Download as PDF, PPTX











![CS-550 (M.Soneru): Recovery [SaS] 14
Consistent set of checkpoints
• Checkpointing in distributed systems requires that all processes (sites) that
interact with one another establish periodic checkpoints
• All the sites save their local states: local checkpoints
• All the local checkpoints, one from each site, collectively form a global
checkpoint
• The domino effect is caused by orphan messages, which in turn are caused
by rollbacks
1. Strongly consistent set of checkpoints
– Establish a set of local checkpoints (one for each process in the set)
such that no information flow takes place (i.e., no orphan messages)
during the interval spanned by the checkpoints
2. Consistent set of checkpoints
– Similar to the consistent global state
– Each message that is received in a checkpoint (state) should also be
recorded as sent in another checkpoint (state)](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-14-320.jpg)




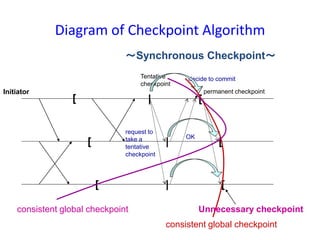
![Optimized Algorithm
Each message is labeled by order of sending
Labeling Scheme
⊥ : smallest label
т : largest label
last_label_rcvdX[Y] :
the last message that X received from Y after X has taken its last permanent or
tentative checkpoint. if not exists, ⊥is in it.
first_label_sentX[Y] :
the first message that X sent to Y after X took its last permanent or tentative
checkpoint . if not exists, ⊥is in it.
ckpt_cohortX :
the set of all processes that may have to take checkpoints when X decides to
take a checkpoint.
~Synchronous Checkpoint~
[
[
X
Y
x2
x3
y1 y2
y2
x2
Checkpoint request need to be sent to only the processes
included in ckpt_cohort](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-21-320.jpg)
![Optimized Algorithm
ckpt_cohortX : { Y | last_label_rcvdX[Y] > ⊥ }
Y takes a tentative checkpoint only if
last_label_rcvdX[Y] >= first_label_sentY[X] > ⊥
~Synchronous Checkpoint~
X
Y
[
[
last_label_rcvdX[Y]
first_label_sentY[X]](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-22-320.jpg)
![Optimized Algorithm
Algorithm
1. an initiating process takes a tentative checkpoint
2. it requests p ∈ ckpt_cohort to take tentative checkpoints ( this
message includes last_label_rcvd[reciever] of sender )
3. if the processes that receive the request need to take a checkpoint,
they do the same as 1.2.; otherwise, return OK messages.
4. they wait for receiving OK from all of p ∈ ckpt_cohort
5. if the initiator learns all the processes have succeeded, it decides all
tentative checkpoints should be made permanent; otherwise, should
be discarded.
6. it informs p ∈ ckpt_cohort of the decision
7. The processes that receive the decision act accordingly
~Synchronous Checkpoint~](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-23-320.jpg)
![Diagram of Optimized Algorithm
[
[
[
[
A
C
B
D
ab1 ac1
bd1
dc1 dc2
cb1
ba1 ba2
ac2cb2
cd1
|
Tentative
checkpoint
ca2
last_label_rcvdX[Y] >= first_label_sentY[X] > ⊥
2 >= 1 > 0|
2 >= 2 > 0|
2 >= 0 > 0
OK
decide to commit
[
Permanent
checkpoint
[
[
ckpt_cohortX : { Y | last_label_rcvdX[Y] > ⊥ }
~Synchronous Checkpoint~](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-24-320.jpg)

![Recovery Algorithm
Labeling Scheme
⊥ : smallest label
т : largest label
last_label_rcvdX[Y] :
the last message that X received from Y after X has taken its last
permanent or tentative checkpoint. If not exists, ⊥is in it.
first_label_sentX[Y] :
the first message that X sent to Y after X took its last permanent or
tentative checkpoint . If not exists, ⊥is in it.
roll_cohortX :
the set of all processes that may have to roll back to the latest
checkpoint when process X rolls back.
last_label_sentX[Y] :
the last message that X sent to Y before X takes its latest permanent
checkpoint. If not exist, т is in it.
~Synchronous Recovery~](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-26-320.jpg)
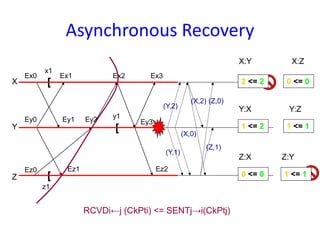
![Recovery Algorithm
roll_cohortX = { Y | X can send messages to Y }
Y will restart from the permanent checkpoint only if
last_label_rcvdY[X] > last_label_sentX[Y]
~Synchronous Recovery~](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-27-320.jpg)
![Recovery Algorithm
Algorithm
1. an initiator requests p ∈ roll_cohort to prepare to rollback ( this
message includes last_label_sent[reciever] of sender )
2. if the processes that receive the request need to rollback, they
do the same as 1.; otherwise, return OK message.
3. they wait for receiving OK from all of p ∈ ckpt_cohort.
4. if the initiator learns p ∈ roll_cohort have succeeded, it decides
to rollback; otherwise, not to rollback.
5. it informs p ∈ roll_cohort of the decision
6. the processes that receive the decision act accordingly
~Synchronous Recovery~](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-28-320.jpg)
![Diagram of Synchronous Recovery
[
[
[
[
A
C
B
D
ab1 ac1
bd1
dc1 dc2
cb1
ba1 ba2
ac2cb2
dc1
request to
roll back
0 > 1
last_label_rcvdY[X] > last_label_sentX[Y]
2 > 1
0 >т
OK
[
[
2 > 1
0 >т
[
decide to
roll back
roll_cohortX = { Y | X can send messages to Y }](https://image.slidesharecdn.com/unitiv-151031072021-lva1-app6892/85/CS9222-ADVANCED-OPERATING-SYSTEMS-29-320.jpg)


























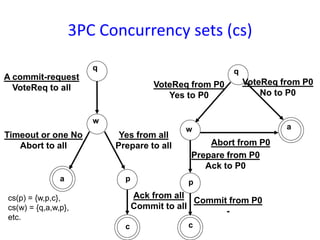








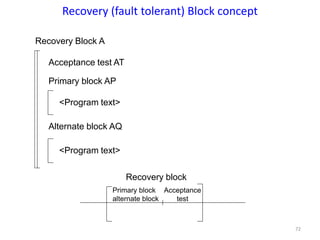
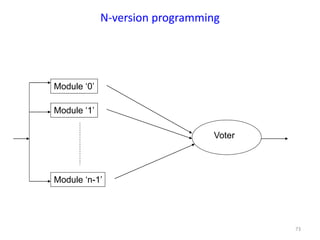


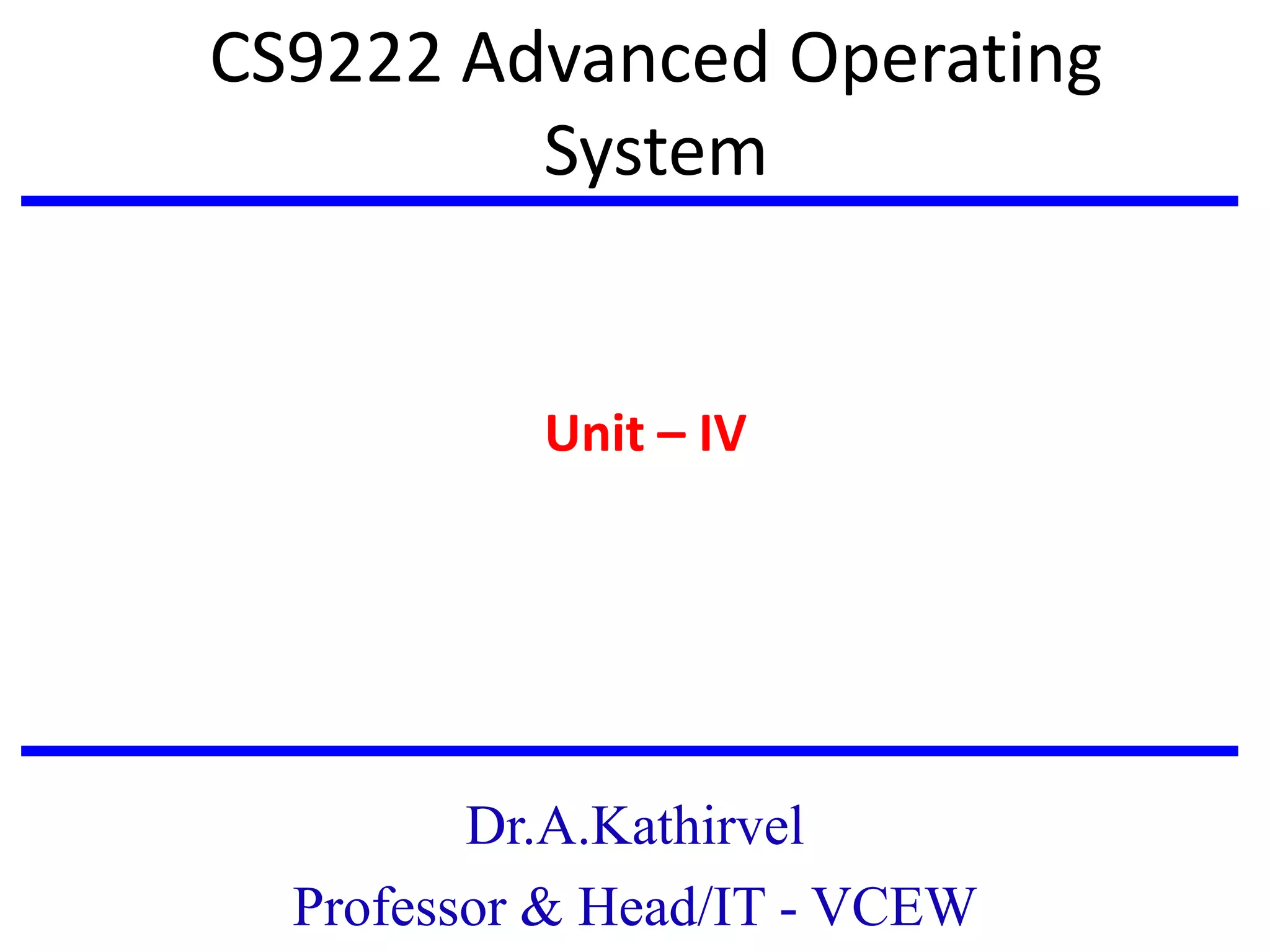
The document discusses advanced concepts in recovery mechanisms for computer systems, particularly focusing on various failure types and recovery strategies like synchronous and asynchronous checkpointing. It elaborates on the challenges of process failures, system failures, and communication failures, along with methods to ensure fault tolerance and data integrity in distributed systems. Key recovery methods include forward and backward error recovery, checkpointing strategies, and the implications of concurrent processes on recovery protocols.































































































