Downloaded 22 times


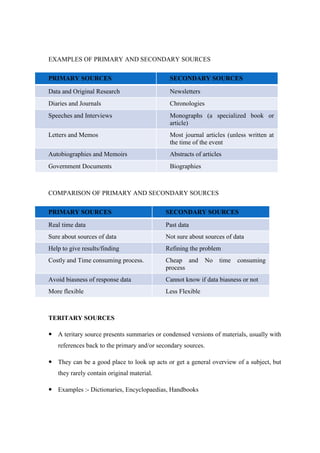





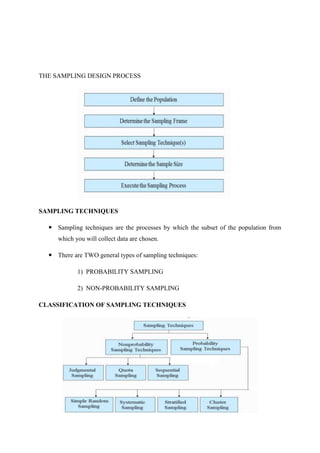












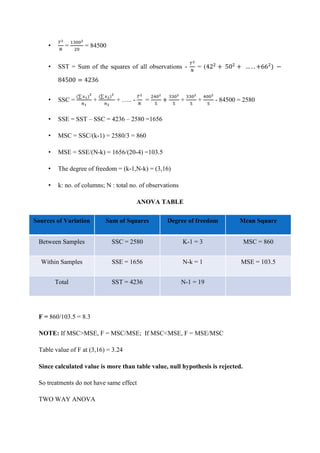


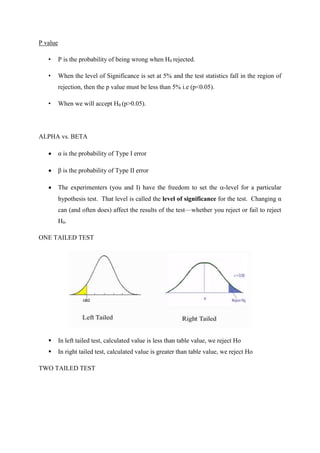


This document discusses different sources and methods of data collection. It begins by defining data and data collection. There are three main sources of data: primary sources which are original data collected for the purpose, secondary sources which are previously collected data being reused, and tertiary sources which present summaries of primary and secondary sources. Common methods of collecting primary data include observation, surveys, interviews, case studies, and field investigations. The document also discusses different sampling techniques used in data collection, distinguishing between probability sampling methods like simple random sampling which give all subjects an equal chance of being selected, and non-probability sampling.









































































