Downloaded 12 times






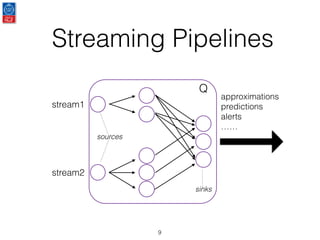
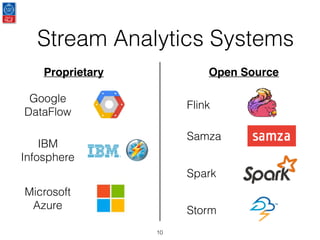

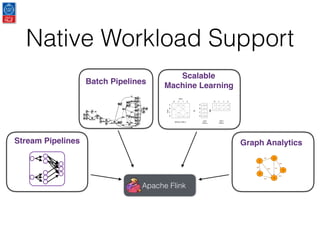
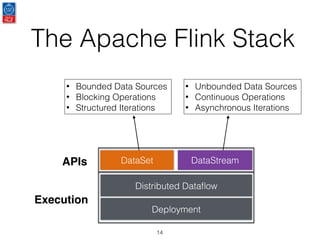
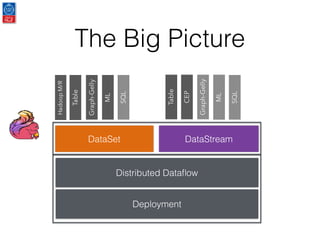
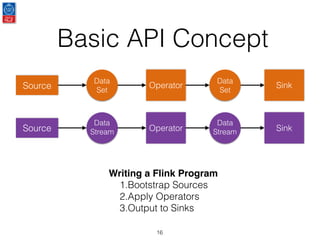
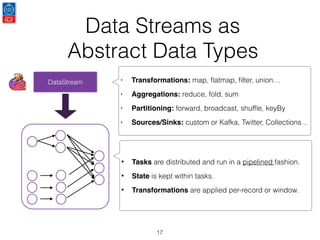

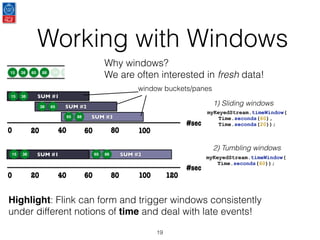

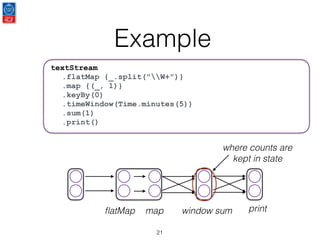
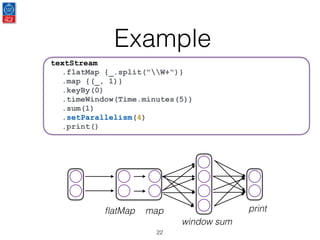








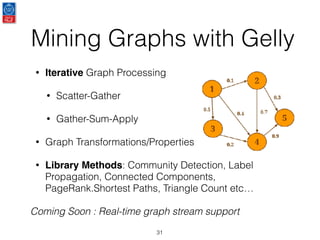





This document presents an introduction to data stream analytics utilizing Apache Flink, emphasizing its capabilities in handling time-critical problems like stock market predictions and fraud detection. It outlines the architecture of Flink, including stream processing, windowing concepts, and fault tolerance mechanisms, as well as comparing Flink's streaming execution and mutable state features to those of Apache Spark. The content also highlights various applications and libraries for pattern detection, machine learning, and graph processing within the Flink ecosystem.