Downloaded 35 times





![© 2019 Ververica6
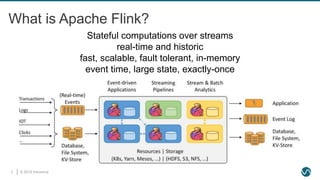
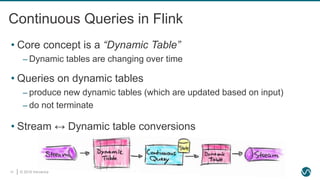
Flink’s Powerful Abstractions
Process Function (events, state, time)
DataStream API (streams, windows)
SQL / Table API (dynamic tables)
Stream- & Batch
Data Processing
High-level
Analytics API
Stateful Event-
Driven Applications
val stats = stream
.keyBy("sensor")
.timeWindow(Time.seconds(5))
.sum((a, b) -> a.add(b))
def processElement(event: MyEvent, ctx: Context, out: Collector[Result]) = {
// work with event and state
(event, state.value) match { … }
out.collect(…) // emit events
state.update(…) // modify state
// schedule a timer callback
ctx.timerService.registerEventTimeTimer(event.timestamp + 500)
}
Layered abstractions to
navigate simple to complex use cases](https://image.slidesharecdn.com/flinksqlinaction-190529072200/85/Flink-SQL-in-Action-6-320.jpg)









![© 2019 Ververica21
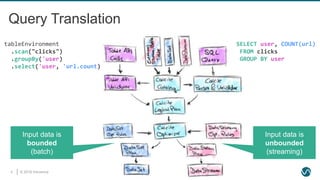
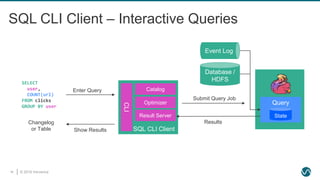
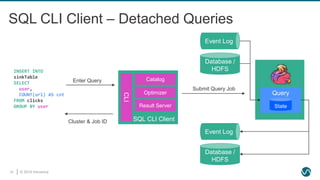
SQL Feature Set in Flink 1.8.0
STREAMING ONLY
• OVER / WINDOW
‒ UNBOUNDED / BOUNDED
PRECEDING
• INNER JOIN with time-versioned
table
• MATCH_RECOGNIZE
‒ Pattern Matching/CEP (SQL:2016)
BATCH ONLY
• UNION / INTERSECT / EXCEPT
• ORDER BY
STREAMING & BATCH
• SELECT FROM WHERE
• GROUP BY [HAVING]
‒ Non-windowed
‒ TUMBLE, HOP, SESSION windows
• JOIN
‒ Time-Windowed INNER + OUTER
JOIN
‒ Non-windowed INNER + OUTER JOIN
• User-Defined Functions
‒ Scalar
‒ Aggregation
‒ Table-valued](https://image.slidesharecdn.com/flinksqlinaction-190529072200/85/Flink-SQL-in-Action-21-320.jpg)

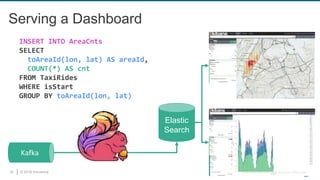







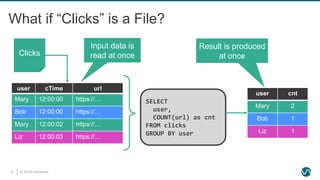
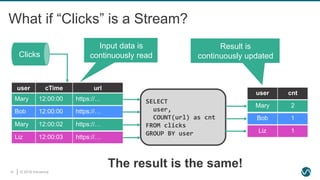
The document provides an overview of Apache Flink, focusing on its capabilities for processing both streaming and batch data through relational APIs. It highlights the importance of unifying stream and batch processing, illustrating how Flink's SQL can handle a range of real-time analytics tasks with ease and efficiency. The document also discusses the framework’s application in major companies and outlines plans for future enhancements.


























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
















