Downloaded 85 times























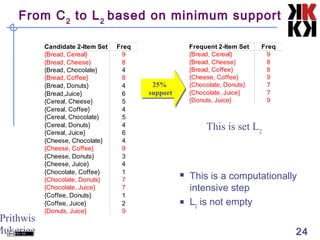







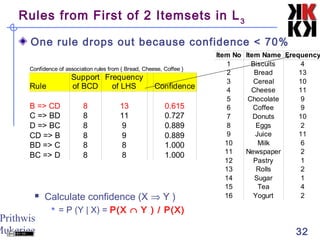
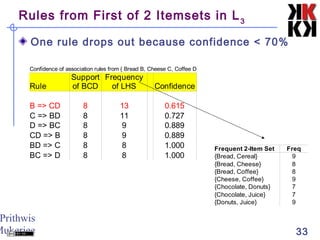
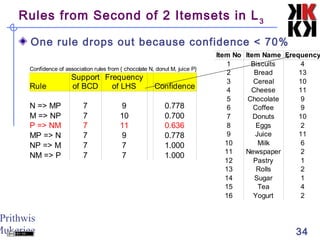
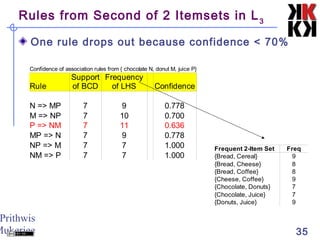
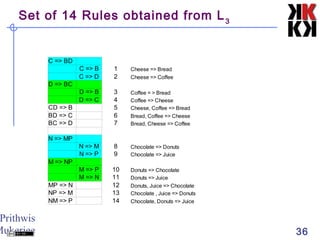

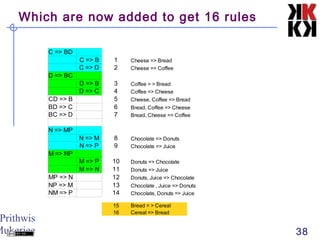





The document discusses association rule mining and market basket analysis. It begins by describing the problem - a retailer tracking what items customers purchase together. It then provides definitions for key concepts in association rule mining like support, confidence and lifts. The goal is to discover all association rules that have minimum support and confidence thresholds. Common algorithms like Apriori are described to efficiently generate frequent itemsets and association rules from transactional data.



































































