Downloaded 50 times








![Network Address Migration Pod attached to virtual interface with own IP & MAC addr. Implemented by using Linux’s virtual interfaces (VIFs) IP address assigned statically or through a DHCP client running inside the pod (using pod’s MAC address) Intercept bind() & connect() to ensure pod processes use pod’s IP address Migration: delete VIF on source host & create on new host Migration limited to subnet eth0 [IP-1, MAC-h1] eth0:1 Pod DHCP Server Network DHCP Client 1. ioctl() 2. MAC-p1 3. dhcprequest(MAC-p1) 4. dhcpack(IP-p1)](https://image.slidesharecdn.com/dsn2005-1224475894318540-8/75/Cruz-Application-Transparent-Distributed-Checkpoint-Restart-on-Standard-Operating-Systems-10-2048.jpg)

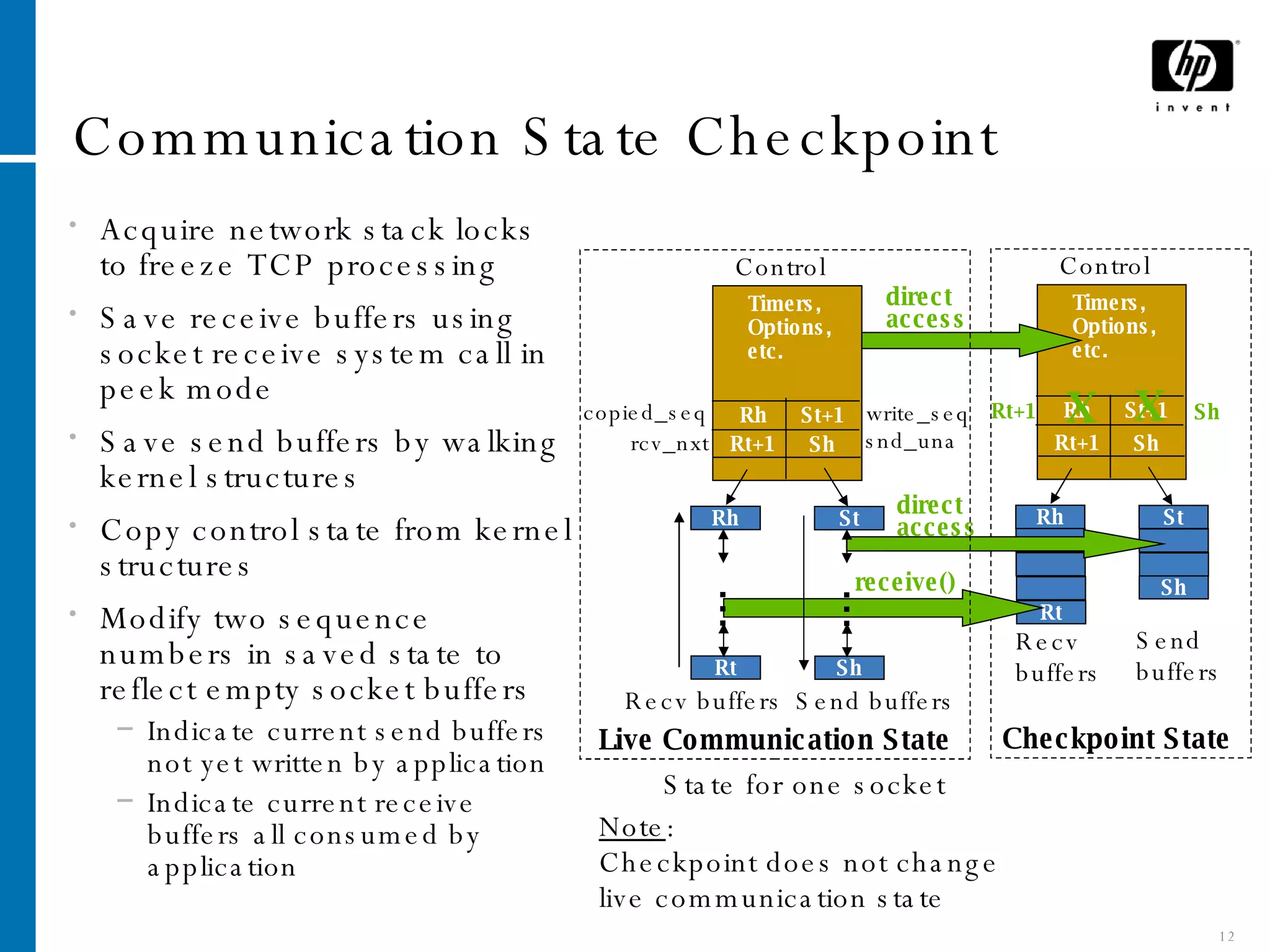
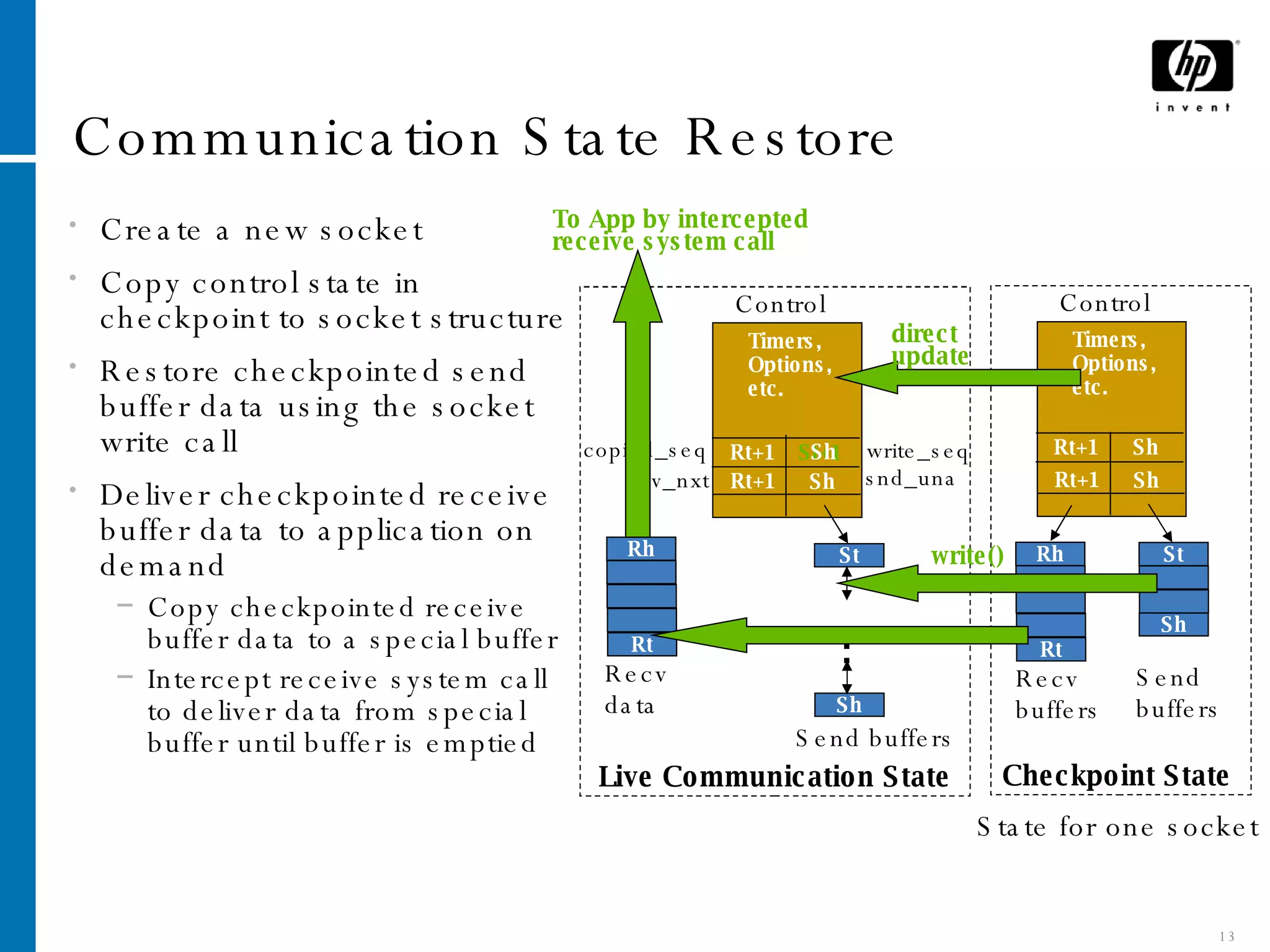

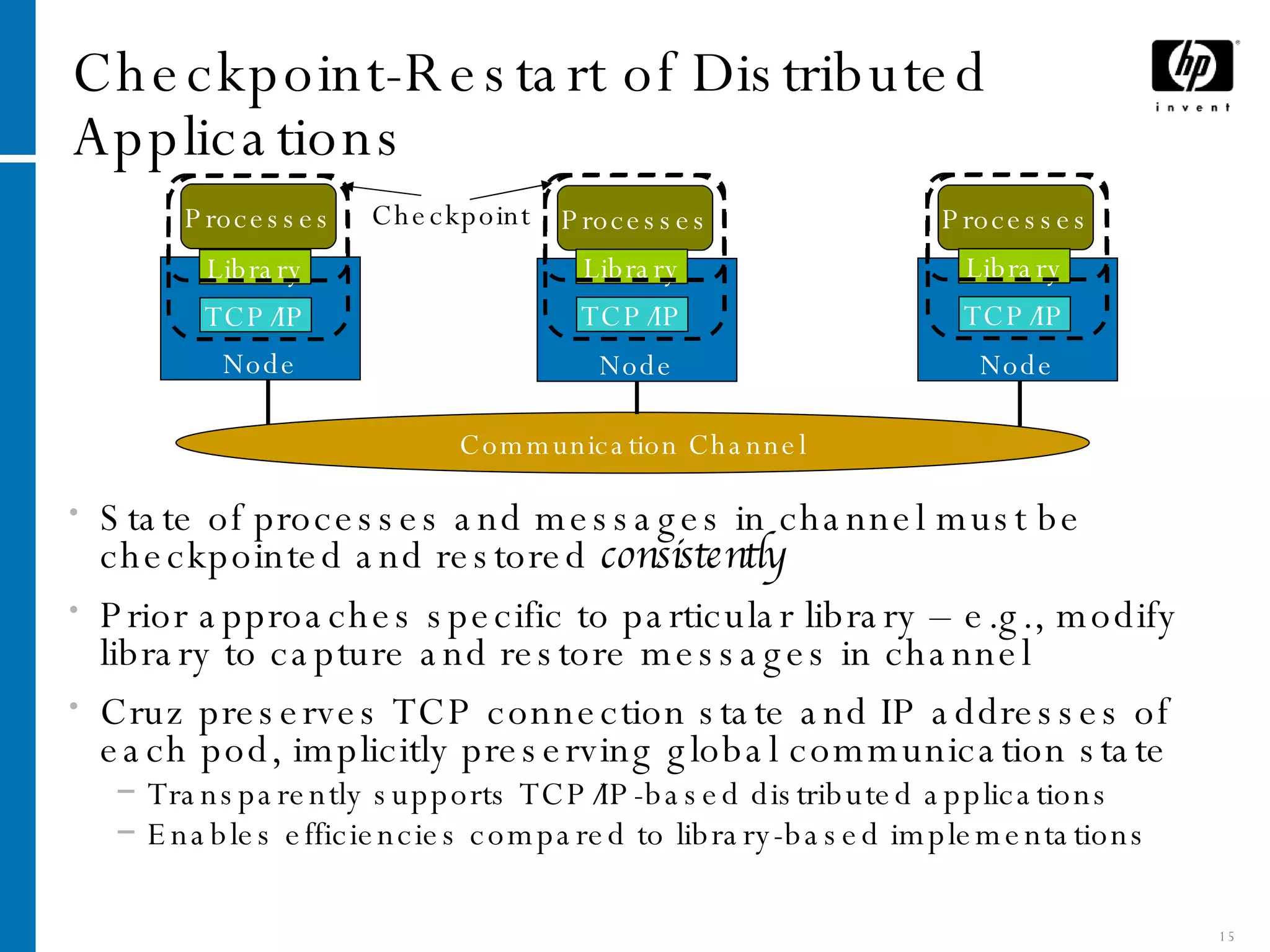












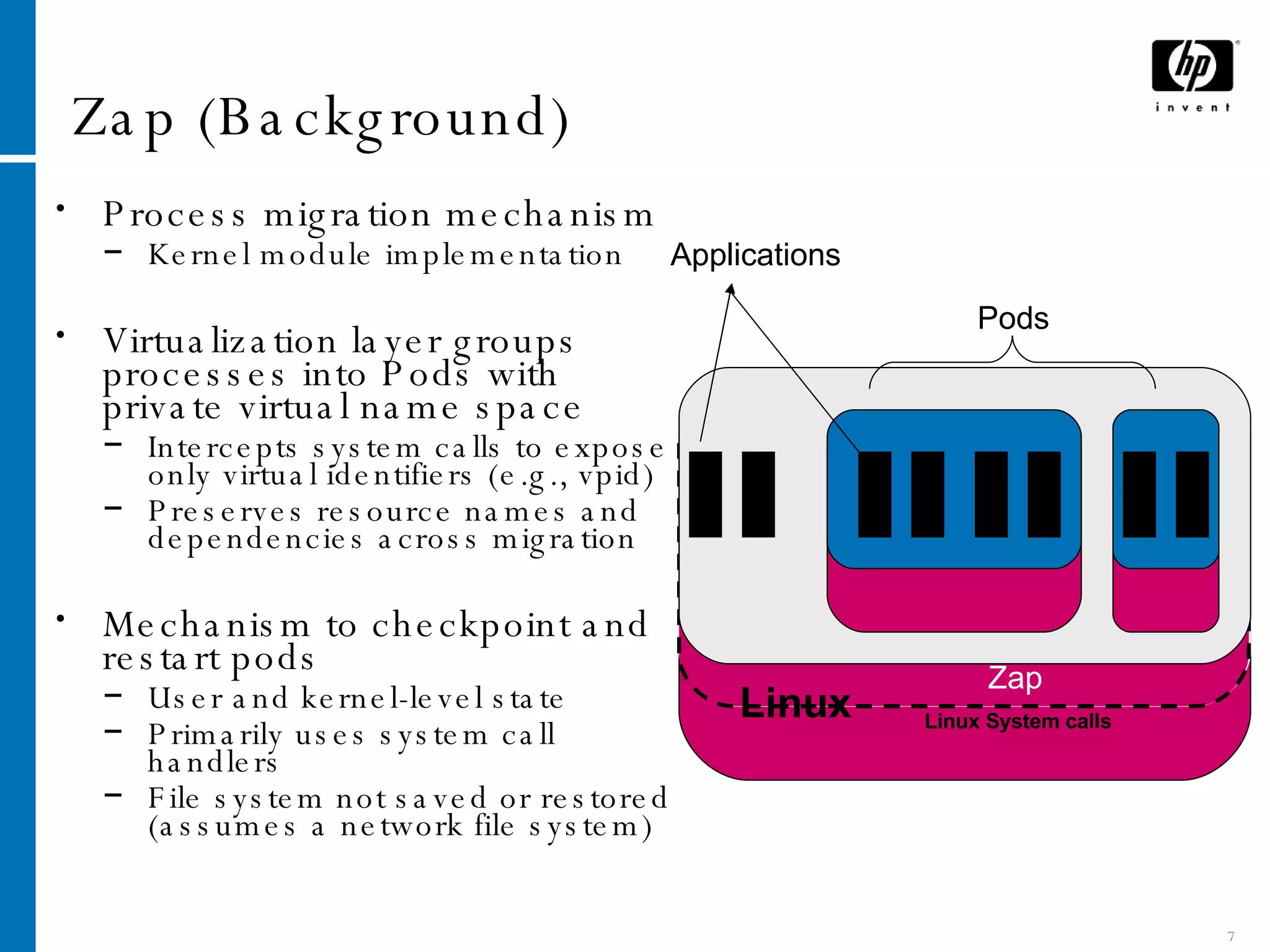
The document summarizes Cruz, a system that provides application-transparent distributed checkpoint-restart on standard operating systems. Cruz uses a kernel module to checkpoint and restart unmodified applications and their distributed communication state. It migrates networked applications in a way that is transparent to remote peers by preserving each application's IP address and TCP connection state across migrations. Cruz enables fault tolerance, planned downtime reduction, and resource management for distributed applications without requiring modifications to applications or use of specialized systems.












































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















