Download to read offline








![1. {
2. "id": "bridged-webapp",
3. "cmd": "python3 -m http.server 8080",
4. "cpus": 0.5,
5. "mem": 64.0,
6. "instances": 2,
7. "container": {
8. "type": "DOCKER",
9. "docker": {
10. "image": "python:3",
11. "network": "BRIDGE",
12. "portMappings": [
13. { "containerPort": 8080, "hostPort": 0, "servicePort": 9000, "protocol": "tcp" },
14. { "containerPort": 161, "hostPort": 0, "protocol": "udp"}
15. ]
16. }
17. },
18. "healthChecks": [
19. {
20. "protocol": "HTTP",
21. "portIndex": 0,
22. "path": "/",
23. "gracePeriodSeconds": 5,
24. "intervalSeconds": 20,
25. "maxConsecutiveFailures": 3
26. }
27. ]
28. }](https://image.slidesharecdn.com/scalingserviceswithapachemesosanddocker-151007040850-lva1-app6891/85/Scaling-services-with-apache-mesos-and-docker-11-320.jpg)



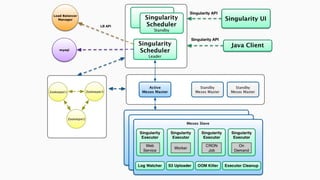


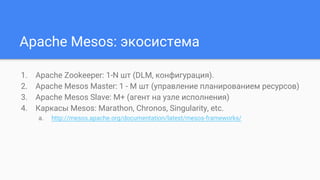
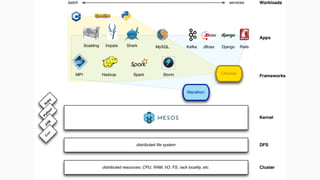
Документ описывает использование Apache Mesos для масштабирования сервисов и управления ресурсами, включая интеграцию с фреймворками Marathon и Chronos. Он рассматривает проблемы управления инфраструктурой, методы виртуализации, а также архитектуру микросервисов. В заключение упоминается новый фреймворк Singularity от HubSpot, который объединяет функционал Marathon и Chronos.















































