Download as PDF, PPTX












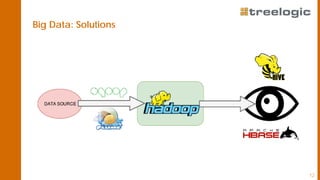

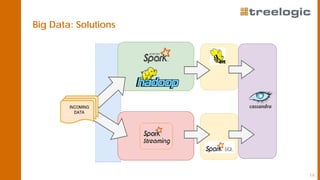




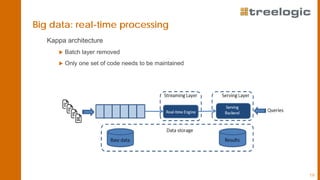



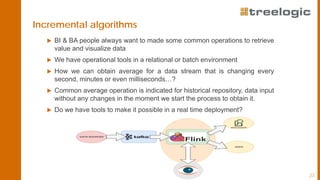


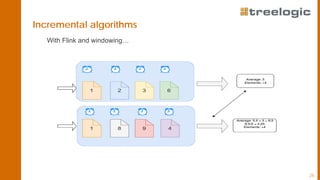

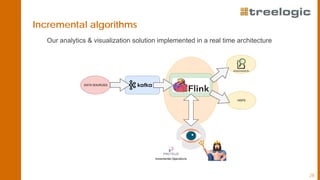








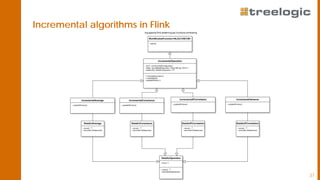

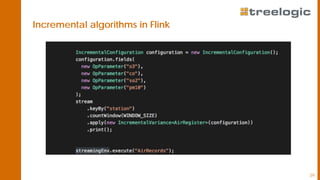








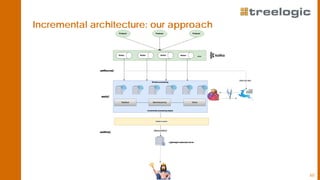



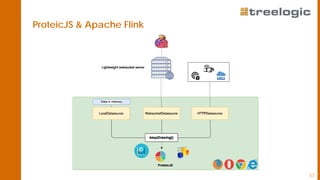



The document discusses advanced data science algorithms in scalable stream processing, highlighting the importance of big data and the need for efficient solutions such as real-time processing, incremental algorithms, and distributed data storage. It introduces Apache Flink and compares it to Apache Spark, emphasizing the benefits of low latency and high throughput for real-time analytics. A use case in the steel industry is presented, showcasing how predictive analytics can improve production efficiency and quality.


































































































