Download as PDF, PPTX















































![37
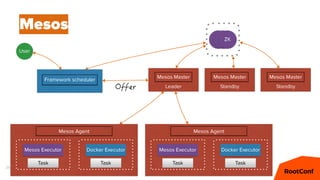
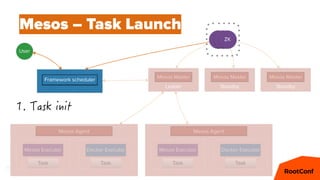
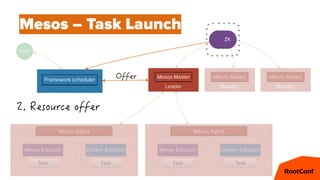
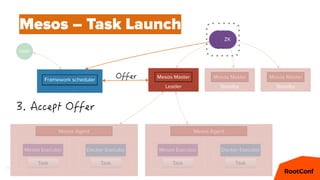
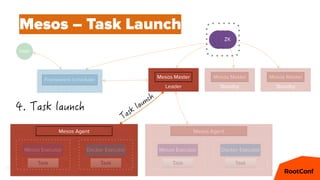
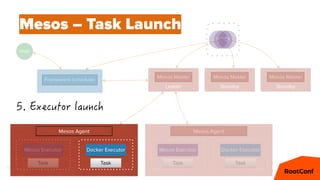
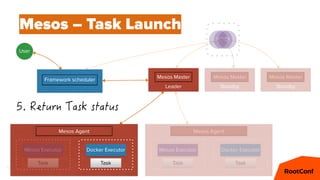
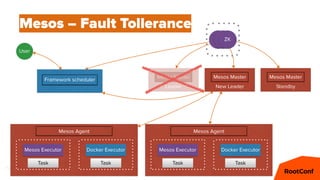
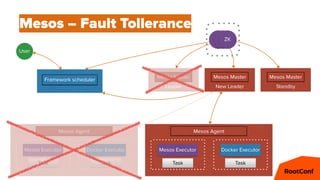
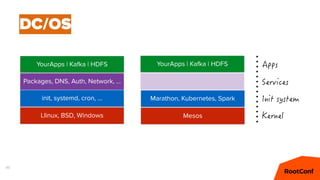
Mesos – Offers
cpus(fast):4; mem(fast):4096; ports(fast):[1025-7000]
cpus(*):16; mem(*):8192; ports(*):[1025-65535]
cpus(*):8; mem(*):32768; ports(*):[1025-65535]](https://image.slidesharecdn.com/dcospaasexpress42-160607201143/85/DC-OS-PAAS-Express-42-59-320.jpg)











![57
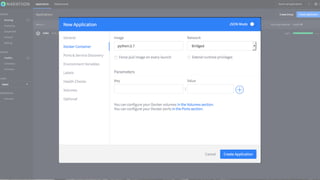
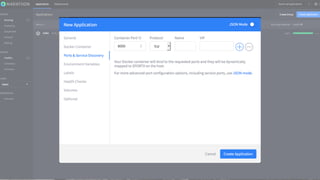
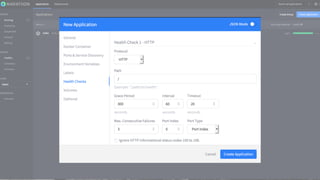
Marathon – your-app.json
............
"healthChecks": [{
"gracePeriodSeconds": 60,
"intervalSeconds": 10,
"maxConsecutiveFailures": 3,
"path": "/",
"portIndex": 0,
"protocol": "HTTP",
"timeoutSeconds": 10
}]
............](https://image.slidesharecdn.com/dcospaasexpress42-160607201143/85/DC-OS-PAAS-Express-42-87-320.jpg)
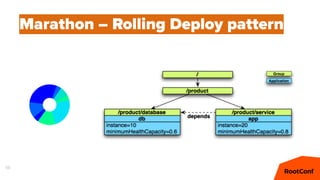






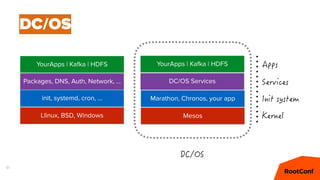

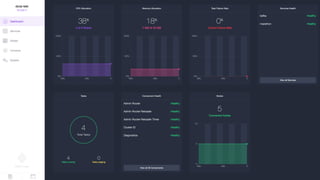
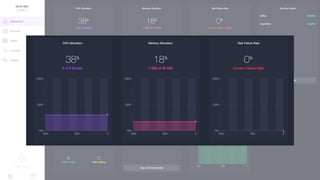
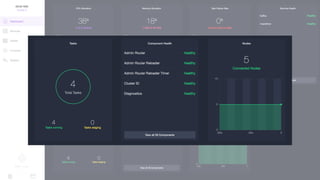
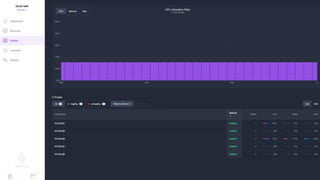
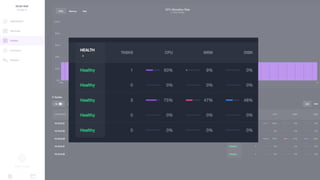


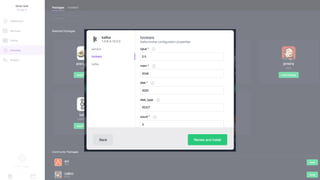























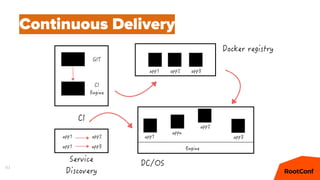









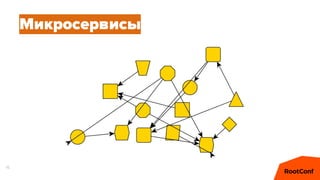
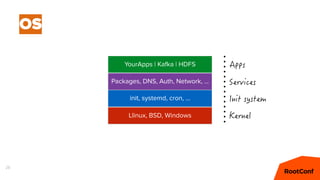
Документ представляет собой анализ концепции Data Center Operating System (DC/OS), описывая его компоненты, преимущества и внедрение в микросервисной архитектуре. Обсуждаются проблемы управления ресурсами и конфигурацией, а также предлагаются решения с использованием технологий, таких как Docker и Mesos. В заключение упоминаются примеры компаний, которые используют DC/OS, и ссылка на различные ресурсы для дальнейшего изучения.























































































