Download as PDF, PPTX




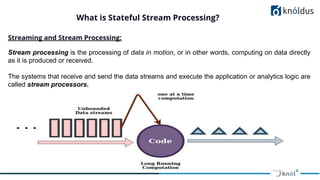
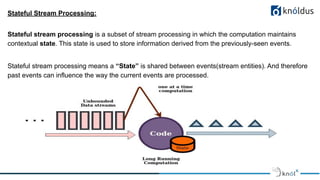

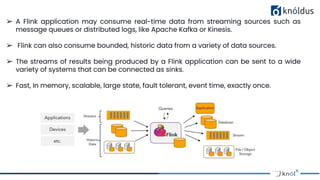
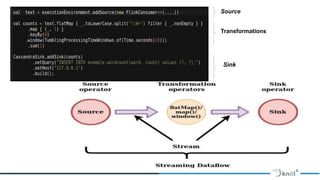
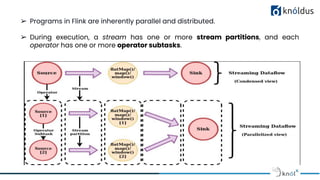
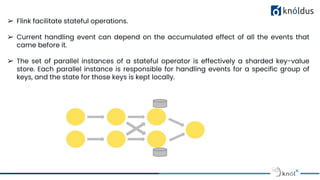
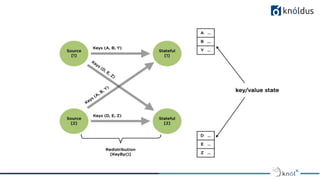

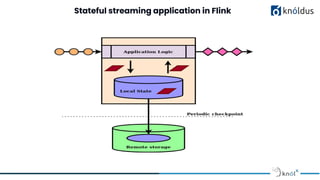
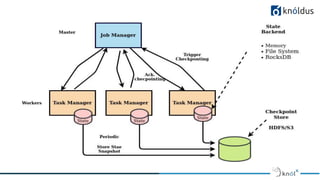



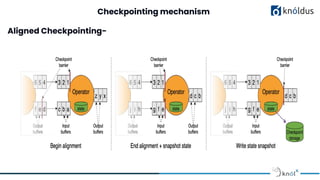
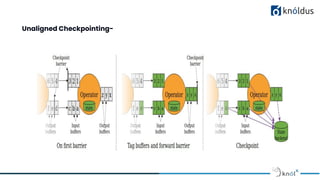





The document discusses stateful stream processing using Apache Flink, including its definition, capabilities, and types of state management (operator, keyed, broadcast, and queryable state). It details how Flink handles data streams both in real-time and from bounded sources, emphasizing its scalability, fault tolerance, and support for large states. Additionally, the document outlines different state backends (memory, file system, and rocksdb) and the checkpointing process, which allows for replaying data from specific points in the stream.























































































