Download to read offline




























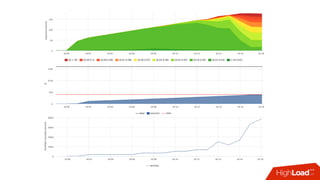
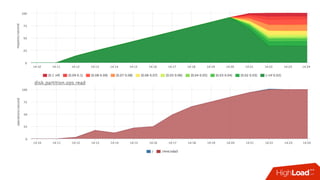
![Стабильность с квотами
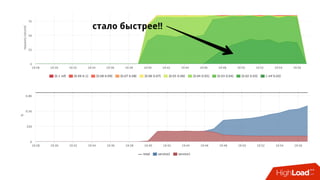
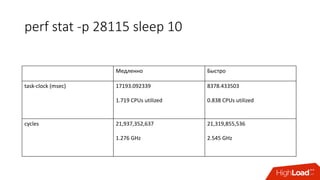
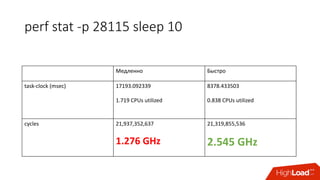
• Знаем предел производительности сервиса при квоте
• Можем посчитать в % утилизацию cpu сервисом:
• Факт: /sys/fs/cgroup/cpu/docker/<id>/cpuacct.usage
• Лимит: period/quota
• Триггер: [service1] cpu usage > 90%
• Если уперлись в quota — растёт nr_throttled и throttled_time из
• /sys/fs/cgroup/cpu/docker/<id>/cpu.stat](https://image.slidesharecdn.com/1-171113151259/85/container-based-okmeter-io-37-320.jpg)

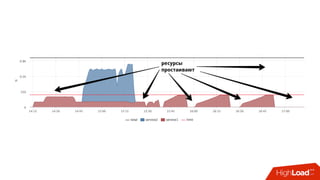


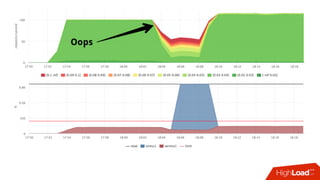




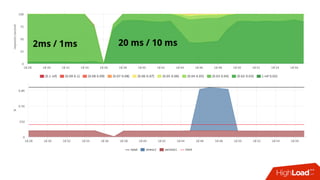






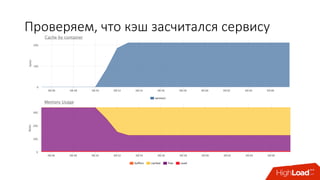

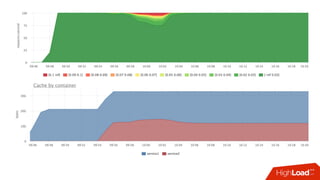

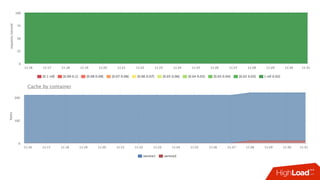




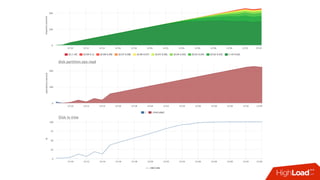

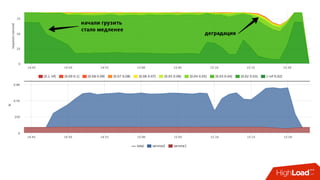
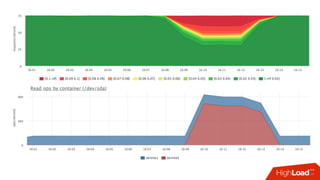
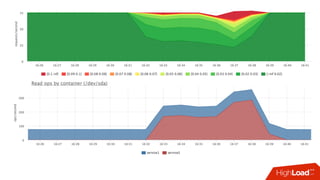
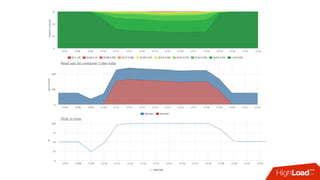
![Мониторинг
• Знаем лимит каждой cgroup для каждого device
• Можем снять факт из
• /sys/fs/cgroup/blkio/<id>/blkio.throttle.io_serviced
• Триггер вида:
• [service1] /dev/sda read iops > 90%](https://image.slidesharecdn.com/1-171113151259/85/container-based-okmeter-io-66-320.jpg)














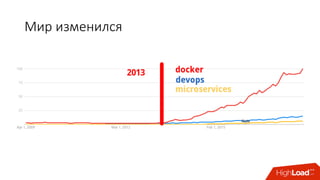
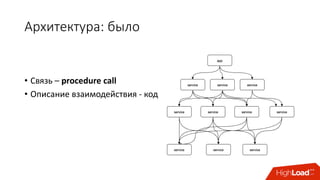
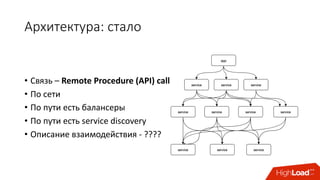
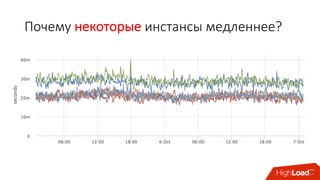
Документ обсуждает переход от монолитной архитектуры приложений к микросервисной, подчеркивая преимущества использования контейнеров и инструментов, таких как Docker и Kubernetes. Обсуждаются вызовы управления зависимостями, масштабирования и распределения ресурсов, а также использование cgroups для ограничения ресурсов, что позволяет оптимизировать производительность сервисов. В итоге подчеркивается важность правильной настройки и управления архитектурой для обеспечения стабильности и эффективности в облачной инфраструктуре.












































































