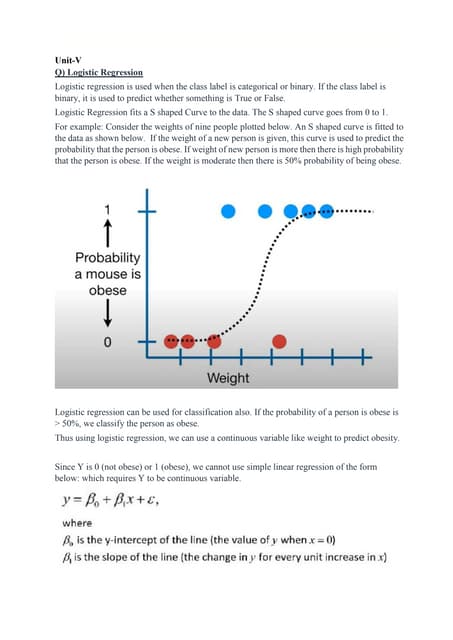
The document provides a comprehensive overview of database systems, covering foundational concepts such as data, information, databases, and database management systems (DBMS). It discusses the organization of data in databases, the limitations of file processing systems, and the advantages of using DBMS, including improved data sharing, security, integration, and decision-making. Additionally, it explores data modeling, various data models like hierarchical, network, relational, and object-oriented, as well as the roles of users and components within a database environment.


















![UNIT-III
Chapter-I Introduction to SQL
Q:What is SQL and What does SQL do?
SQL stands for structured query language.
SQL is non-procedural language, therefore you specify what is to be done rather than how is
it done.
American National Standards Institute (ANSI) prescribed a standard SQL.
SQL functions fits into two broad categories:
• It is a data definition language:(DDL):-SQL can create databse objects such as
tables,indexes and views.SQL can also define access rights to these database objects.
• It is a data manipulation language(DML):-SQL can be used to insert,update,delete
and retrieve data from the database
SQL is easy to learn
SQL can retrieve data from database
SQL can execute queries
SQL queries are used to answer question and also to perform actions such as adding,deleting
table rows.
Q:Explain various datatypes available in SQL?
AnsThe following table shows some common SQL datatypes
Datatype Format Comments
Numeric NUMBER(L,D) Ex: NUMBER(7,2) indicates number will be stored with two
decimal places and may be upto 7 digits long,including the
sign and decimal places.
INTEGER (OR)
INT Cannot be used if you want to store numbers that require
decimal places.
SMALLINT Limited to integer values upto six digits
DECIMAL(L,D) Greater lengths are acceptable, but smaller ones are not.
Character CHAR(L) Fixed length character data for upto 255 characters. If you
store strings that are not as long as the CHAR parameter
value,the remaining spaces are left unused
VARCHAR(L)
OR
VARCHAR2(L) Variable length character data will not leave unused spaces.
Date DATE
Stores dates in the julian date format.
Q: Explain how to create table using SQL?
Ans: The CREATE table is used to create a new table in the user database schema.
Syntax:
CREATE TABLE tablename (
Column1 datatype(column width) [constraints],
Column2 datatype(column width) [constraints],
……………
);
Page 23](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-23-320.jpg)

![Q:Explain important data manipulation commands (DML) of SQL?
Ans:
INSERT: Used to enter data into a table.
Syntax:
INSERT INTO tablename VALUES (value1,value2,…..valuen)
Example:
INSERT INTO VENDOR VALUES (100,’RADHA’,’VJA’);
Observe that:
Character and date values must be entered between apostrophes(‘).
Numerical entries are not enclosed in apostrophes(‘).
Attribute entries are separated by commas.
Inserting Rows with NULL attribute
INSERT INTO product VALUES (‘P02’,’PENCIL’,’02-AUG-2011’, 25, 3, NULL);
Note that the NULL entry is accepted only because the vno attribute is optional in
PRODUCT table.
The NOT NULL declaration is not used in the CREATE TAVLE statement for these
attributes.
Inserting Rows with OPTIONAL attributes:
If the data is not available for all columns, then column list must be included following table
name.
INSERT INTO product(pno,pdesc) VALUES(‘P03’,’MOUSE’)
COPYING PARTS OF A TABLE
To create a new table based on selected column and rows of an existing table. In this
case, the new table will copy the attribute names,data characteristics and rows of
original table.
CREATE TABLE part AS
SELECT pno,pdesc,vno FROM product;
Note that no entity integrity(primary key) or referential integrity (foreign key) rules are
automatically applied to the new table.
Saving the table changes or COMMIT:
The COMMIT command permanently saves all changes such as rows added, attributes
modified and rows deleted made to any table in the database.
Syntax:
COMMIT;
Any changes made to table contents are not saved on disk until you close the database, close
the program you are using, or use the COMMIT command.
UPDATE Command:
The UPDATE command modifies an attribute value in one or more table rows.
Allows you to make data entries in an existing row’s columns.
Syntax:
UPDATE tablename
SET columnname = expression [,columnname = expression]
WHERE conditionlist;
Ex:To change the p_indate of product with pno P01 to 02-AUG-2011.
UPDATE PRODUCT
SET p_indate =’02-AUG-2011’
Page 25](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-25-320.jpg)
![WHERE pno=’P01’;
Restoring table contents or ROLLBACK:
ROLLBACK-undoes any changes since the last COMMIT command and brings the data
back to the values that existed before the changes were made.
Syntax: ROLLBACK;
Ex:
1. Create table called sales.
2. Insert 10 rows in sales table.
3. Execute the ROLLBACK command
ROLLBACK will undo only the result of INSERT and UPDATE commands.
All data definition commands(CREATE TABLE) are automatically committed to data
dictionary and cannot be rolled back.
DELETE Command
DELETE -deletes one or more rows from a table
If you do not specify a WHERE condition , all rows from table will be deleted.
REMOVAL OF SPECIFIED ROW(S):
Syntax: DELETE FROM tablename [WHERE conditionlist];
REMOVAL OF ALL ROWS:
Syntax: DELETE FROM tablename;
Viewing data in tables or SELECT
SELECT-lists the contents of a table.
Syntax:
SELECT columnlist
FROM tablename
[WHERE conditionlist];
The columnlist represents one or more attributes separated by commas.
You can use the * wildcard character to list all attributes.
Ex1: SELECT * FROM PRODUCT;
Ex2: SELECT pdesc,p_indate FROM product WHERE pno=’P01’;
Ex3:SELECT * FROM product WHERE p_indate>’01-AUG-2011’;
The SELECT statement retrieves all rows that match the specified condition.
WHERE clause adds conditional restrictions to SELECT statement.
The condition list is represented by one or more conditional expressions separated by logical
operators.
Comparison operators can be used to restrict output.
Comparison operators:
Symbol Meaning Example
= Equal to SELECT * FROM product WHERE pno=’P01’;
< Less than SELECT * FROM product WHERE price<10;
<= Less than or equal to
> Greater than SELECT * FROM product WHERE price>10;
>= Greater than or equal
to
<> or !
=
Not equal to SELECT * FROM product WHERE vno <> 100;
Using Computed Columns
Page 26](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-26-320.jpg)

![SELECT * FROM product WHERE price BETWEEN 10 AND 100;
IS NULL operator:
Used to check whether an attribute value is null.
Ex: To list all the products that do not have a vendor assigned, use the command:
SELECT * FROM product WHERE vno IS NULL;
LIKE operator:Used only with char and varchar2.
Matches a string pattern.
Used in conjuction with wildcards to find patterns within string attributes.
Ex1: To find all vendors whose name start with R
SELECT * FROM vendor WHERE vname LIKE ‘R%’;
To find all vendors whose name has ‘a’ as second letter.
Ex2: SELECT * FROM vendor WHERE vname LIKE ‘_a%’;
SQL allows you to use the percent sign (%) and underscore( _ ) wild card characters to make
matches when the entire string is not known.
Wildcard Meaning
% Matches any characters
_ Matches one characters
Matches can be made when the query entry is written exactly like table entry.
IN operator: matches any value within a VALUE list.
uses an equality operator i.e, it selects only those rows that match(are equal to) atleast
one of the values in the list
Ex:
SELECT * FROM product
WHERE vno IN(100 , 101);
All of the values in the list must be of same data type.
Each of the values in the value list is compared to the attribute.
IN operator is valuable when it is used in subqueries.
SELECT * FROM vendor
WHERE vno IN(SELECT vno FROM product );
Subquery (SELECT vno FROM product) will list all vendors who supply products.
IN operator will compare the values generated by subquery to vno values in VENDOR table.
EXISTS operator:checks whether subquery returns any row.
If subquery returns any row, run the main query otherwise don’t.
Ex:
SELECT * FROM vendor
WHERE (SELECT * FROM product WHERE qoh<=10);
Modifying structure of table:
ALTER Command: All changes to table structure are made using the ALTER command.
Syntax:
ALTER TABLE tablename
{ADD|MODIFY} (columnname datatype [{ADD|MODIFY} columnname datatype]);
To Change column’s datatype
Page 28](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-28-320.jpg)
![To change the vname datatype from varchar2 to char
ALTER TABLE vendor MODIFY (vname char(35));
To Change column’s data characteristics
To increase the width of vname column to 55 characters
ALTER TABLE vendor MODIFY (vname char(35));
To add a column
ALTER TABLE product ADD (pmin number(5));
If the table already has some data , we cannot add new column with NOT NULL as existing
rows will default to NULL for the new column.
TO ADD TABLE CONSTRAINTS:
Syntax: ALTER TABLE tablename ADD constraint [ADD constraint];
To add primary key:
ALTER TABLE part ADD PRIMARY KEY(part_no);
To add foreign key:
ALTER TABLE part ADD FOREIGN KEY(vno) REFERENCES vendor;
(OR)
ALTER TABLE part ADD PRIMARY KEY(part_no)
ADD FOREIGN KEY(vno) REFERENCES vendor;
To add primary and foreign key using the keyword CONSTRAINT:
ALTER TABLE part ADD CONSTRAINT pk_partno PRIMARY KEY(part_no)
ADD CONSTRAINT fk_vno FOREIGN KEY(vno) REFERENCES vendor;
TO REMOVE A COLUMN OR TABLE CONSTRAINT
Synax: ALTER TABLE tablename
DROP{ PRIMARY KEY | COLUMN columnname | CONSTRAINT constraintname};
Dropping a column: deleting a column
ALTER TABLE product DROP COLUMN pmin;
DELETING A TABLE FROM DATABASE:
A table can be deleted from the database using the DROP TABLE command.
Syntax:
DROP TABLE part;
Advanced select queries
ORDER BY clause: Orders the selected rows based on one or more attributes
• Used in the last portion of select statement
• By using this, rows can be sorted
• By default it takes ascending order
• DESC is used for sorting in descending order
• Sorting by column which is not in select list is possible.
• Sorting by column aliases
Example: To produce a list of products sorted in descending order of their prices.
SELECT pno,pdesc,p_indate,price
FROM product
Page 29](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-29-320.jpg)



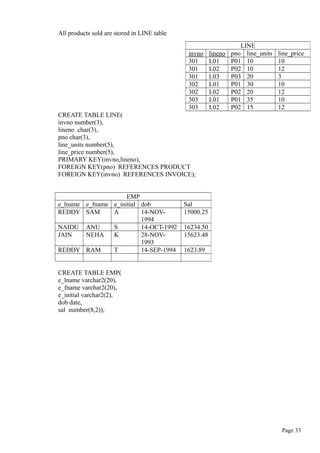

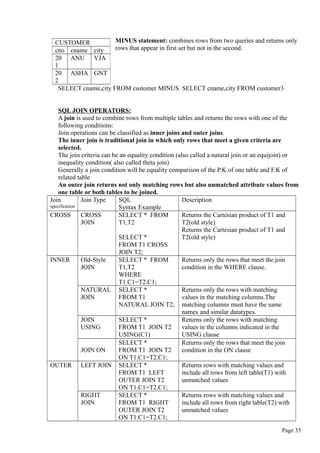







![Oracle sequences: generates a numeric value that can be assigned to any column in any
table.
Use of sequences is optional, you can enter the values manually.
Oracle sequences have a name and can be used any where a value is expected.
Sequences can be created and deleted anytime.
The table attribute to which you assigned a value based on a sequence can be edited and
modified.
Oracle sequences are
• Independent objects in the database.
• Not a data type
• Not tied to a table or column
Syntax:
CREATE SEQUENCE name [START WITH n] [INCREMENT BY n] [CACHE |
NOCACHE]
where name is the name of the sequence
n is an integer that can be positive or negative.
START WITH specifies initial sequence value( the default value is 1)
INCREMENT BY determines the value by which the sequence is incremented.
The CACHE or NOCACHE indicates whether oracle will preallocate sequence numbers in
memory. (Oracle preallocates 20 values by default)
Example: CREATE SEQUENCE CSEQ1 START WITH 204 INCREMENT BY 1
NOCACHE;
To check all the sequences you have created.
SELECT * FROM USER_SEQUENCES;
To use sequences during data entry
you must use two special pseudo columns NEXTVAL and CURRVAL.
NEXTVAL retrieves the next available value from a sequence. Each time you use
NEXTVAL , the sequence is incremented.
CURRVAL retrieves the current value of sequence.
Example
INSERT INTO CUSTOMER VALUES (CSEQ1.NEXTVAL,’RAVI’,’NELLORE’, 500);
INSERT INTO INVOICE VALUES (‘I05’ , CSEQ1.CURRVAL,’22-AUG-2011’);
You cannot use CURRVAL unless a NEXTVAL was issued previously in the same session.
NEXTVAL retrieves the next available sequence number( here 204) and signs to cno in
CUSTOMER table.
CSEQ1.CURRVAL refers to last used CSEQ1.NEXTVAL sequence number(204).
In this way the relationship between INVOICE and CUSTOMER is established.
COMMIT; statement must be issued to make the changes permanent.
You can also issue a ROLLBACk statement , in which case the rows you inserted in
INVOICE and CUSTOMER will be rolled back.( but sequence number would not) That is, if
you use sequence number again you must get 204 but you will get 205 eventhough the row
204 is deleted.
DROPPING a SEQUENCE doesnot delete the values you assigned to table attributes.
Syntax: DROP SEQUENCE CSEQ1;
Page 43](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-43-320.jpg)



![PL/SQL Basic data types
Data Type Description
CHAR character values of a fixed length
VARCHAR2 variable length character values
NUMBER numeric values
DATE Date values
%TYPE inherits the datatype from a variable that you declared previously or from an
attribute of a database table. Ex: price1 PRODUCT.price %TYPE ;
assigns price1 the same datatype as the price column in the PRODUCT table.
Q: Write anonymous PL/SQL program to display the number of products in price range
0 and 10, 11 and 60 ,61 and 110 etc..
Ans:
DECLARE
P1 NUMBER(3) := 0;
P2 NUMBER(3) := 10;
NUM NUMBER(2) := 0;
BEGIN
WHILE P2<5000 LOOP
SELECT COUNT(pno) INTO NUM FROM product WHERE price BETWEEN P1 AND P2;
DBMS_OUTPUT.PUT_LINE(‘There are ‘|| NUM|| ‘ products with price between ‘||P1|| ‘ and
‘||P2);
P1 := P2+1;
P2 := P2+50;
END LOOP;
END;
/
The PL/SQL block shown above has following characteristics.
1. Each statement inside the PL/SQL code must end with a semicolon
2. The PL/SQL block starts with the DECLARE section in which you declare the
variable names, the data types and an initial value(optional).
3. A WHILE loop is used.
4. Uses the string concatenation symbol.
5. SELECT statement uses the INTO keyword to assign output of the query to a PL/SQL
variable
The most useful feature of PL/SQL block is that they let you create code that can be named,
stored and executed either implicitly or explicitly by the DBMS.
What is Trigger ? Explain.
Ans: A trigger is a procedural sql code which is fired when a DML statements like Insert,
Delete, Update is executed on a database table.
The syntax to create a trigger in oracle is:
CREATE OR REPLACE TRIGGER trigger_name
[BEFORE / AFTER] [DELETE /INSERT/UPDATE OF column_name ] ON table_name
[FOR EACH ROW]
[DECLARE]
[variable_name data-type [:= initial_value]]
BEGIN
PL/SQL instructions;
……
Page 47](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-47-320.jpg)


![• Creation of replica tables for back up purposes.
Q:What are the various type of triggers?
Statement – level triggers: This type of trigger is executed once, before or after the
triggering statement is completed.
Example of a statement level trigger that is executed after an update of the qoh, pmin
attribute for an existing row or after an insert of a new row in the product table.
CREATE or REPLACE TRIGGER TPR
AFTER INSERT OR UPDATE OF QOH,PMIN ON PRODUCT
BEGIN
UPDATE PRODUCT
SET REORDER =1
WHERE QOH <= PMIN;
END;
/
Row – level triggers: requires the use of the FOR EACH ROW keywords. This type of
trigger is executed once for each row affected. ( if you update 10 rows, the trigger executes
10 times.
Example: CREATE or REPLACE TRIGGER TPR
BEFORE INSERT OR UPDATE OF QOH, PMIN ON PRODUCT
FOR EACH ROW
BEGIN
IF :NEW.QOH <= :NEW.PMIN THEN
:NEW.REORDER :=1;
ELSE
:NEW.REORDER :=0;
END IF;
END;
/
What are Stored Procedures? Explain?
A stored procedure is a named group of SQL statements that have been previously created
and stored in the server database.
Advantages:
• Stored procedures accept input parameters so that a single procedure can be
used over the network by several clients using different input data.
• Stored procedures reduce network traffic and improve performance.
• Stored procedures can be used to help ensure the integrity of the database.
• Stored procedures help reduce code duplication by means of code isolation and code
sharing, there by minimizing the chance of errors and the cost of application
development and maintenance.
• Stored procedures are useful to encapsulate shared code to represent business
transactions i.e, you need not know the name of newly added attribute and would need
to add new parameter to the procedure call.
Syntax to create procedure:
CREATE OR REPLACE PROCEDURE procedure_name [(argument [in/out] data-type,….)]
[IS / AS] [variable_name data-type [:= initial_value]]
BEGIN
PL/SQL or SQL statements;
…
END;
Page 50](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-50-320.jpg)
![Syntax to execute a stored procedure
EXEC procedure_name[(parameter_list)];
Ex: Write a stored procedure to assign an additional 5 % discount for all products when the
QOH = 2PMIN
CREATE OR REPLACE PROCEDURE prod_discount AS
BEGIN
UPDATE product
SET discount = discount + .05
WHERE qoh >= pmin * 2;
DBMS_OUTPUT.PUT_LINE(‘*** Update Finished ***’);
END;
/
1. argument specifies the parameters that are passed to the stored procedures. A stored
procedure could have zero or more arguments.
2. IN/OUT indicates whether the parameter is for input, output or both.
3. Variables can be declared between the keywords IS and BEGIN.
To make percentage increase an input variable in the above procedure---
CREATE OR REPLACE PROCEDURE prod_discount ( pd IN NUMBER)
AS BEGIN
IF ((pd <= 0) OR (pd >= 1)) THEN
DBMS_OUTPUT.PUT_LINE(‘Error value must be greater than 0 and less than 1’);
ELSE
UPDATE product
SET discount = discount + .05
WHERE qoh >= pmin * 2;
DBMS_OUTPUT.PUT_LINE(‘*** Update Finished ***’);
END IF;
END;
/
To execute the above procedure---
EXEC prod_discount(.05);
Q: write a stored procedure to add new customer.
CREATE OR REPLACE PROCEDURE cadd (w_cname IN VARCHAR2, w_city IN
VARCHAR2)
AS
BEGIN
INSERT INTO customer (cno, cname, city) values(CSEQ1.NEXTVAL, w_cname,
w_city);
DBMS_OUTPUT.PUT_LINE(‘Customer added ’);
END;
/
The procedure uses
• several parameters one for each required attribute in the CUSTOMER table.
• CSEQ1 sequence to generate a new customer code.
The parameters can be null only when the table specifications permit null for that parameter.
To execute:
EXEC cadd(‘KALA’, ‘VJA’,NULL);
Page 51](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-51-320.jpg)
![Q: Write procedures to add new invoice and line row.
Ans:
CREATE OR REPLACE PROCEDURE invadd(w_cno IN NUMBER, w_date IN DATE)
AS BEGIN
INSERT INTO invoice
VALUES(ISEQ.NEXTVAL, w_cno, w_date);
DBMS_OUTPUT.PUT_LINE(‘Invoice Added’);
END;
/
CREATE OR REPLACE PROCEDURE lineadd (ln IN CHAR, pn IN CHAR, lu IN
NUMBER)
AS
lp NUMBER := 0;
BEGIN
SELECT price INTO lp
FROM product
WHERE pno = pn ;
INSERT INTO line VALUES(ISEQ. CURRVAL, ln, pn, lu, lp);
DBMS_OUTPUT.PUT_LINE(‘Invoice Line Added’);
END;
/
Q: What is a cursor? How many types of cursors are there? How to handle cursors?
Ans:Cursor is reserved area in memory in which output of the query is stored,
like an array holding rows and columns.
There are two types of cursors: implicit and explicit.
An implicit cursor is automatically created in PL/SQL when the SQL statement returns only
one value.
An explicit cursor is created to hold the output of an SQL statement that may return two or
more rows.(but could return 0 or only one row)
To create an explicit cursor, use the following syntax inside PL/SQL DECLARE section.
CURSOR cursor_name IS select-query;
The cursor declaration section only reserves a named memory area for the cursor.
Once you declared a cursor, you can use cursor processing commands anywhere between the
BEGIN and END keywords of the PL/SQL block.
Cursor Processing Commands
Cursor Command Explanation
OPEN Executes the SQL command and populates the cursor with data
Before you can use a cursor, you need to open it Ex: OPEN
cursor_name.
FETCH To retrieve data from the cursor and copy it to the PL/SQL variables.
The syntax is : FETCH cursor_name INTO variable1 [,variable2,
…..]
CLOSE The CLOSE command closes the cursor for processing
Cursor style processing involves retrieving data from the cursor one row at a time.
The set of rows the cursor holds is called the active set.
The data set contains a current row pointer.
Therefore after opening a cursor, the current row is the first row of the cursor.
Page 52](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-52-320.jpg)































![Explain about SQL extensions for OLAP?
Ans: The following are important SQL extensions for OLAP
The ROLLUP extension: is used with the GROUP BY clause to generate aggregates by
different dimensions.
Syntax:
SELECT column1, column2 [,…],aggregate_function(expression)
FROM table1, [table2,…]
[WHERE condition]
GROUP BY ROLL UP(column1,column2[,…])
[HAVING condition]
[ORDER BY column1[,column2,…]]
The order of the column list within the GROUP BY ROLL UP is very important. The
last column in the list will generate a grand total. All other columns will generate
subtotals.
The CUBE extension:
Is used to compute all possible subtotals within groupings based on multiple dimensions.
The CUBE extension will enable to get a subtotal for each column listed in the expression
and grand total for the last column listed.
Syntax: SELECT column1, column2 [,…],aggregate_function(expression)
FROM table1, [table2,…]
[WHERE condition]
GROUP BY CUBE(column1,column2[,…])
[HAVING condition]
[ORDER BY column1[,column2,…]]
Materialized views:
A materialized view is a dynamic table that not only contains the SQL query command to
generate the rows, but also stores the actual rows. The materialized view created the first time
the query is run and summary rows are stored in the table. The materialized view row are
automatically updated when the base tables are updated.
Syntax:
CREATE MATERIALIZED VIEW view_name
BUILD { IMMEDIATE | DEFERRED}
REFRESH {[FAST | COMPLETE | FORCE]} ON COMMIT
[ENABLE QUERY REWRITE]
AS select_query
The BUILD clause indicate when the materialized view rows are actually populated.
IMMEDIATE indicates rows are populated right after the command is entered.
DEFFERED indicates rows are populated at a later time. Until then view will be in an
unusable state.
The REFRESH clause lets you indicate when and how to update the view when new rows are
added to base tables.
FAST indicates updates only affected rows.
COMPLETE indicates a complete update will be made for all rows in materialized view.
FORCE indicates that the DBMS will first try to do a FAST update, otherwise it will do a
COMPLETE update.
ON COMMIT indicates the updates to the materialized view will take place as a part of the
commit of the DML transaction that updated the base tables.
ENABLE QUERY REWRITE option allow DBMS to use the materialized views in query
optimization.
Page 89](https://image.slidesharecdn.com/dbms-160827145620/85/Dbms-89-320.jpg)