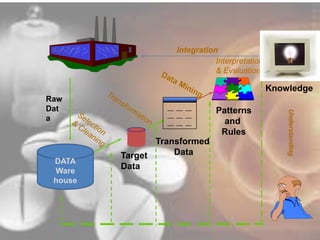
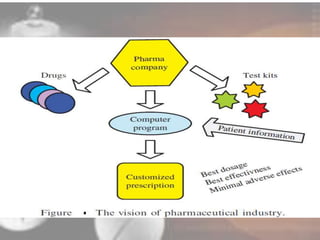
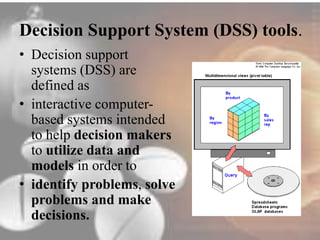
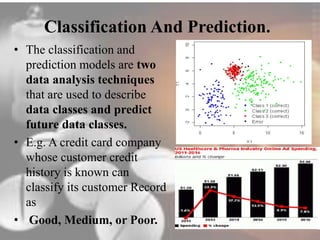
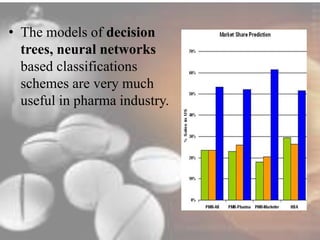
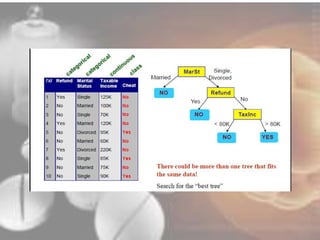
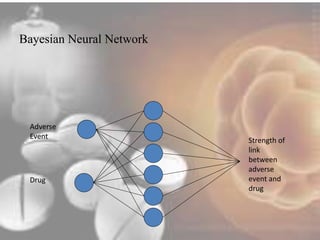
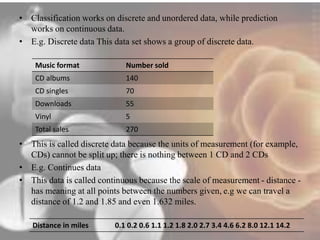
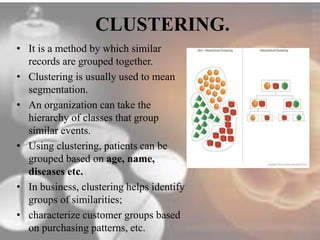
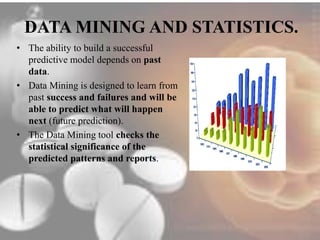
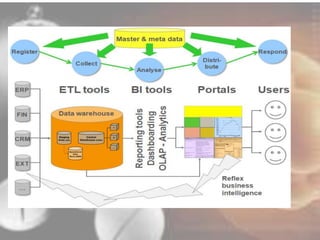
Data mining techniques can help pharmaceutical companies analyze large datasets to identify hidden patterns and relationships. This allows companies to make more informed decisions. Specifically, data mining allows analysis of clinical, financial, and organizational data to support clinicians, manage treatment pathways, and efficiently use resources. Techniques like classification, prediction, clustering, and association rule mining can be applied to areas like drug discovery, predicting patient responses, and optimizing operations.




























































![Investigational New drug application [INDA]](https://cdn.slidesharecdn.com/ss_thumbnails/investigationalnewdrugapplicationinda-160619063044-thumbnail.jpg?width=640&height=640&fit=bounds)































































































