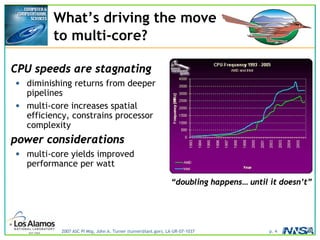
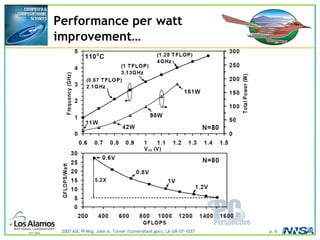
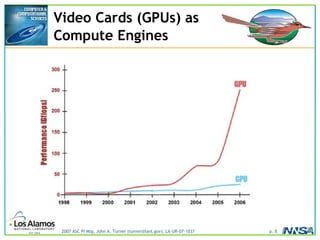
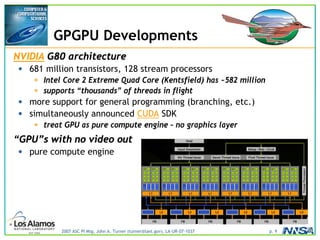
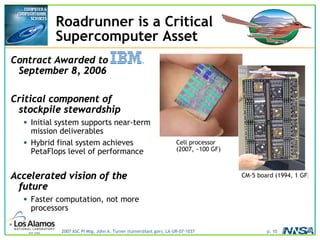
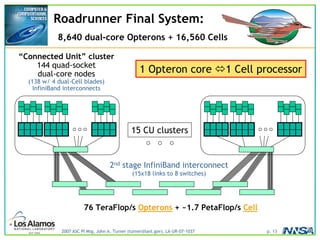
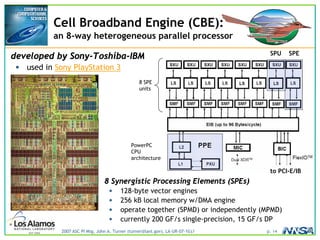
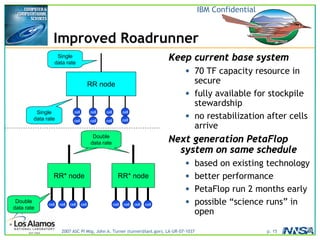
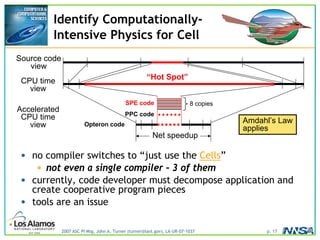
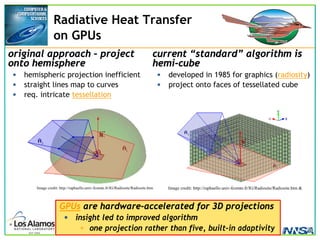
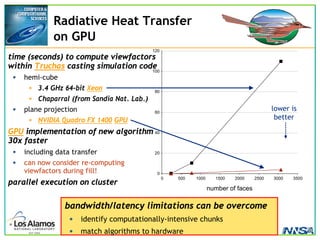
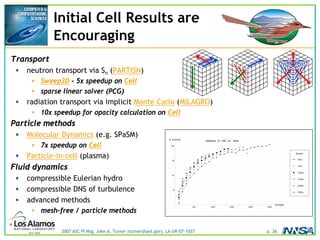
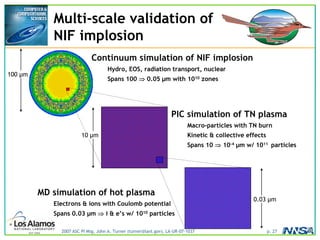
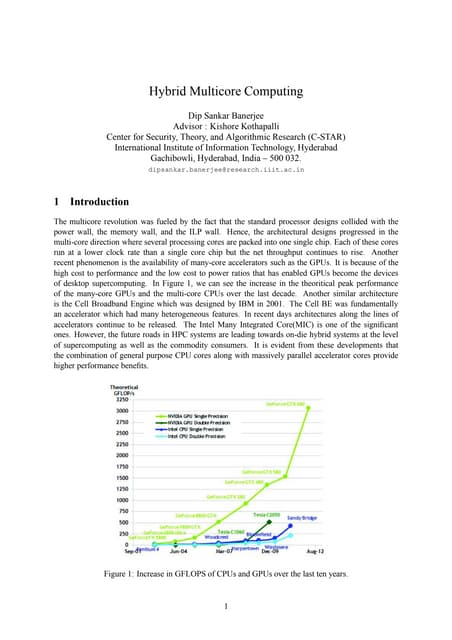
The document discusses the development of the Roadrunner supercomputer, emphasizing the transition to heterogeneous petascale computing for predictive simulations. It highlights the shift towards multi-core architectures, challenges of memory access, and the need for advanced hybrid programming strategies. The Roadrunner system, integrating dual-core Opterons and Cell processors, aims to enhance computational capacity for Los Alamos National Laboratory's missions, achieving petaflops performance through innovative algorithms and hardware utilization.