Downloaded 68 times











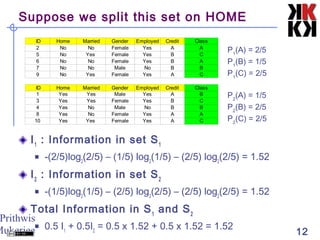







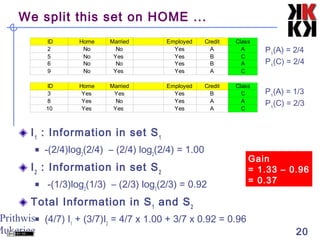
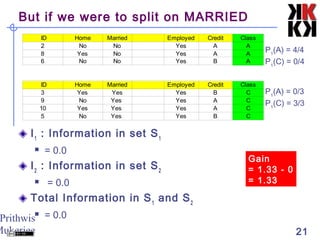



This document discusses classification techniques in data mining. It defines classification as separating objects into classes either before or after examining the data. The general approach is to decide on classes without looking at data, train the system on a small subset, then use rules derived from attributes to classify the full dataset. Decision trees are constructed by recursively splitting nodes based on attributes that maximize information gain and reduce uncertainty between classes. The document provides an example of building a decision tree to classify animals using attributes like eggs, pouch, flies, and feathers.



























































































