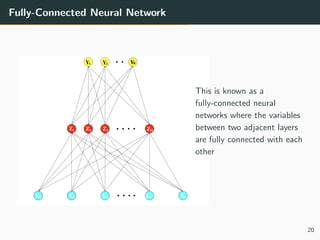
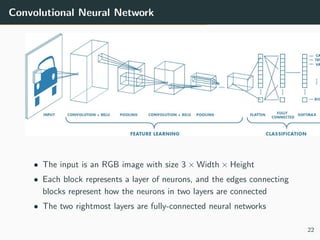
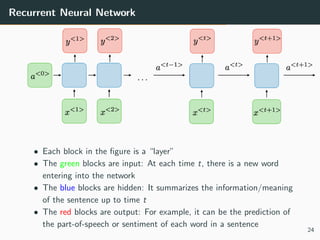
The document provides a comprehensive overview of neural networks, detailing their origins, architectures, and applications in machine learning, particularly focusing on deep learning and generative adversarial networks (GANs). Key topics include the structure of neural networks, the learning process through backpropagation and optimization algorithms, and the variations in activation functions. It also introduces advanced models like convolutional and recurrent neural networks, highlighting their unique characteristics and contributions to deep learning.




![Neural Networks: Model (Single Hidden Layer)
Figure 11.2 from ESL:
Schematic of a single hidden
layer, feed-forward neural
network.
Input: (X1, ..., Xp) ∈ Rp
Output:
(Y1, ..., YK ) ∈ [0, 1]K
, the
probability of the sample’s
label being k = 1, ..., K
Hidden layer:
(Z1, ..., ZM ) ∈ RM
4](https://image.slidesharecdn.com/m7-neuralnetwork-240403115856-4569c993/85/M7-Neural-Networks-in-machine-learning-pdf-4-320.jpg)








































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
