Download as PDF, PPTX













![Hive Query Rewrite
query before query after
SELECT airport_code, count(*)
FROM event_table
JOIN airport
ON st_contains(simplified_shape, st_point(location.lng,location.lat))
WHERE datestr = ‘2017-02-01’
GROUP BY 1
set hive.geospatial.index.list=[Airports:airport airport_code
simplified_shape];
SELECT AirportsContainsFirst(st_point(location.lng,location.lat)), count(*)
FROM event_table
WHERE datestr = '2017-02-01'
GROUP BY 1](https://image.slidesharecdn.com/geospatialsratany-170928034310/85/Presto-GeoSpatial-Strata-New-York-2017-23-320.jpg)




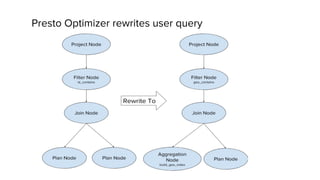

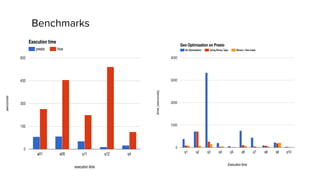



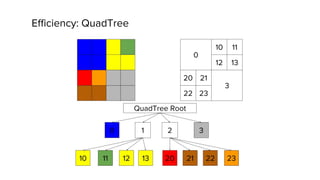
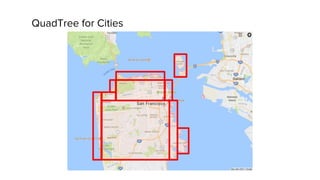
The document discusses geospatial analytics at Uber using Presto. Presto is an interactive SQL query engine that allows for fast querying of large datasets. The document outlines how Presto was optimized for geospatial queries using quadtree indexing to efficiently filter spatial data and speed up queries involving spatial functions like ST_Contains. This improved query performance for geospatial queries in Presto by 60x compared to the previous approach using Hive.















































