Downloaded 11 times






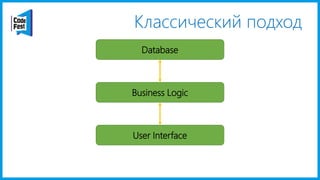
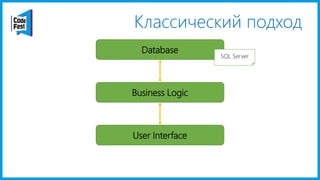
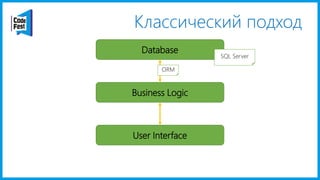
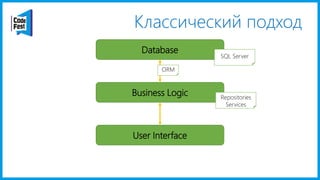
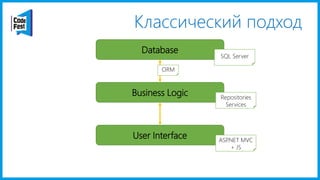
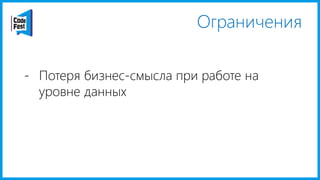





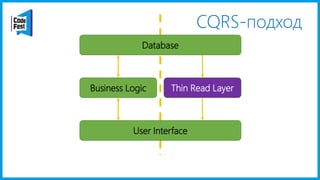

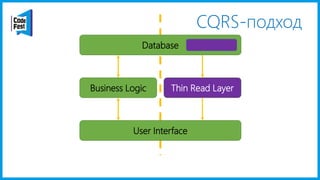
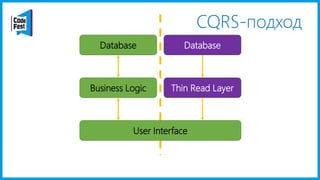
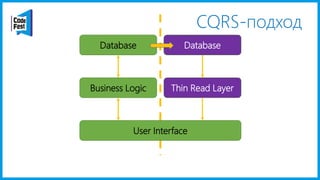
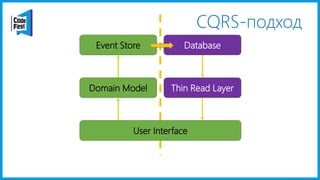

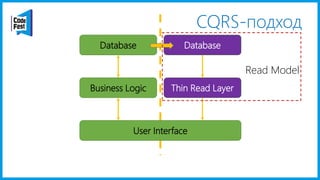
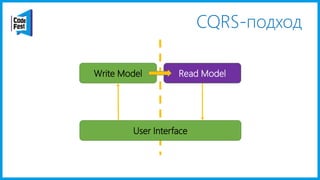
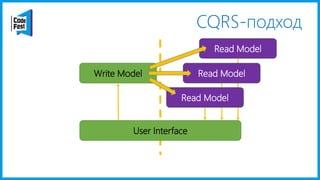
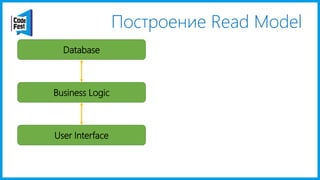
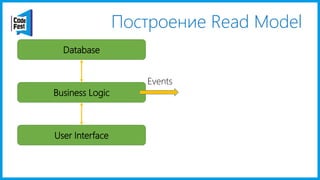

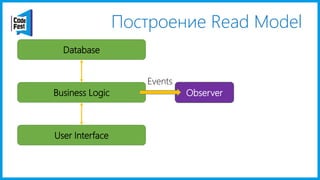

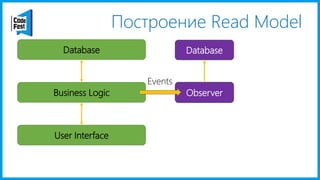

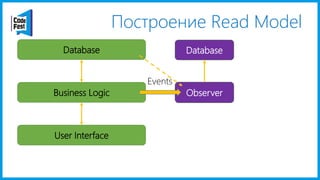
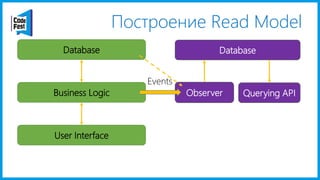
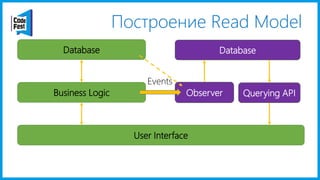

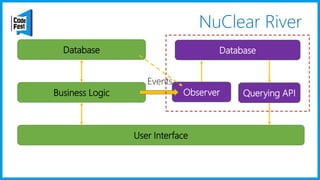
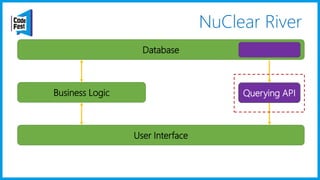




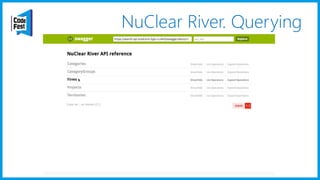
























Документ обсуждает создание моделей чтения с использованием потоков событий и различных бизнес-доменов, включая сотрудников и продажи. Рассматриваются ограничения классического подхода и преимущества подхода CQRS, включая использование системы Nuclear River для повышения согласованности и производительности. Автор подчеркивает важность выбора правильного решения на основе бизнес-кейсов и контекстов.











































































