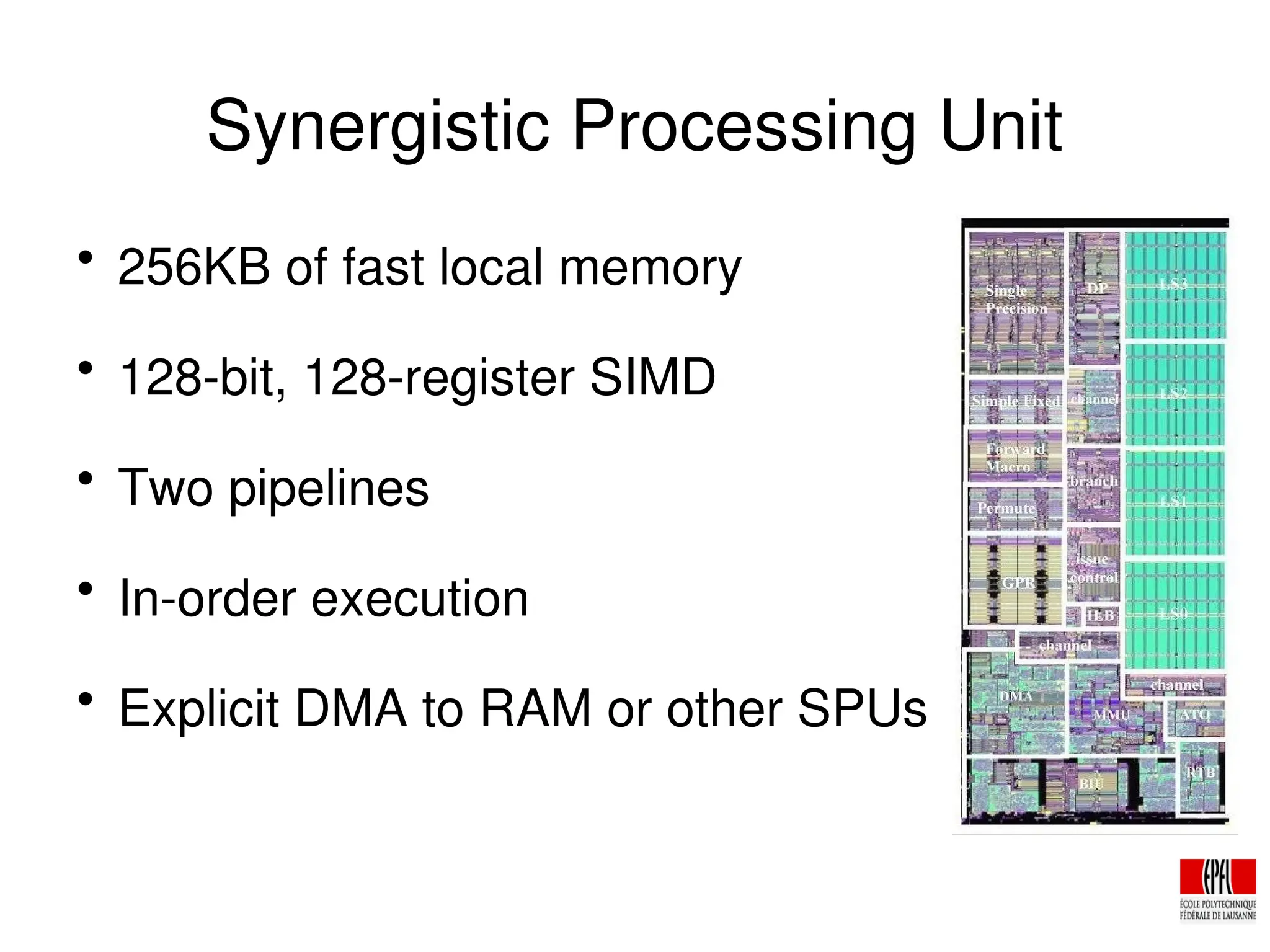
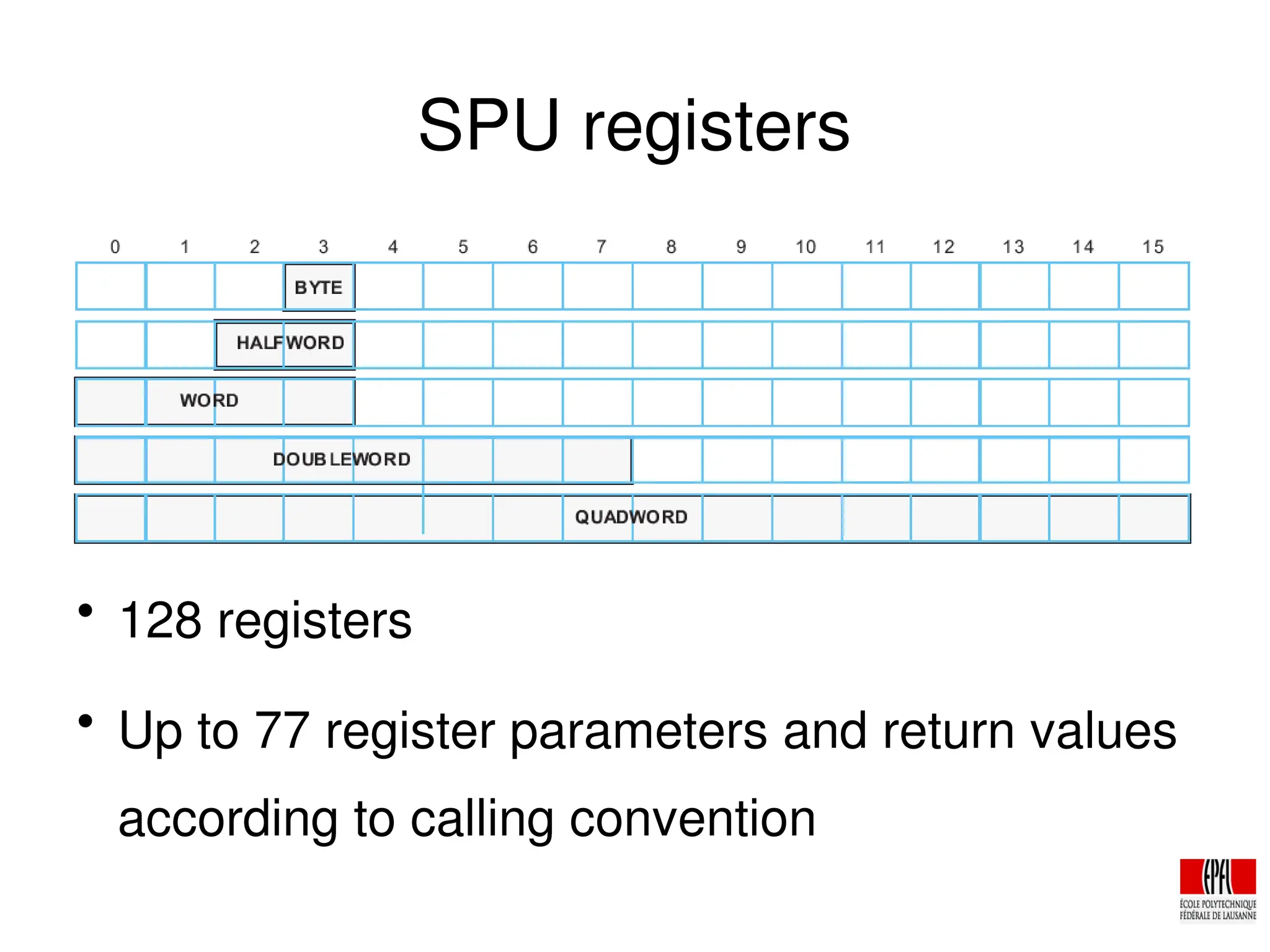
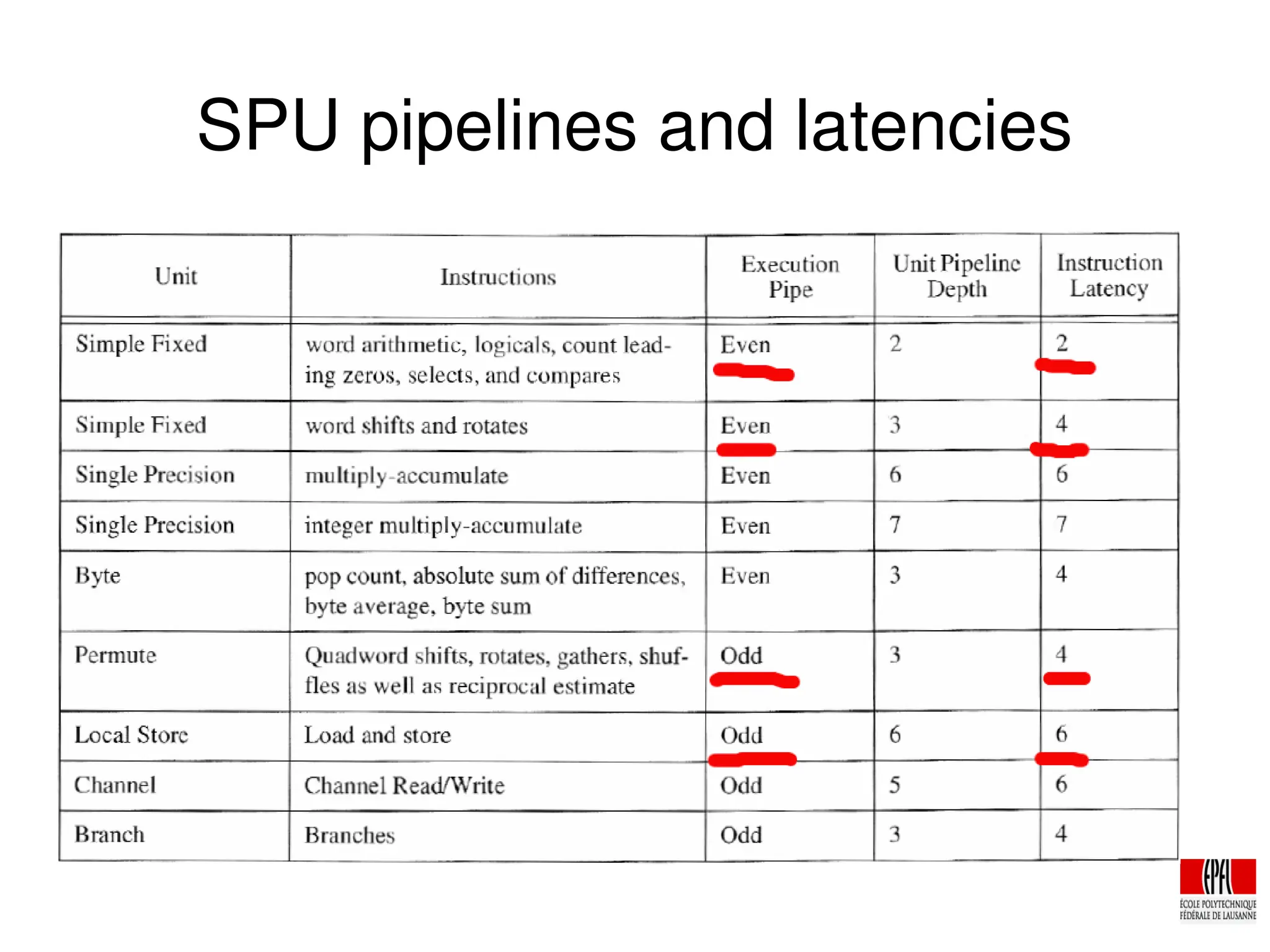
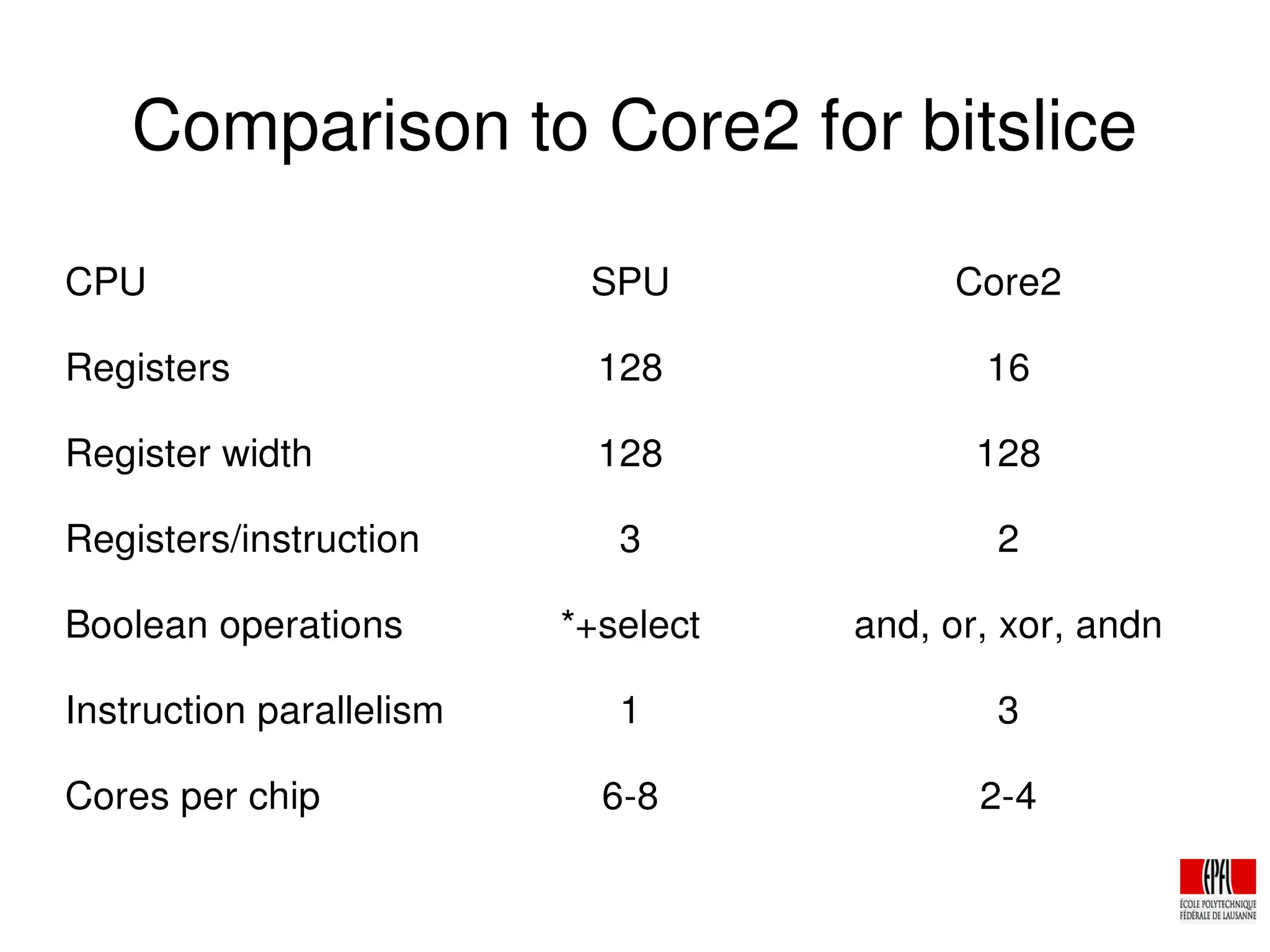
The document discusses the cryptologic applications of the PlayStation 3's Cell Broadband Engine, detailing its architecture, including the use of synergistic processors for cryptographic tasks like breaking DES and running AES with high throughput. It highlights performance metrics, such as the ability to perform 108 million keys/sec for DES and over 2.1 Gbit/sec for AES per SPU. Additionally, the document explores the potential future developments for the Cell, emphasizing enhancements in microarchitecture and memory capabilities to better support cryptographic applications.
























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
