Download to read offline





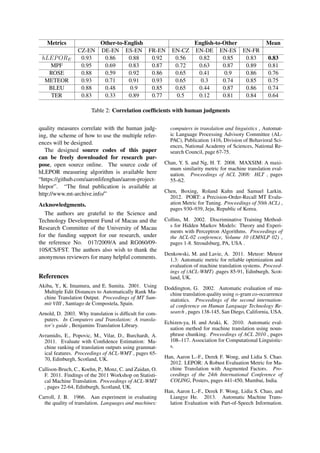




The document presents a novel language-independent metric for machine translation evaluation that incorporates enhanced factors and optional linguistic information, addressing previous metrics' weaknesses. It demonstrates better performance compared to classic evaluation metrics like BLEU and METEOR across various language pairs through extensive experimental validation. The proposed evaluation metric, named hlepor, utilizes tunable parameters and internal factors, such as precision, recall, and n-gram position differences, ensuring improved correlation with human judgments.








































































































