Downloaded 18 times


























![29
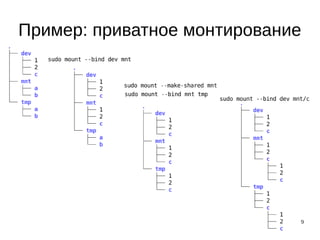
Перемещение процессов в группу
● cgclassify
-g список подсистем (контроллеров):путь
PID [PID PID …]
Примеры:
$cgclassify -g cpu:/mycgroup 6433 3662
$echo 6433 >/sys/fs/cgroup/cpu/mucgroup/tasks](https://image.slidesharecdn.com/linuxvirt-seminar-csc-2015-150606124017-lva1-app6892/85/Linuxvirt-seminar-csc-2015-29-320.jpg)










![40
Контроллер memory
● Назначение: управление и мониторинг использования памяти
←memory.stat – получение статистики по использованию памяти
– total_ – текущая группа и подгруппы
←memory.[memsw.]usage_in_bytes – используемая память в байтах
(в подкачке)
←/→memory.[memsw.]limit_in_bytes
←memory.[memsw.].failcnt – счетчик числа достижений лимита
памяти
←/→memory.oom_control — флаг разрешения OOM-killer
(*) ←/→memory.soft_limit_in_bytes — флаг разрешения OOM-killer
см https://www.kernel.org/doc/Documentation/cgroups/memory.txt](https://image.slidesharecdn.com/linuxvirt-seminar-csc-2015-150606124017-lva1-app6892/85/Linuxvirt-seminar-csc-2015-40-320.jpg)
![41
Контроллер blkio
● → blkio.weight – [100-1000], относительный вес ввода вывода в
группе
● → blkio.weight – [100-1000], относительный вес ввода вывода в
группе для конкретного устройства
● ← blkio.time – время доступа ввода-вывода в группе
● ← blkio.sectors – количество перемещенных между устройствами
секторов в группе
● ← blkio.io_service_bytes – количество перемещенных между
устройствами байт в группе
● ← blkio.io_service_time – время между выдачей запроса и его
завершением
● ← blkio.io_queued – число запросов в очереди ввода вывода группы](https://image.slidesharecdn.com/linuxvirt-seminar-csc-2015-150606124017-lva1-app6892/85/Linuxvirt-seminar-csc-2015-41-320.jpg)










Документ обсуждает основы контейнерной виртуализации в Linux, включая механизмы изоляции, такие как пространства имен (namespaces) и контрольные группы (cgroups). Он рассматривает различные типы пространств имен, такие как PID, UTS, IPC и сетевые пространства, а также их применение и создание. Документ также затрагивает управление ресурсами с помощью контрольных групп, включая способы их создания, изменения и контроля за использованием системных ресурсов.


![Обзор архитектуры [файловой] системы Ceph](https://cdn.slidesharecdn.com/ss_thumbnails/ceph-150618110935-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[MDBCI] Mariadb continuous integration tool](https://cdn.slidesharecdn.com/ss_thumbnails/cee-secr-2015-mariadb-151028083632-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










































