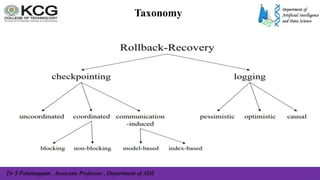
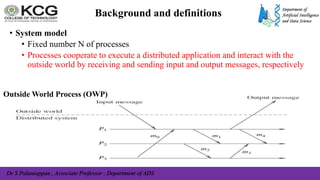
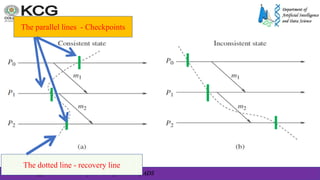
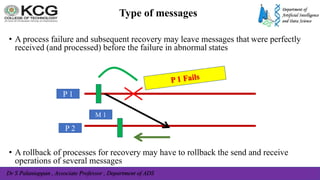
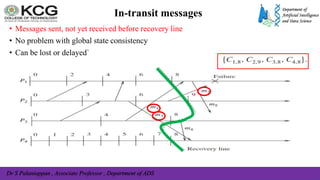
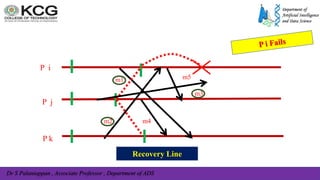
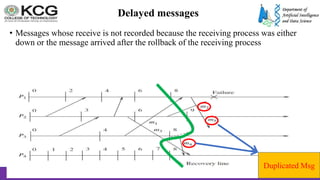
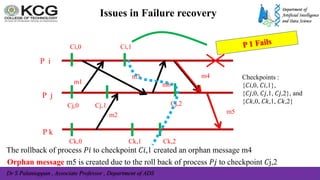
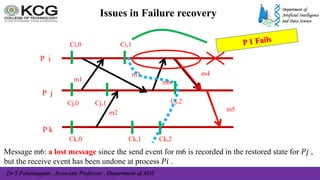
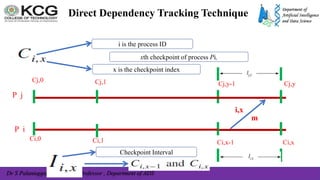
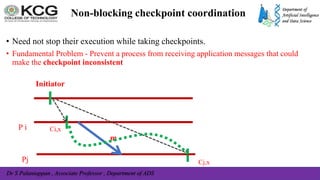
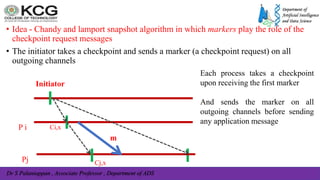
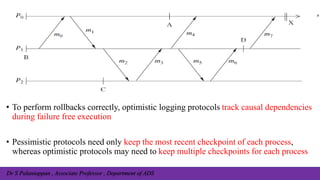
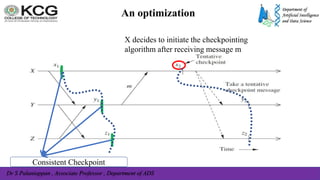
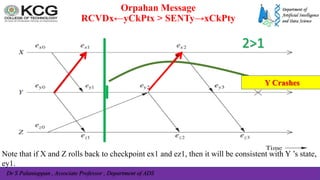
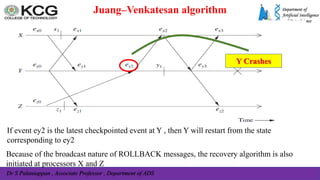
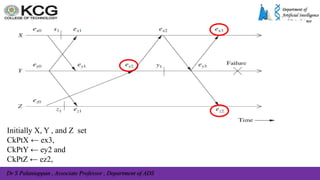
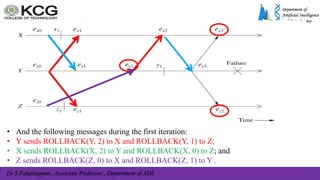
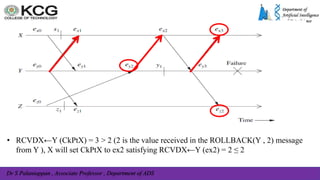
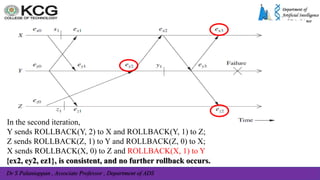
The document, authored by Dr. S. Palaniappan, covers topics related to recovery and consensus in distributed systems, emphasizing the importance of fault tolerance and rollback recovery methods. It discusses checkpointing techniques, including independent and coordinated checkpointing, and the implications of the domino effect during rollbacks. Additionally, it explores log-based rollback recovery and various algorithms designed to ensure consistent states in distributed applications.




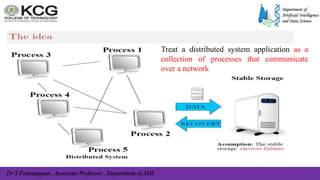




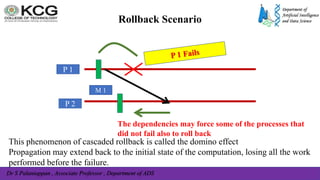
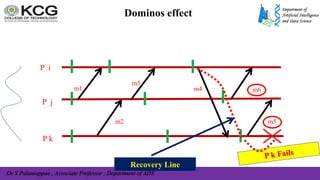
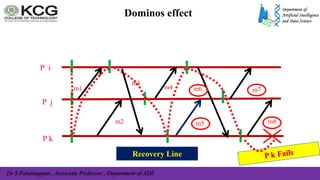



































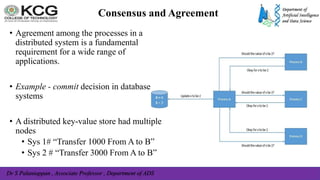





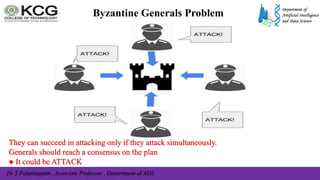
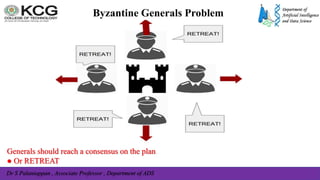


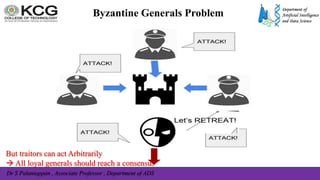





![Dr S Palaniappan , Associate Professor , Department of ADS
The interactive consistency problem
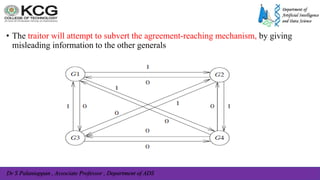
• The interactive consistency problem differs from the Byzantine agreement problem
in that each process has an initial value, and all the correct processes must agree
upon a set of values, with one value for each process.
• Agreement All non-faulty processes must agree on the same array of values
A[v1…vn].
• Validity If process i is non-faulty and its initial value is vi, then all non faulty
processes agree on vi as the ith element of the array A. If process j is faulty, then the
non-faulty processes can agree on any value for Aj.
• Termination Each non-faulty process must eventually decide on the array A.](https://image.slidesharecdn.com/unitiv-240709080815-1c6503d6/85/unit-3-all-about-the-data-science-process-covering-the-steps-present-in-almost-every-data-science-project-85-320.jpg)






































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
