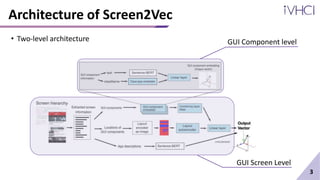
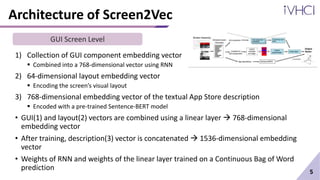
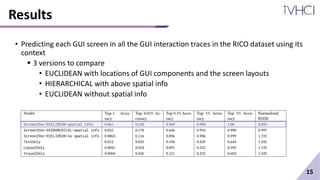
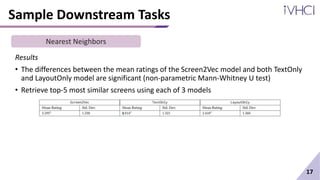
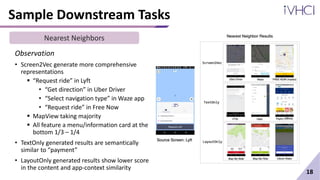
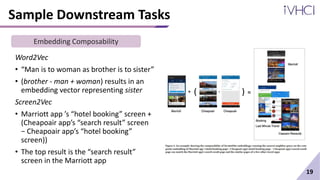
This document presents Screen2Vec, a technique for generating semantic embeddings of GUI screens and components using text, visual design, layout patterns, and app metadata. It has a two-level architecture that learns embeddings at the component and screen levels. The technique is self-supervised and does not require labeled data. It was trained on the RICO dataset and can be used for tasks like nearest neighbor retrieval and representing mobile tasks. Sample results showed Screen2Vec generated more comprehensive representations compared to baselines using only text or layout.

























![[NS][Lab_Seminar_250407]AlignmentLearning.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250407alignmentlearning-250407124309-1acb59f1-thumbnail.jpg?width=640&height=640&fit=bounds)














































