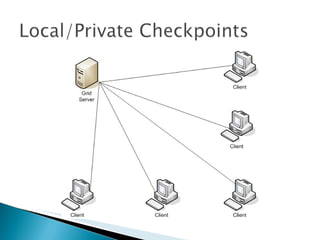
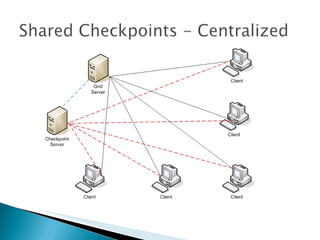
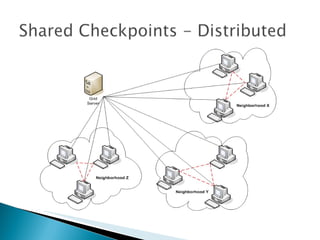
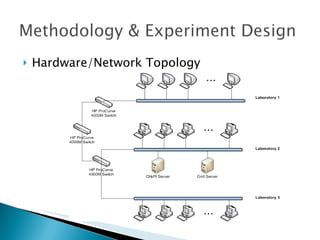
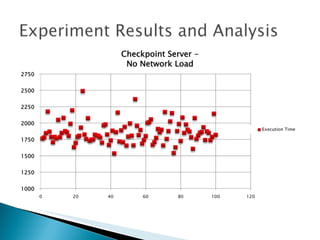
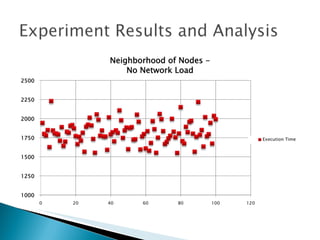
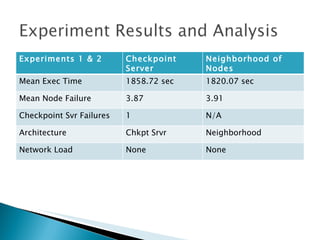
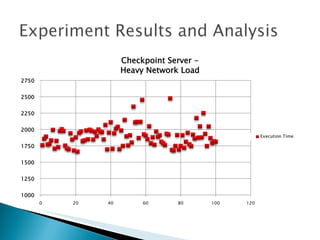
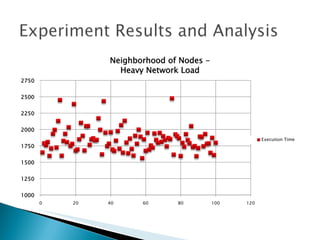
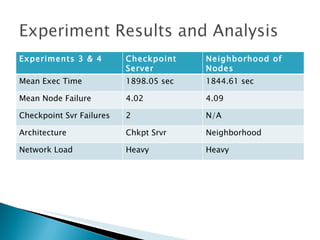
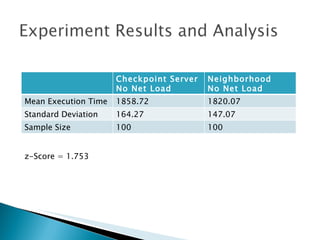
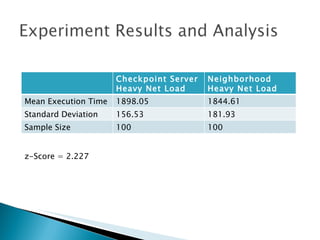
The document summarizes a dissertation defense presentation on using distributed shared checkpoints to improve completion times in desktop grid applications. The presentation introduces the topic, research problem of client failures degrading performance in desktop grids, and a methodology to test if using distributed shared checkpoints between neighboring nodes improves completion times over a centralized checkpoint server. Experimental results show distributed checkpoints significantly reduced completion times even with heavy network loads. Future work is suggested to further optimize the neighborhood approach.