Download as PDF, PPTX







































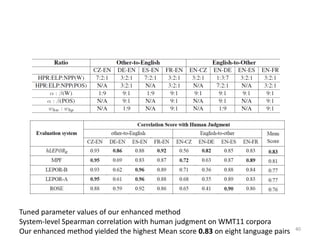












The document summarizes an academic thesis defense presentation on evaluating machine translation. It introduces the background of machine translation evaluation (MTE), existing MTE methods like BLEU, METEOR, WER, and their weaknesses. It then outlines the designed model for a new MTE metric called LEPOR, including designed factors like an enhanced length penalty and n-gram position difference penalty. The document concludes by discussing experiments, enhanced models, and applications in shared tasks to evaluate LEPOR's performance.





























































































