Downloaded 15 times







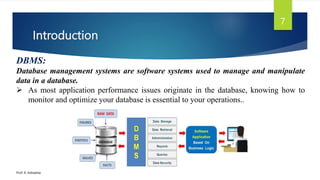


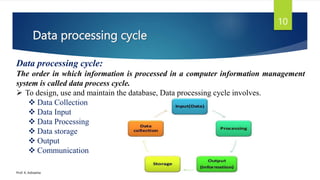


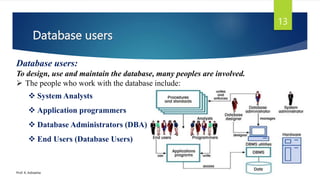

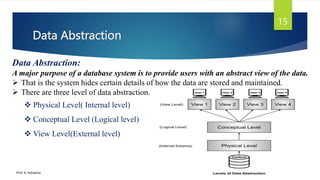





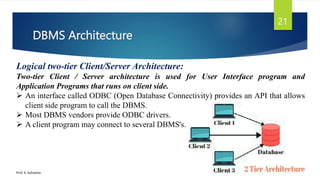



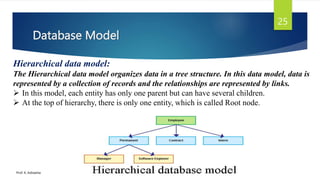

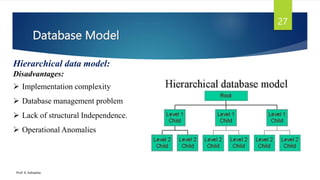
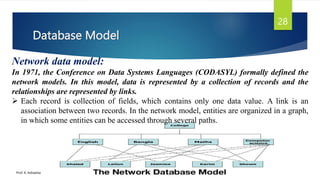
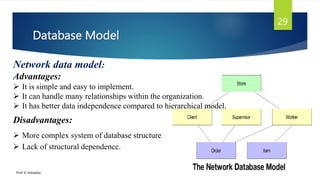




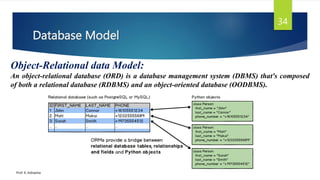
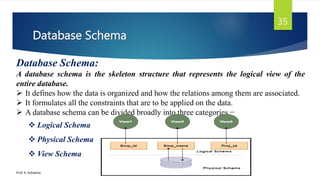














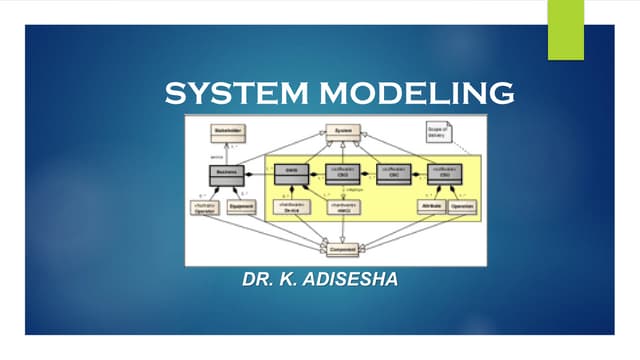
The document provides an introduction to database management systems and related concepts. It defines key terms like data, information, database, and record. It describes the differences between manual and computerized data processing. It then discusses traditional file-based data storage approaches and their limitations. The document introduces database management systems and their applications. It provides a brief history of DBMS and discusses the data processing cycle and the roles of different database users. Finally, it covers various database models including hierarchical, network, relational, object-oriented, and object-relational models.