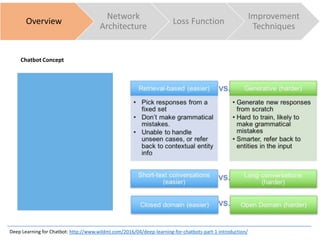
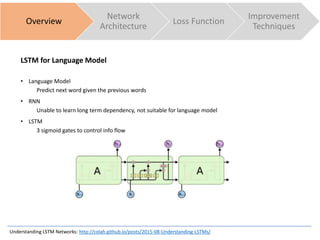
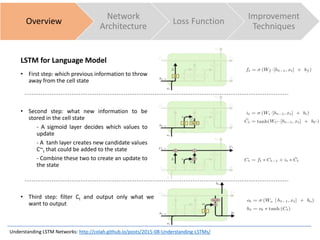
Overview
Network
Architecture
Loss Function
Improvement
Techniques
= −𝑙𝑜𝑔2 𝑚(𝑥∗
)
= − 𝑙𝑜𝑔2 𝑚(𝑤1
∗
, … , 𝑤 𝑛
∗
)
= − [𝑙𝑜𝑔2 𝑚 𝑤 𝑛
∗
|𝑤1
∗
, … , 𝑤 𝑛−1
∗
+ 𝑙𝑜𝑔2 𝑚 𝑤 𝑛−1
∗
|𝑤1
∗
, … , 𝑤 𝑛−2
∗
+ … + 𝑙𝑜𝑔2 𝑚 𝑤1
∗
]
sum of log-probability in decoding steps](https://image.slidesharecdn.com/deeplearning-chatbot-170329230448/85/Deep-learning-Chatbot-17-320.jpg)


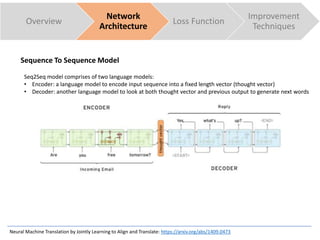
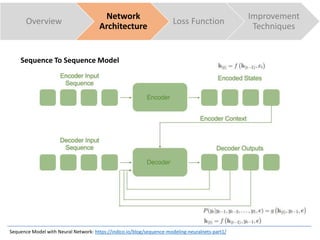
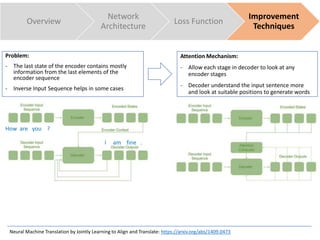
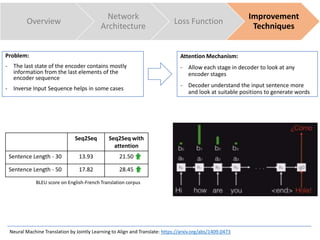
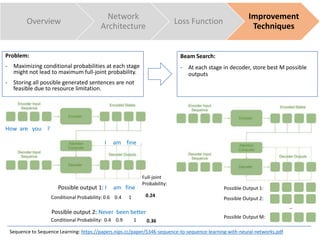
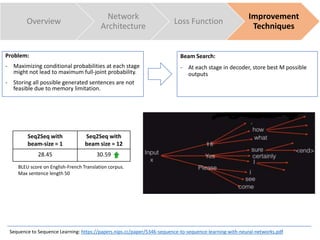
The document discusses sequence to sequence learning for chatbots. It provides an overview of the network architecture, including encoding the input sequence and decoding the output sequence. LSTM is used to model language. The loss function is cross entropy loss. Improvement techniques discussed include attention mechanism to focus on relevant parts of the input, and beam search to find higher probability full sequences during decoding.






















![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [YouPlace 팀] : 카프카와 스파크를 활용한 유튜브 영상 속 제주 명소 검색](https://cdn.slidesharecdn.com/ss_thumbnails/10youplace-220124105901-thumbnail.jpg?width=640&height=640&fit=bounds)































































