Downloaded 12 times




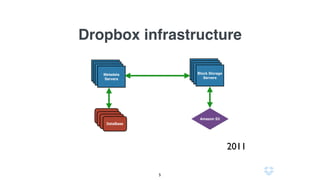
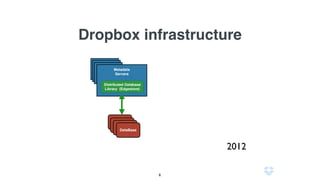
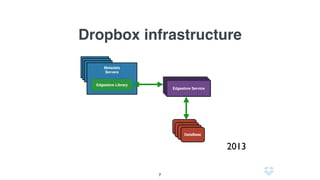
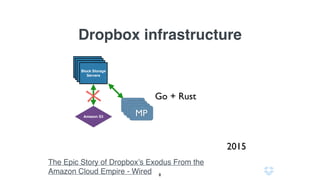





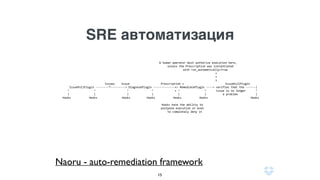







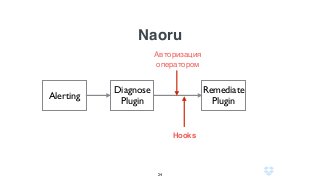

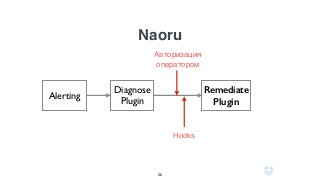

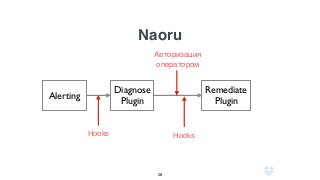















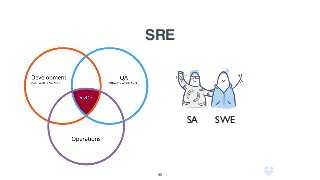

Документ описывает использование языка программирования Go в роли инженера по надежности сайта в компании Dropbox, включая информацию о системе инфраструктуры и процессах автоматизации. Обсуждаются также преимущества использования Go по сравнению с другими языками программирования и его интеграцией в различные сервисы. Кроме того, документ подчеркивает важность мониторинга, диагностики и автоматизации на уровне SRE.




























































