Download as PDF, PPTX

















![Scio
Ecclesiastical Latin IPA: /ˈʃi.o/, [ˈʃiː.o], [ˈʃi.i̯o]
Verb: I can, know, understand, have knowledge.](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-25-2048.jpg)

![WordCount
val sc = ScioContext()
sc.textFile("shakespeare.txt")
.flatMap { _
.split("[^a-zA-Z']+")
.filter(_.nonEmpty)
}
.countByValue
.saveAsTextFile("wordcount.txt")
sc.close()](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-28-2048.jpg)
![PageRank
def pageRank(in: SCollection[(String, String)]) = {
val links = in.groupByKey()
var ranks = links.mapValues(_ => 1.0)
for (i <- 1 to 10) {
val contribs = links.join(ranks).values
.flatMap { case (urls, rank) =>
val size = urls.size
urls.map((_, rank / size))
}
ranks = contribs.sumByKey.mapValues((1 - 0.85) + 0.85 * _)
}
ranks
}](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-29-2048.jpg)

![Type safe BigQuery
Macro generated case classes, schemas and converters
@BigQuery.fromQuery("SELECT id, name FROM [users] WHERE ...")
class User // look mom no code!
sc.typedBigQuery[User]().map(u => (u.id, u.name))
@BigQuery.toTable
case class Score(id: String, score: Double)
data.map(kv => Score(kv._1, kv._2)).saveAsTypedBigQuery("table")](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-31-2048.jpg)





![Fan Insights
● Listener stats
[artist|track] ×
[context|geography|demography] ×
[day|week|month]
● BigQuery, GCS, Datastore
● TBs daily
● 150+ Java jobs → ~10 Scio jobs](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-38-2048.jpg)


![Listening history
● user x track x
[day/week/month/all time]
● 300B elements
● 800 n1-highmem-32 workers
● 32 core 208GB RAM
● 240TB in - Bigtable
● 90TB out - GCS](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-41-2048.jpg)
![BigDiffy
● Pairwise field-level statistical diff
● Diff 2 SCollection[T] given keyFn: T => String
● T: Avro, BigQuery JSON, Protobuf
● Leaf field Δ - numeric, string (Levenshtein), vector (Cosine)
● Δ statistics - min, max, μ, σ, etc.
● Non-deterministic fields
○ ignore field
○ treat "repeated" field (List) as unordered list (Set)
Part of github.com/spotify/ratatool](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-42-2048.jpg)

![Pairwise field-level deltas
val lKeyed = lhs.keyBy(keyFn)
val rKeyed = rhs.keyBy(keyFn)
val deltas = (lKeyed outerJoin rKeyed).map { case (k, (lOpt, rOpt)) =>
(lOpt, rOpt) match {
case (Some(l), Some(r)) =>
val ds = diffy(l, r) // Seq[Delta]
val dt = if (ds.isEmpty) SAME else DIFFERENT
(k, (ds, dt))
case (_, _) =>
val dt = if (lOpt.isDefined) MISSING_RHS else MISSING_LHS
(k, (Nil, dt))
}
}](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-44-2048.jpg)
![Summing deltas
import com.twitter.algebird._
// convert deltas to map of (field → summable stats)
def deltasToMap(ds: Seq[Delta], dt: DeltaType)
: Map[String,
(Long, Option[(DeltaType, Min[Double], Max[Double], Moments)])] = {
// ...
}
deltas
.map { case (_, (ds, dt)) => deltasToMap(ds, dt) }
.sum // Semigroup!](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-45-2048.jpg)


![Transforming features
case class Record(d1: Double, d2: Option[Double], d3: Double,
s: Seq[String])
val spec = FeatureSpec.of[Record]
.required(_.d1)(Binarizer("bin", threshold = 0.5))
.optional(_.d2)(Bucketizer("bucket", Array(0.0, 10.0, 20.0)))
.required(_.d3)(StandardScaling("std"))
.required(_.d3)(QuantileDiscretizer("q", 4))
.required(_.s)(NHotEncoder("nhot"))
val f = spec.extract(records)
f.featureNames // human readable names
f.featureValues[DenseVector[Double]] // output format
f.featureSettings // settings can be reloaded](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-48-2048.jpg)







![Serialization
● Data ser/de
○ Scalding, Spark and Storm uses Kryo and Twitter Chill
○ Dataflow/Beam requires explicit Coder[T]
Sometimes inferable via Guava TypeToken
○ ClassTag to the rescue, fallback to Kryo/Chill
● Lambda ser/de
○ Custom ClosureCleaner, Serializable and @transient lazy val
○ Scala 2.12, Java 8 lambda issues #10232 #10233](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-56-2048.jpg)
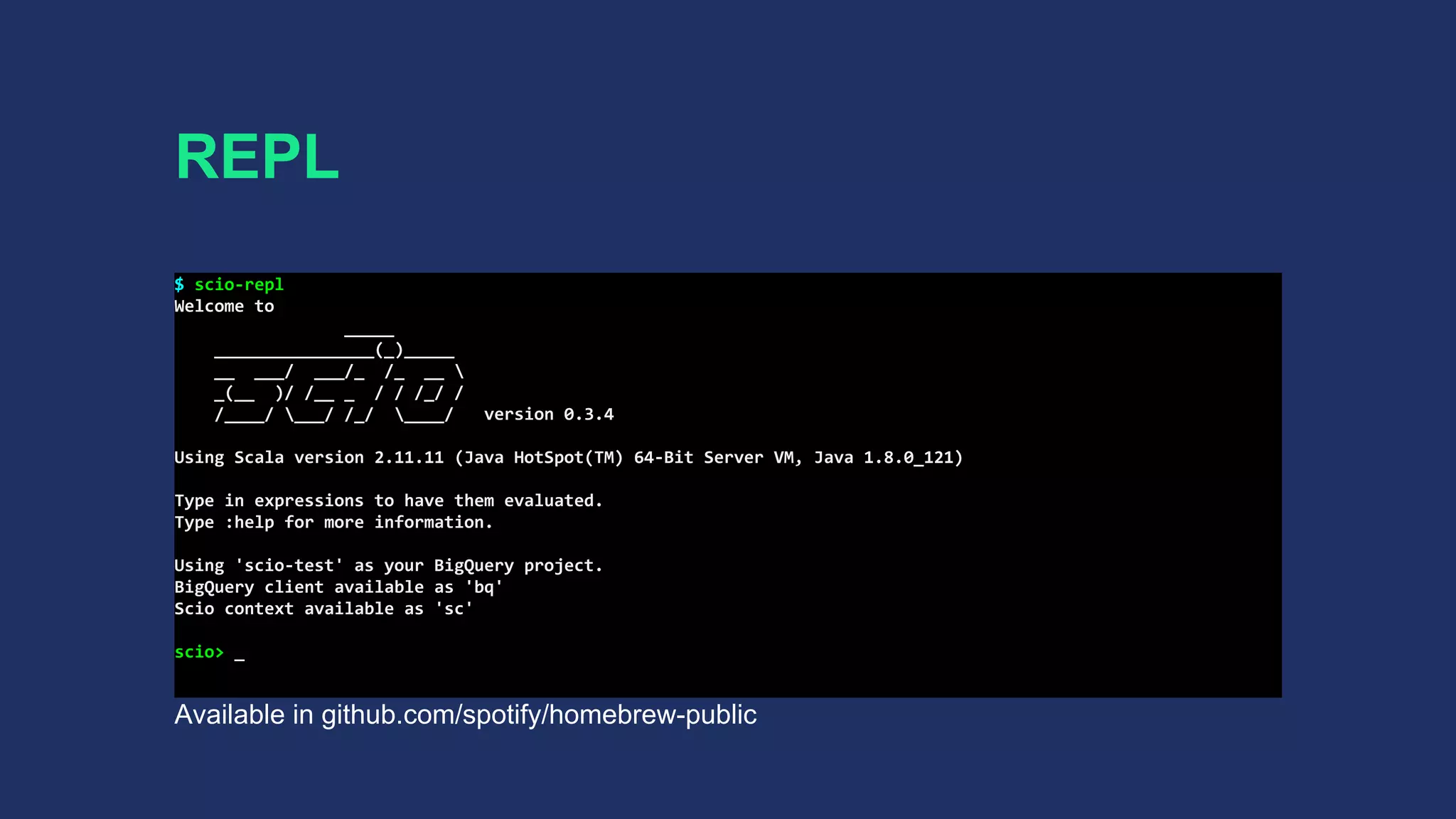
![REPL
● Spark REPL transports lambda bytecode via HTTP
● Dataflow requires job jar for execution (masterless)
● Custom class loader and ILoop
● Interpreted classes → job jar → job submission
● SCollection[T]#closeAndCollect(): Iterator[T]
to mimic Spark actions](https://image.slidesharecdn.com/scalaupnorth-170721211842/75/Sorry-How-Bieber-broke-Google-Cloud-at-Spotify-57-2048.jpg)


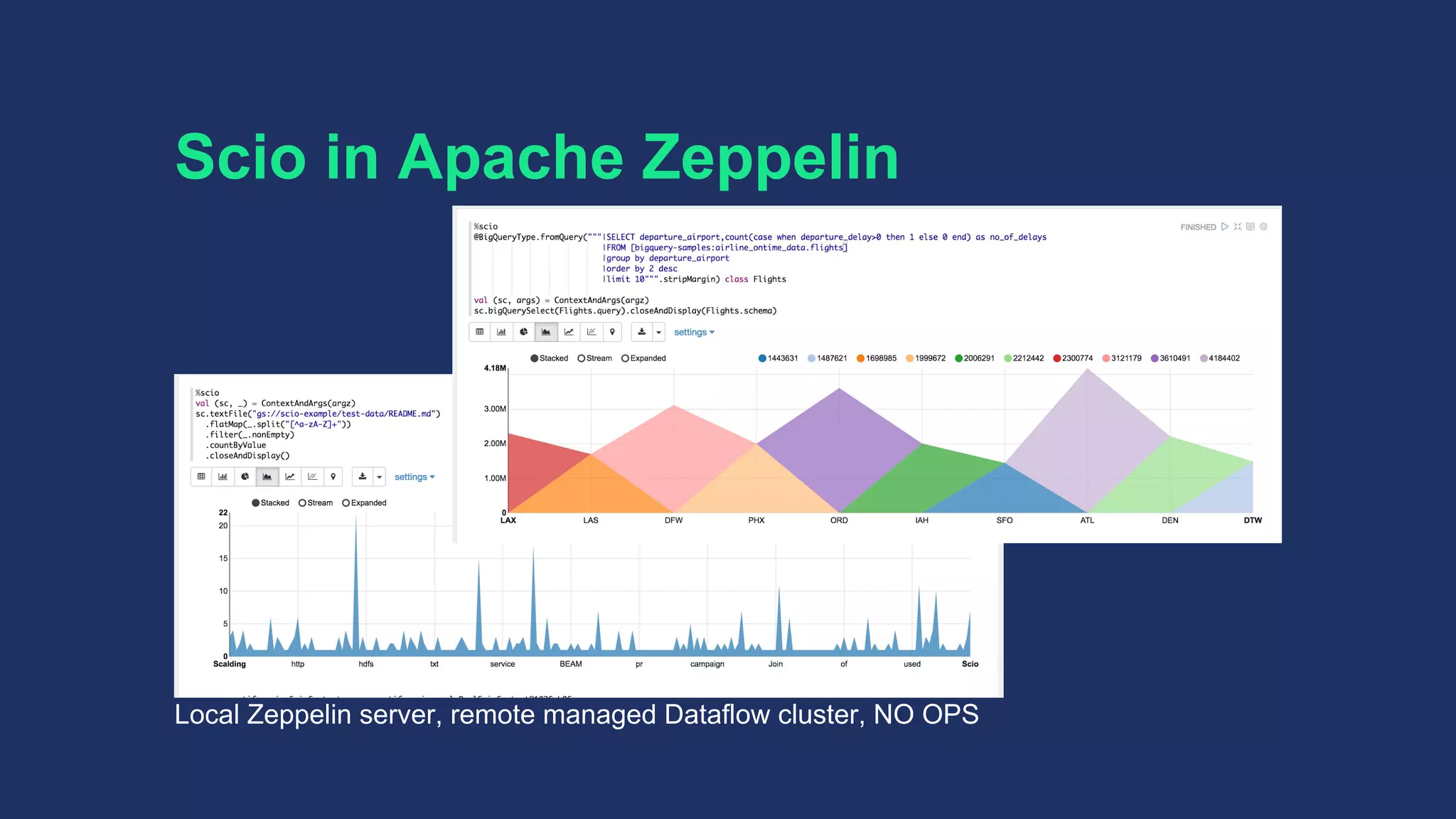


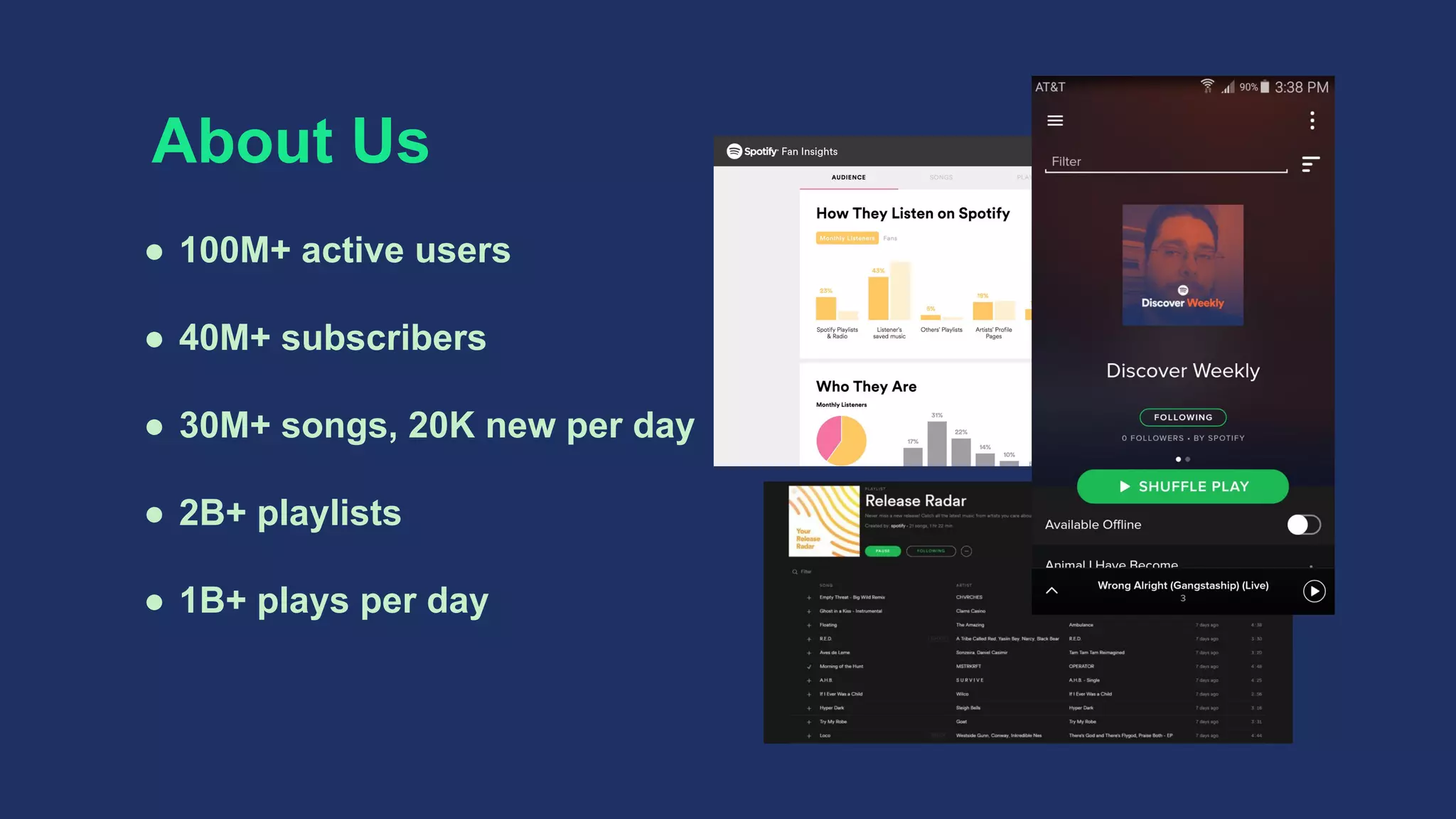
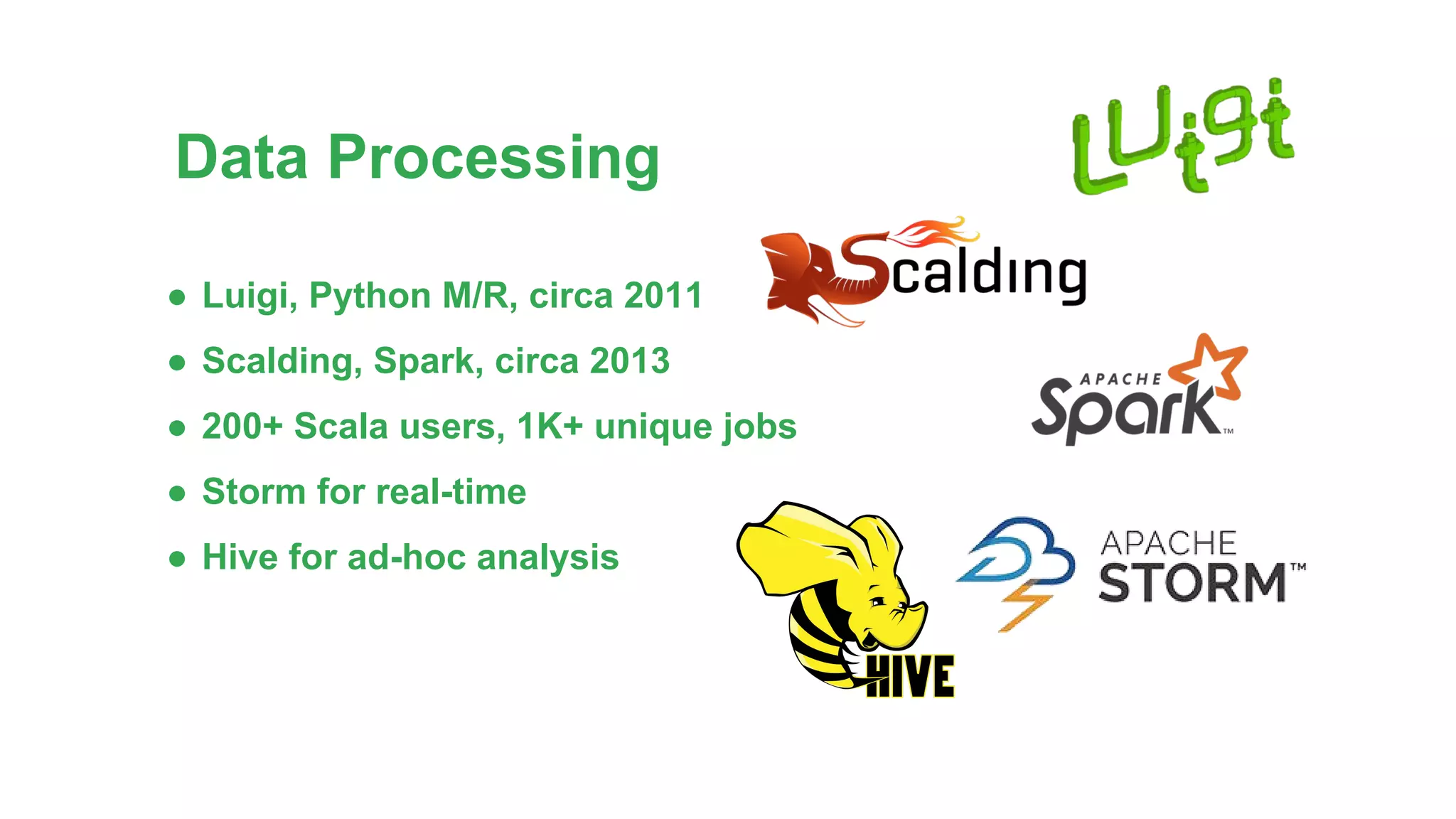
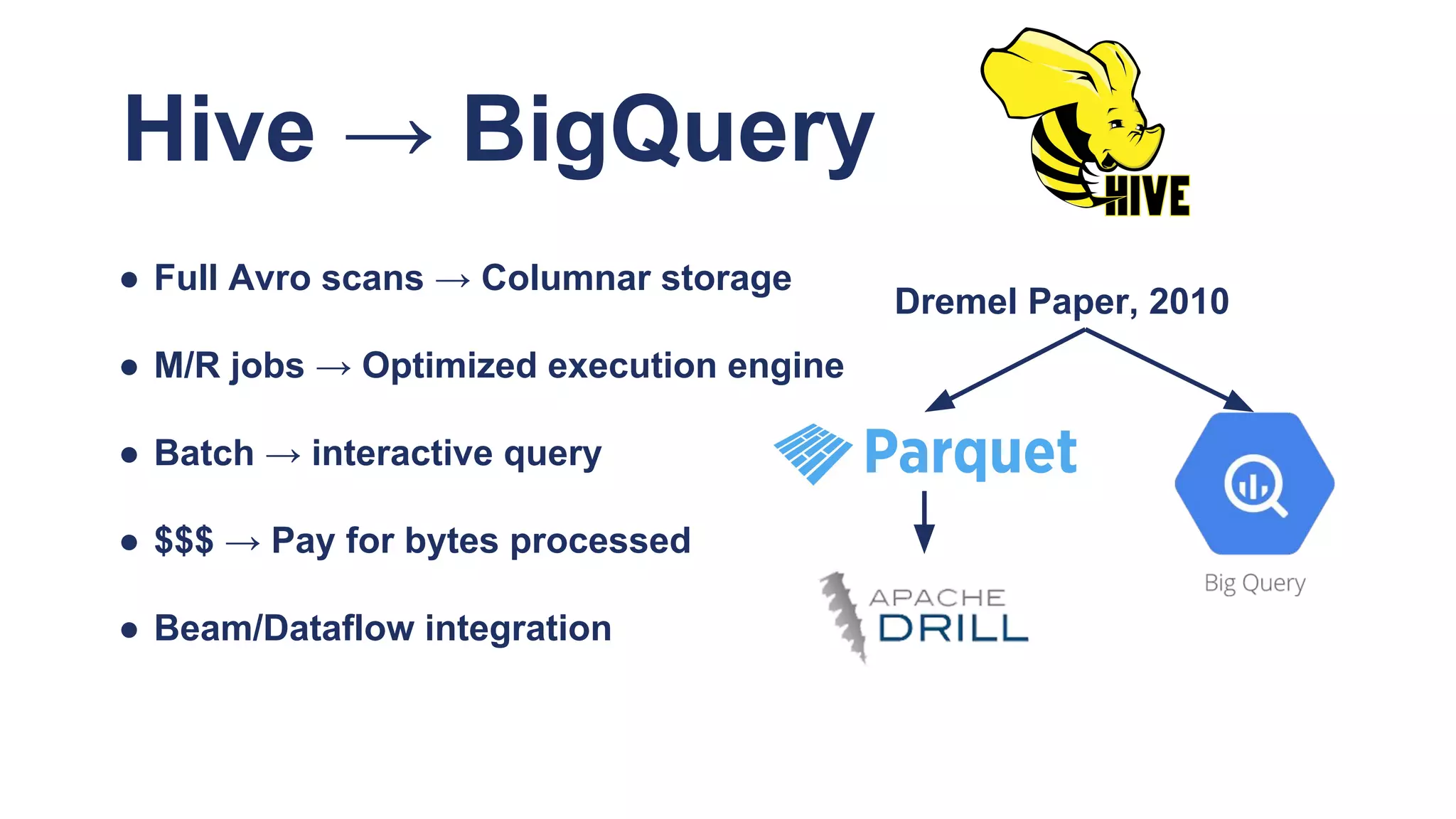
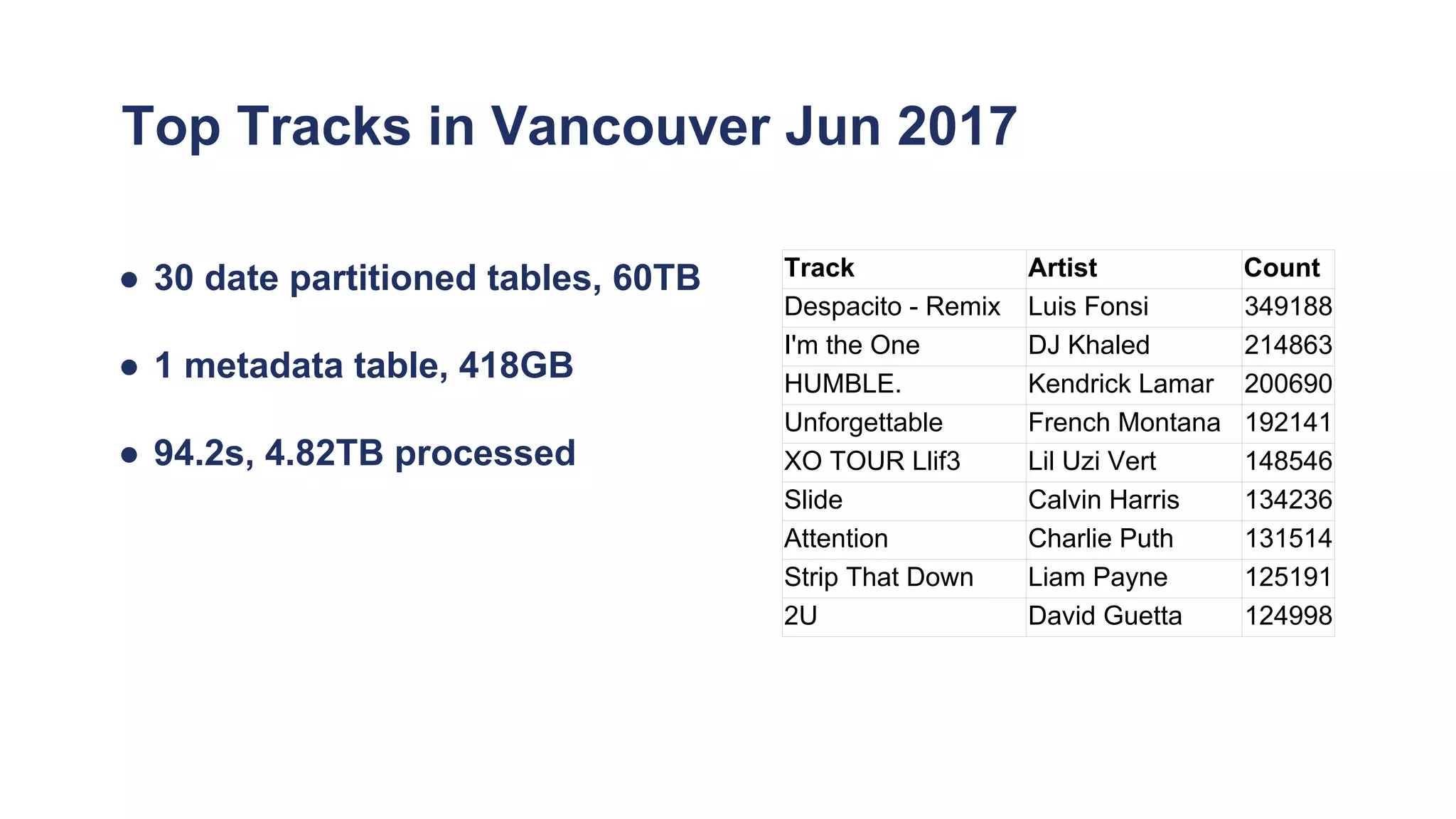
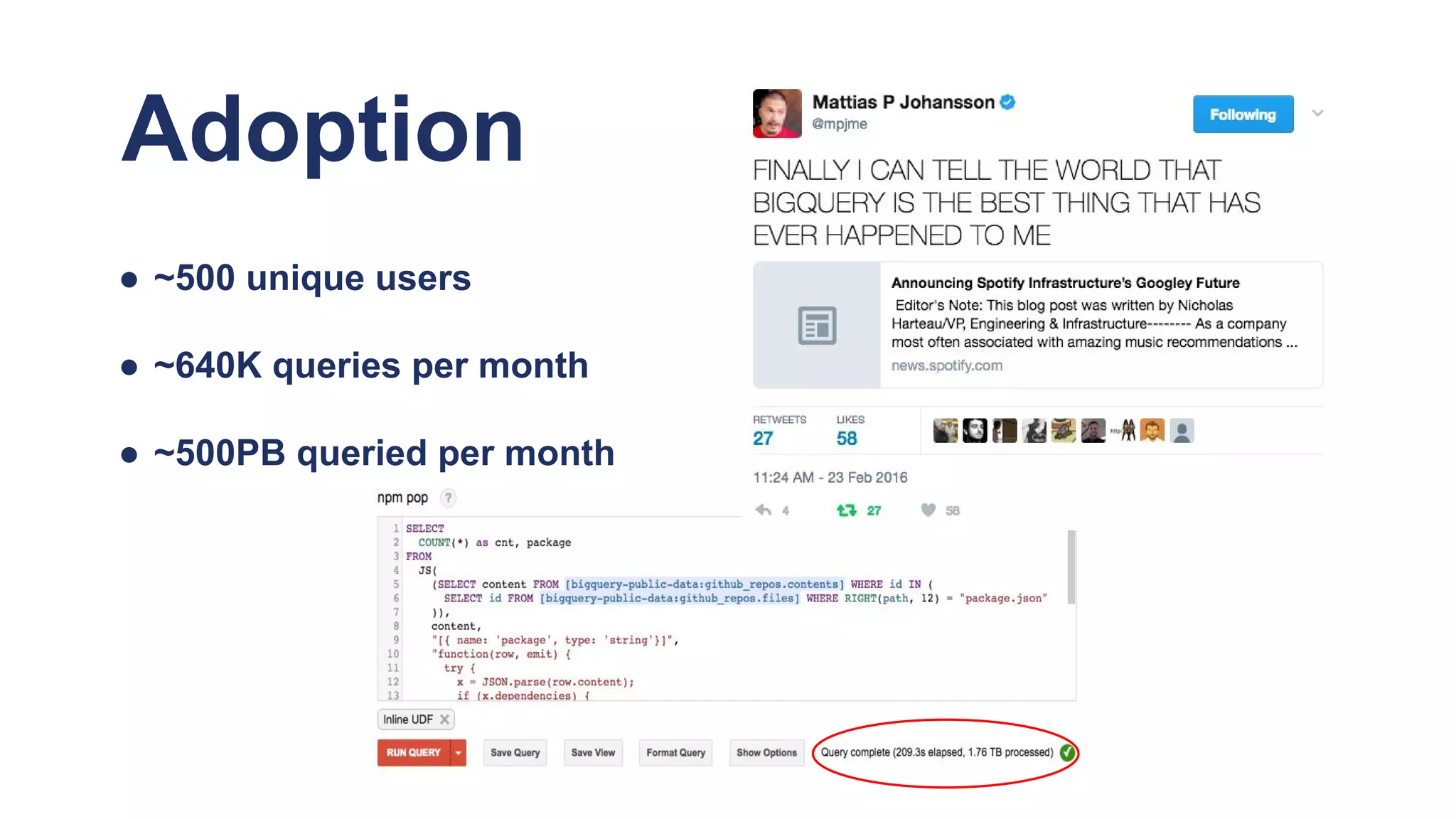
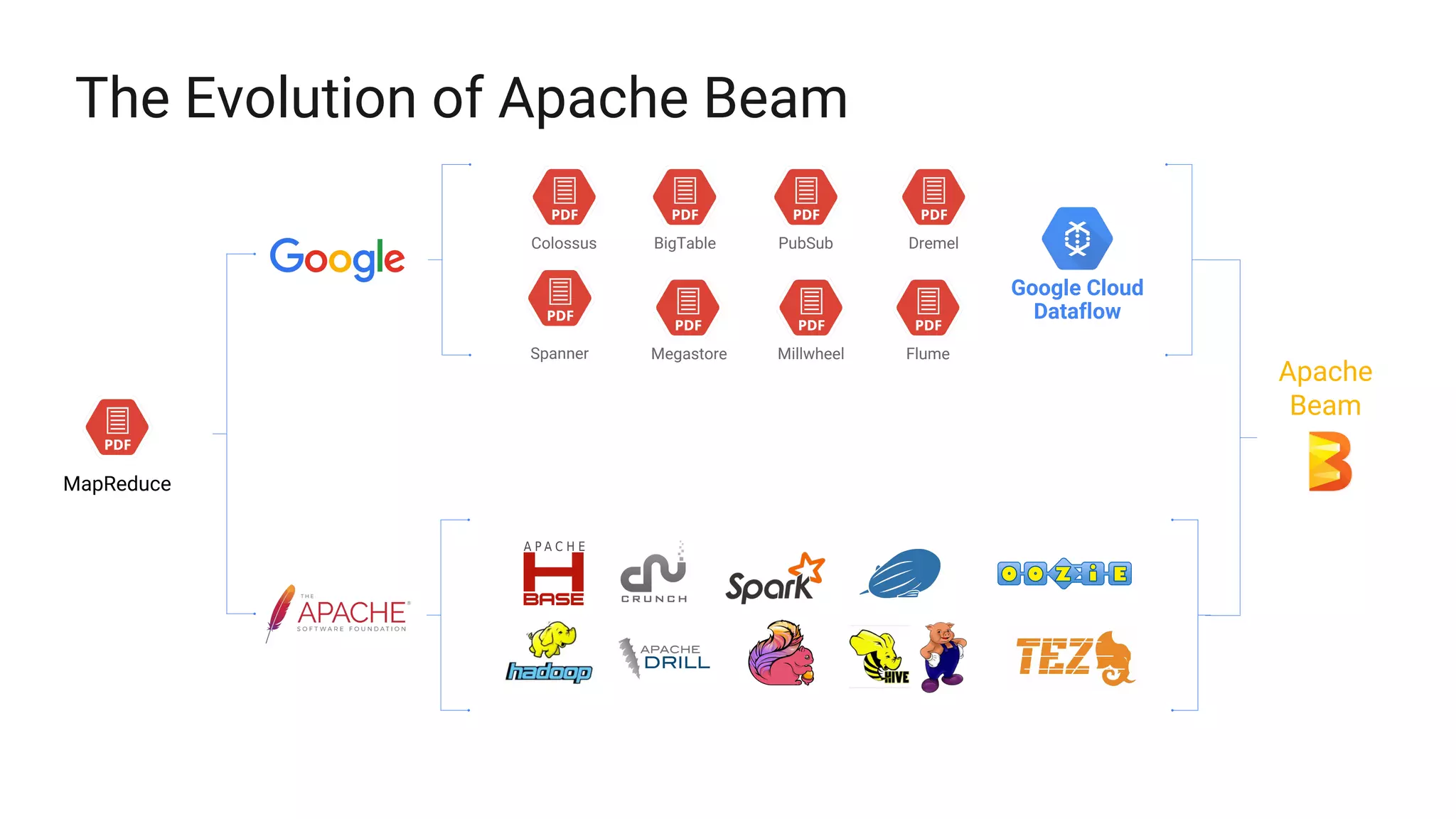
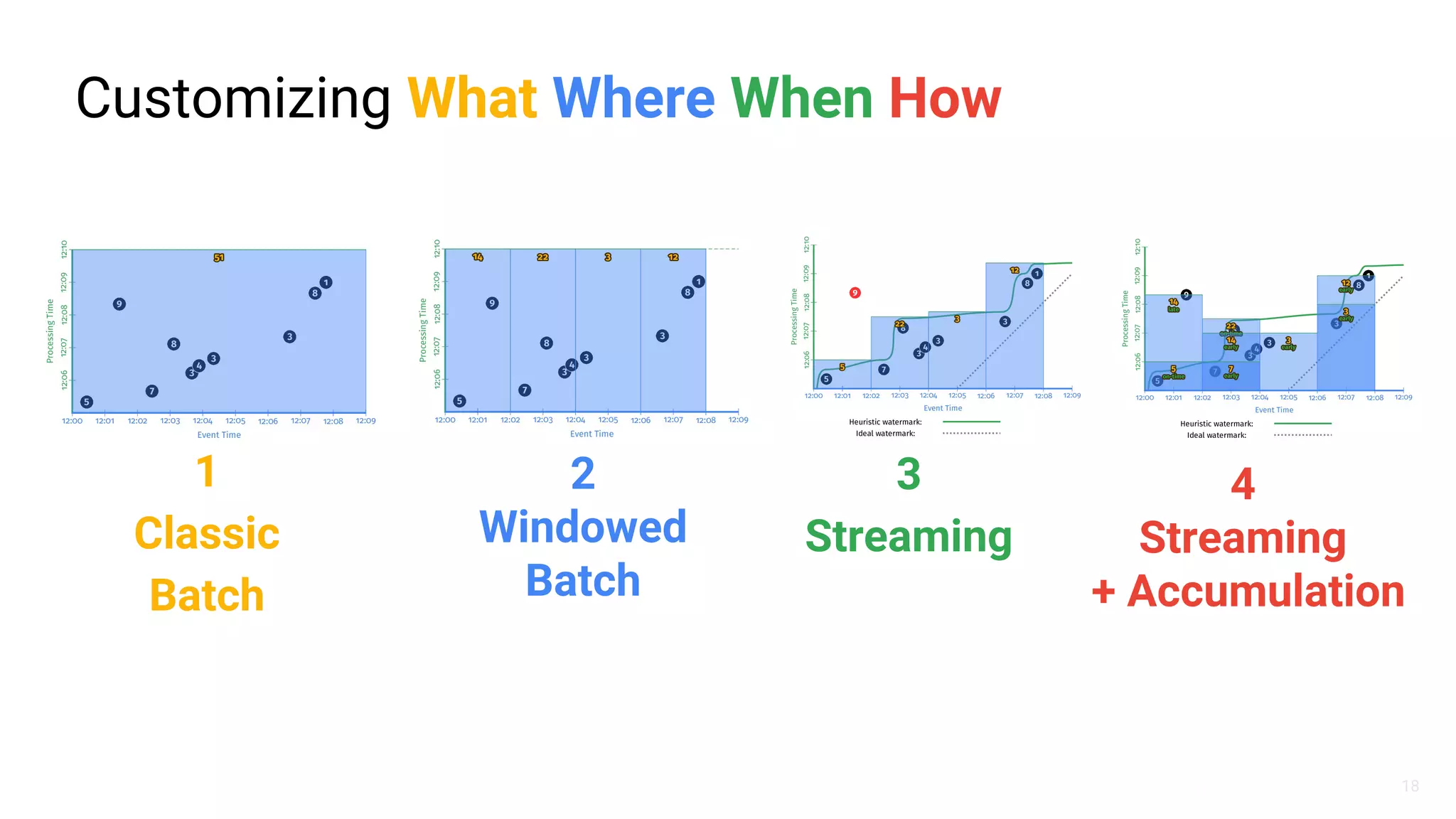
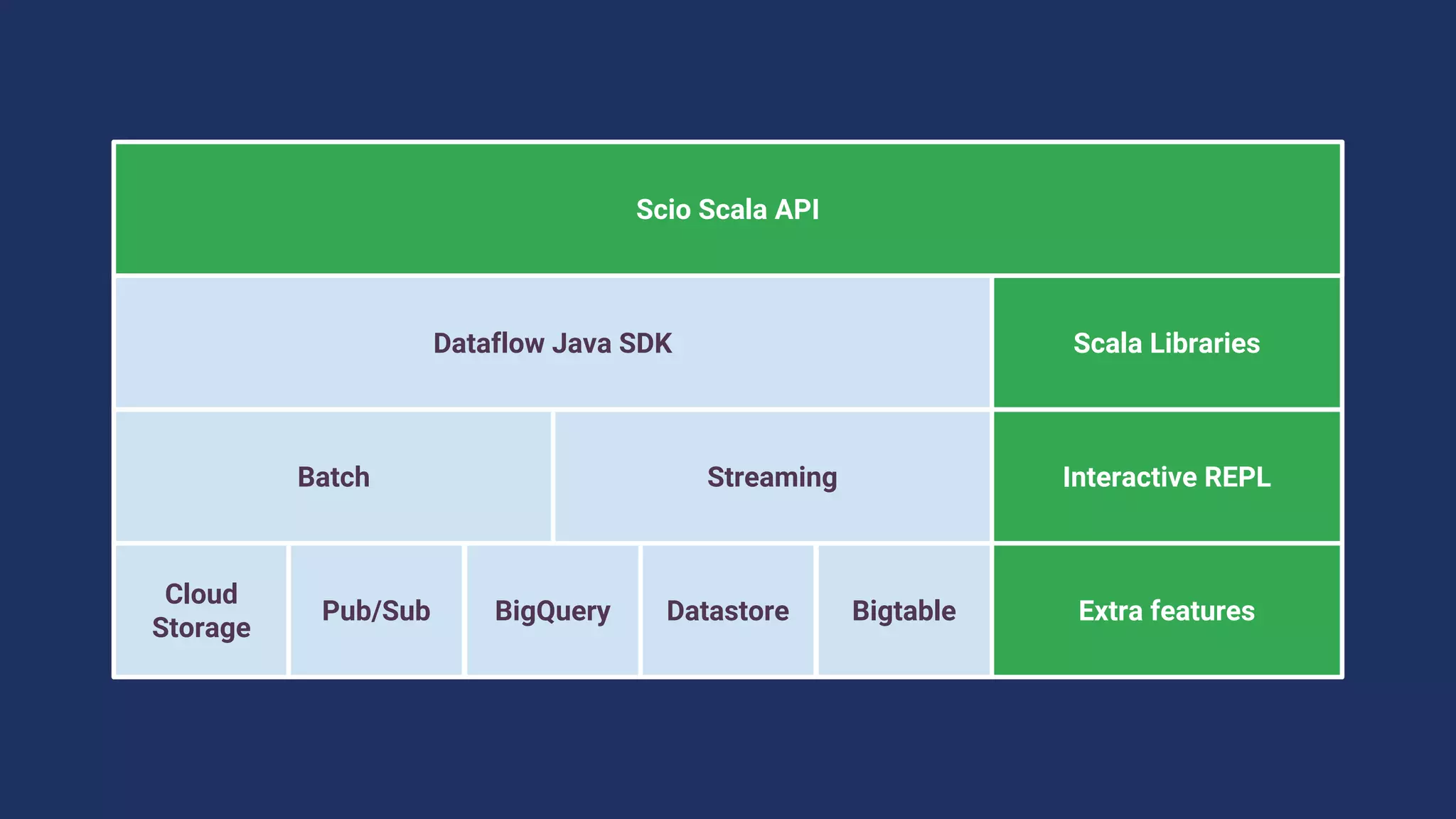
The document discusses Spotify's data infrastructure, emphasizing the transition to Google Cloud and the use of Apache Beam for data processing. It highlights Spotify's impressive metrics, including user counts and data processing capabilities, while detailing challenges and solutions related to scaling and performance. Additionally, it introduces Scio, a Scala API for Apache Beam, which enhances data processing with type safety and integration with BigQuery.



































































