Downloaded 33 times


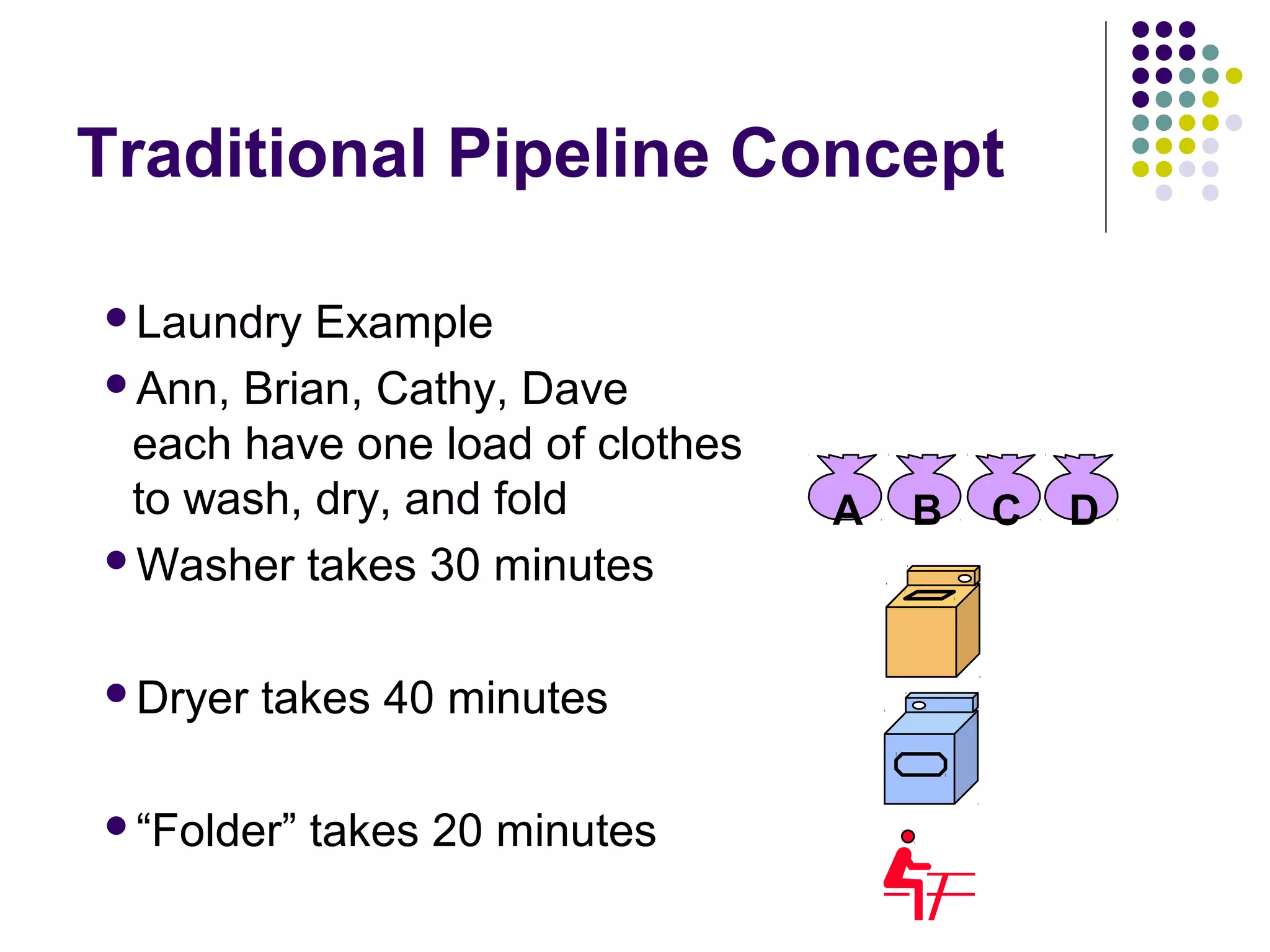
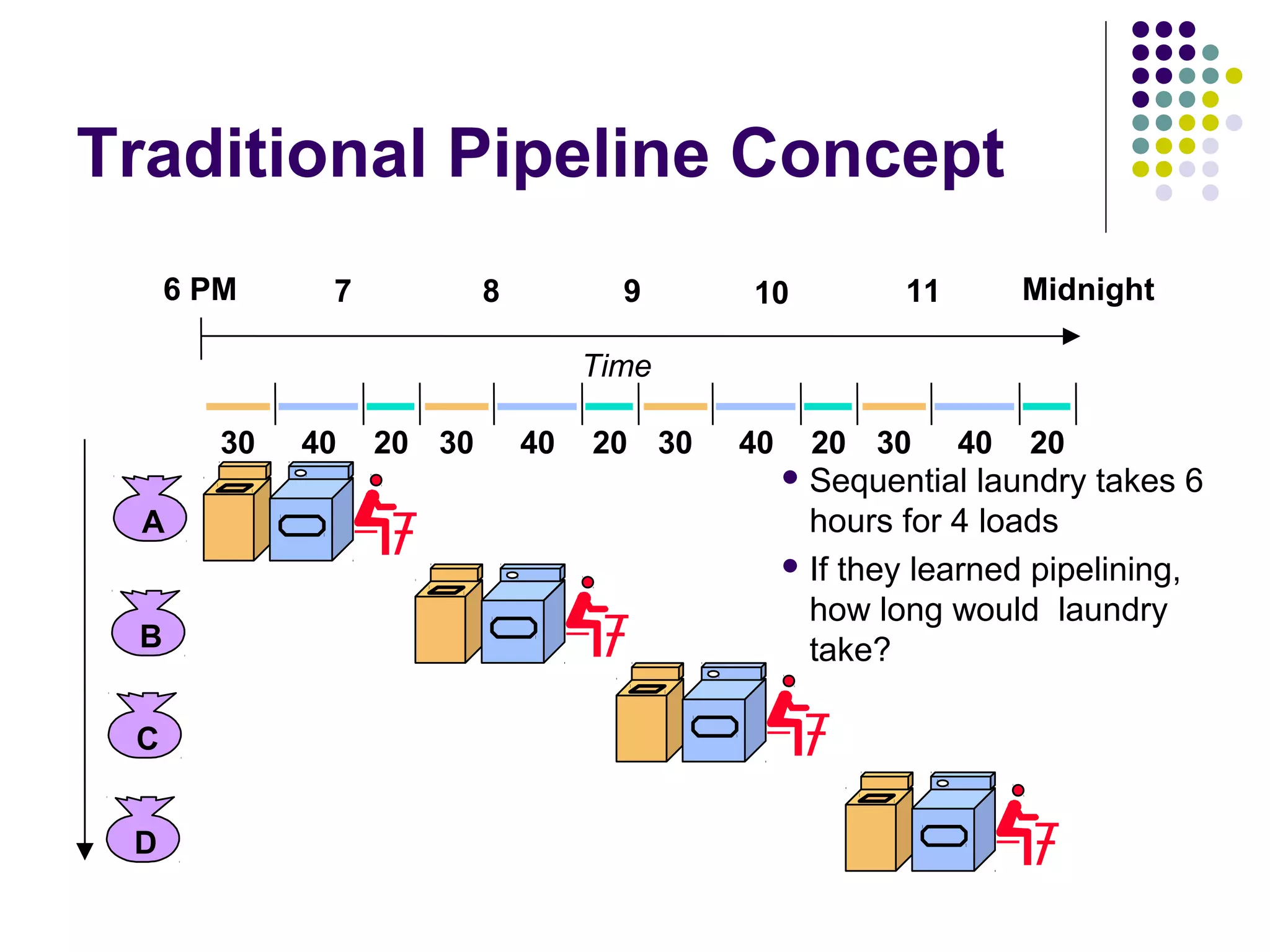
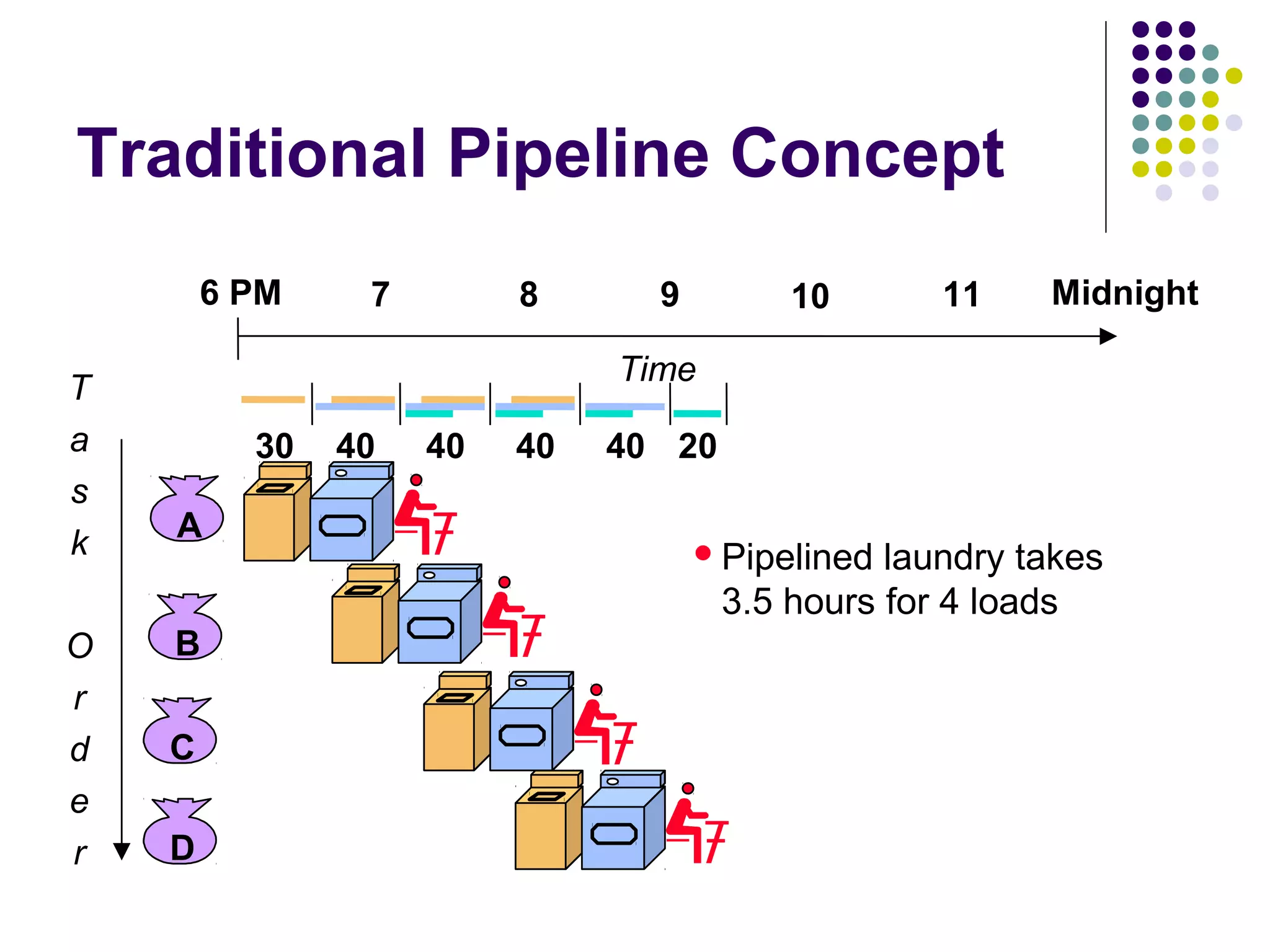
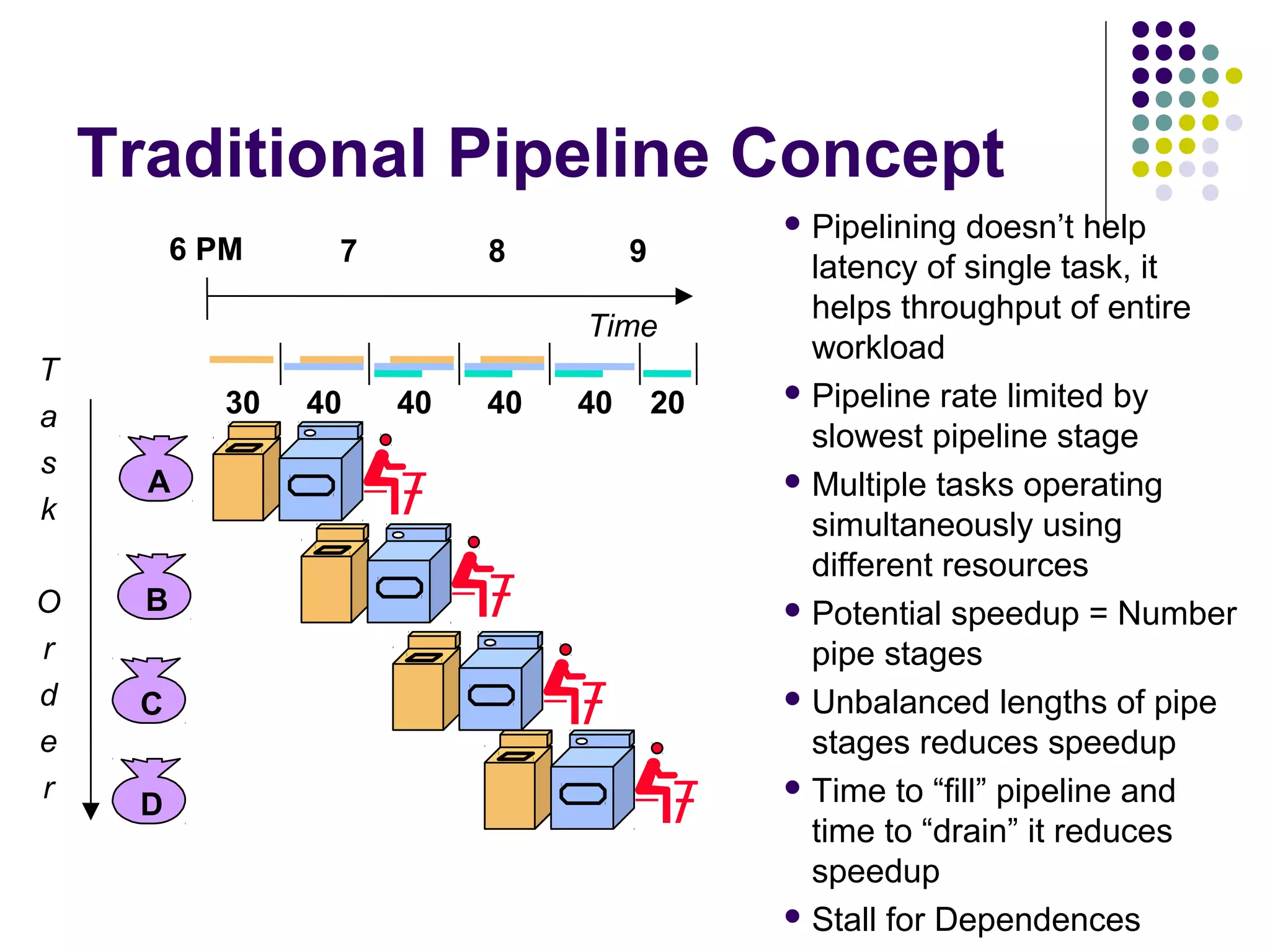
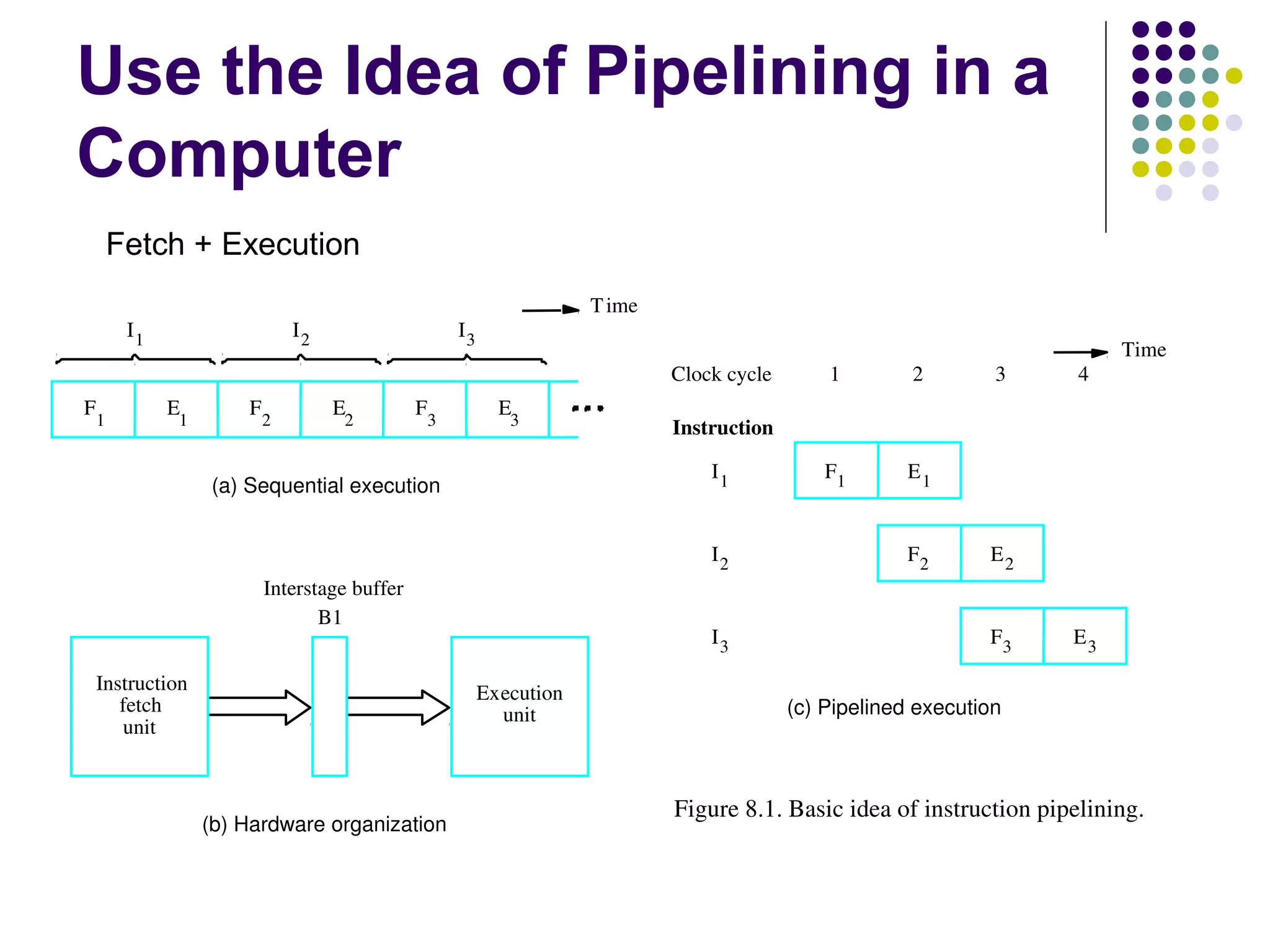
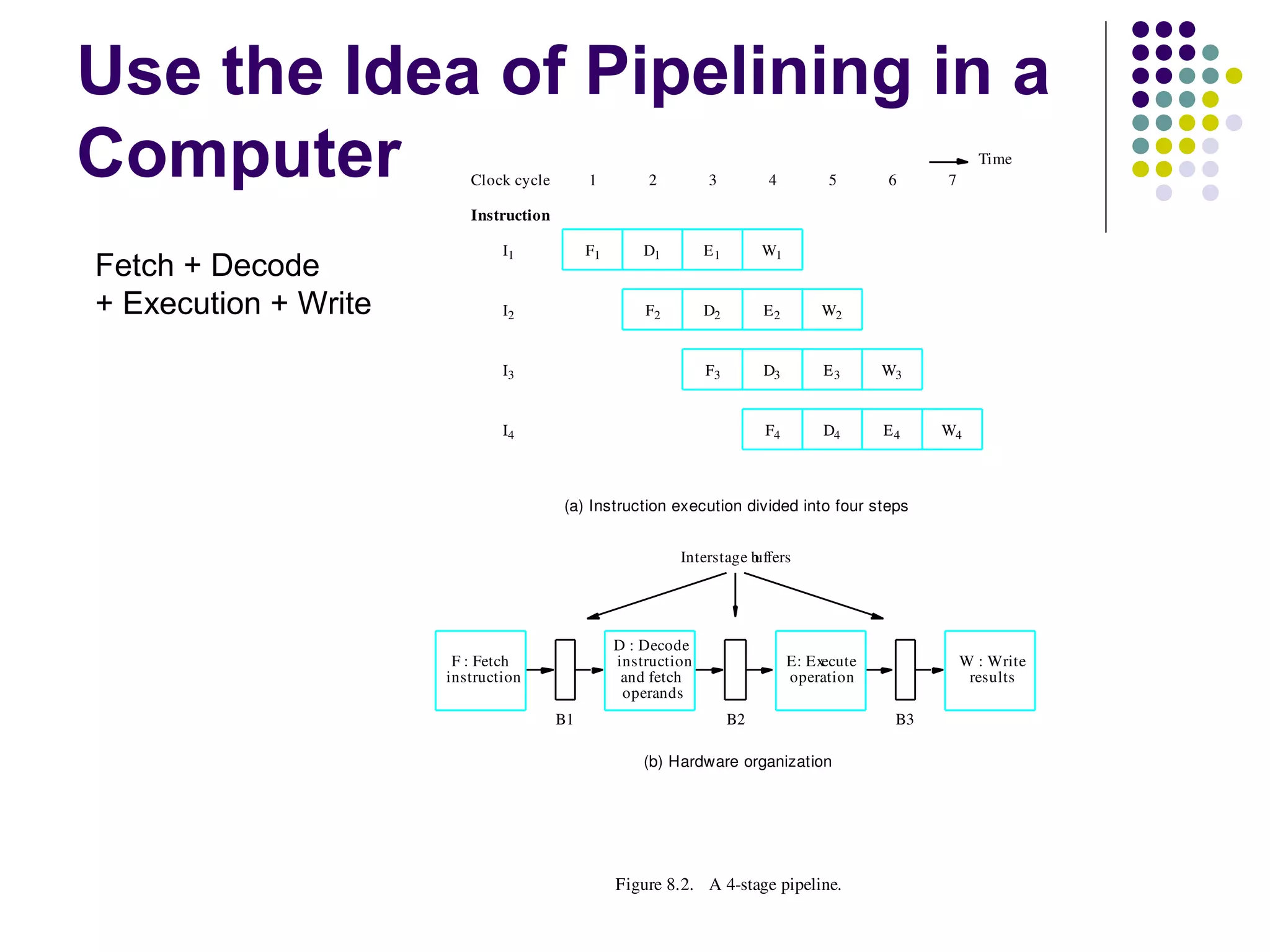


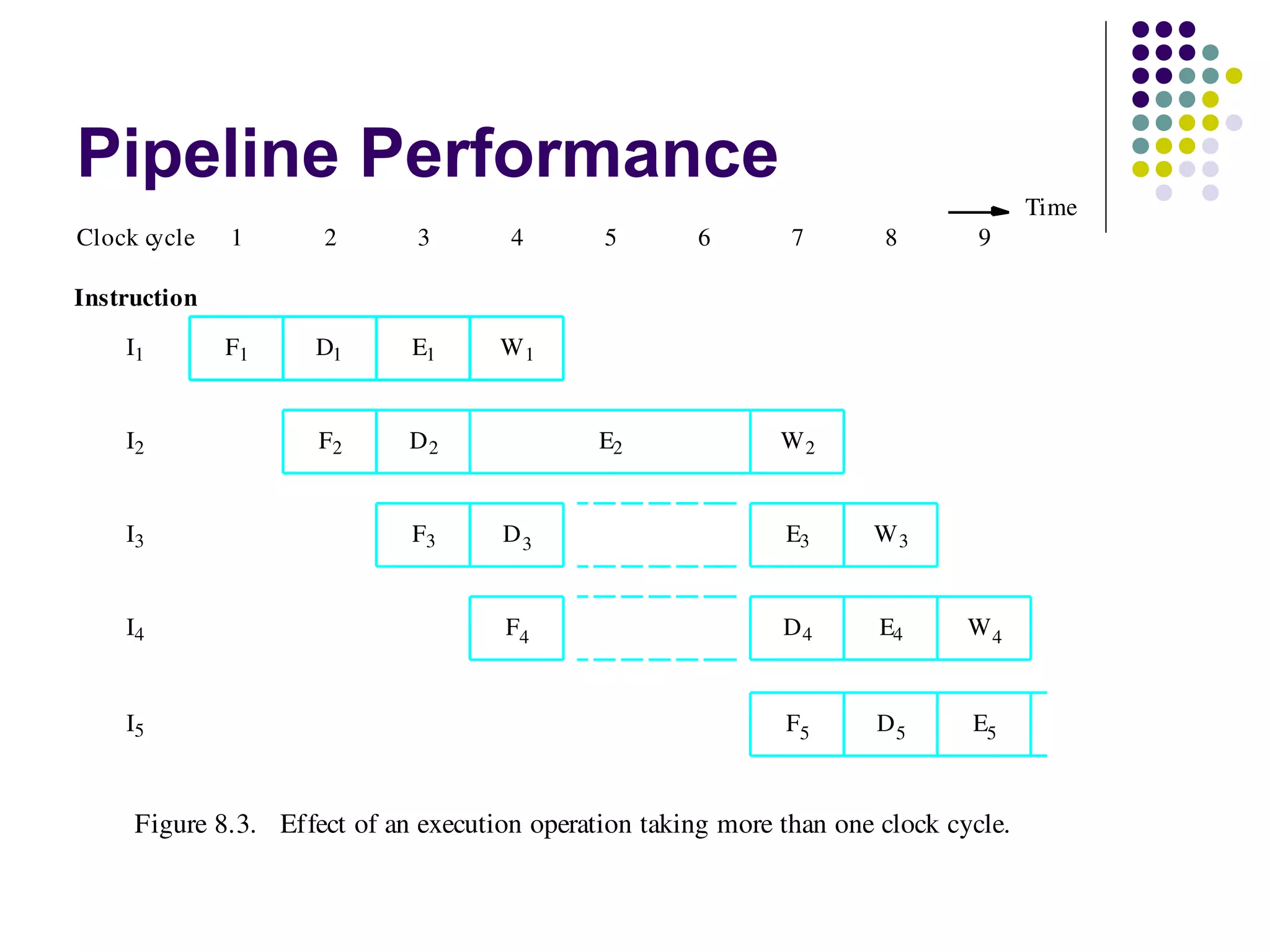







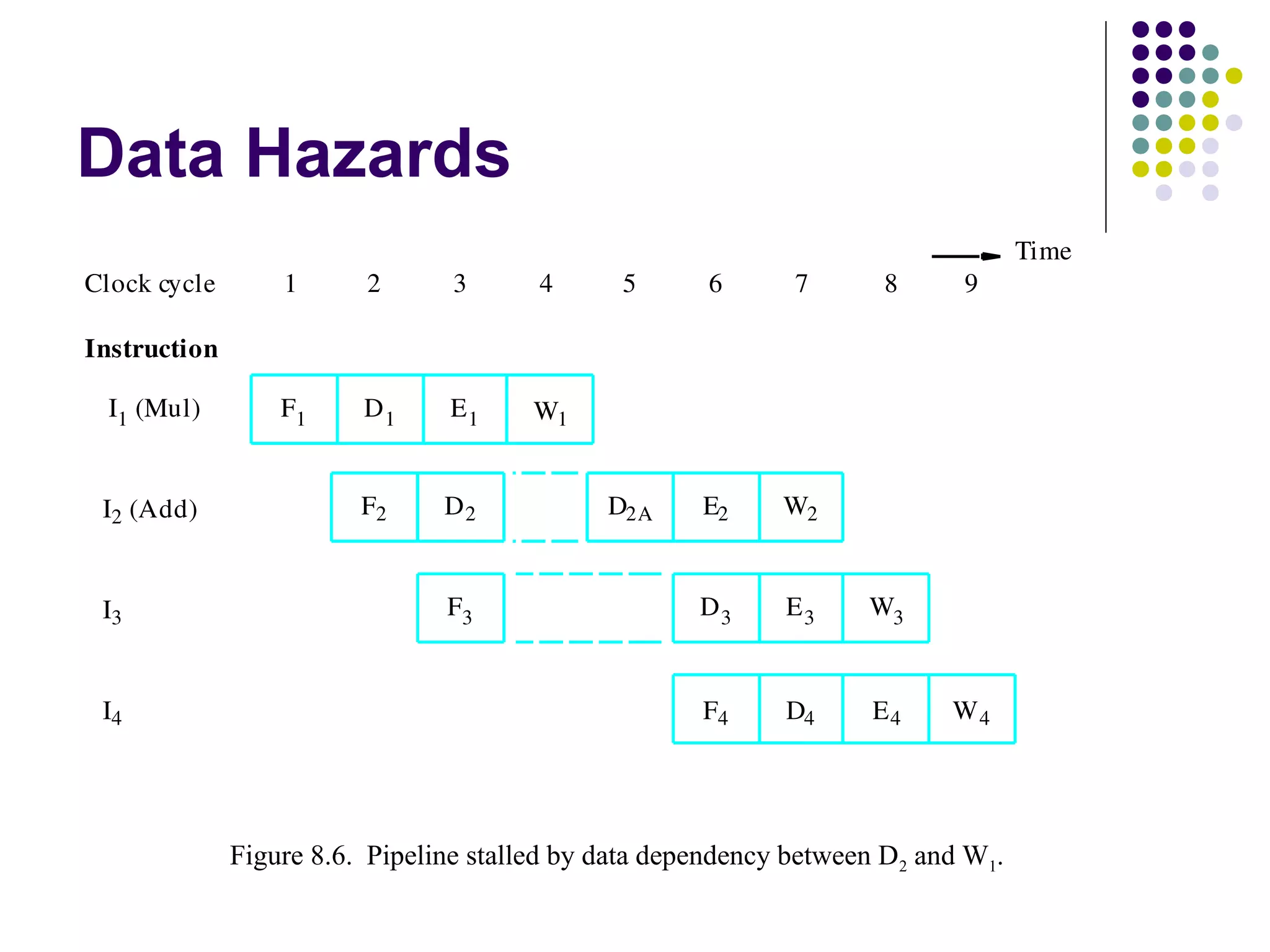

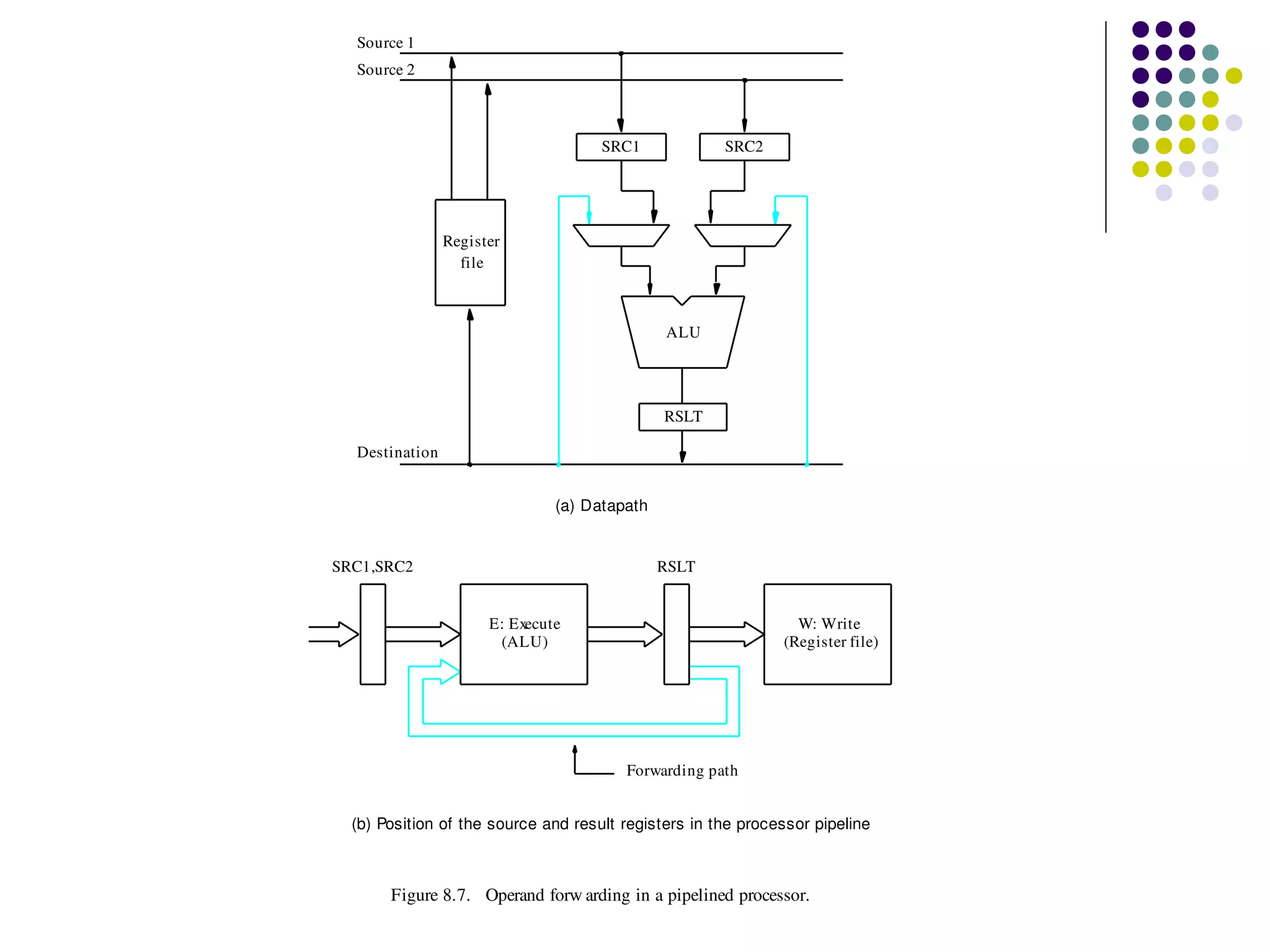




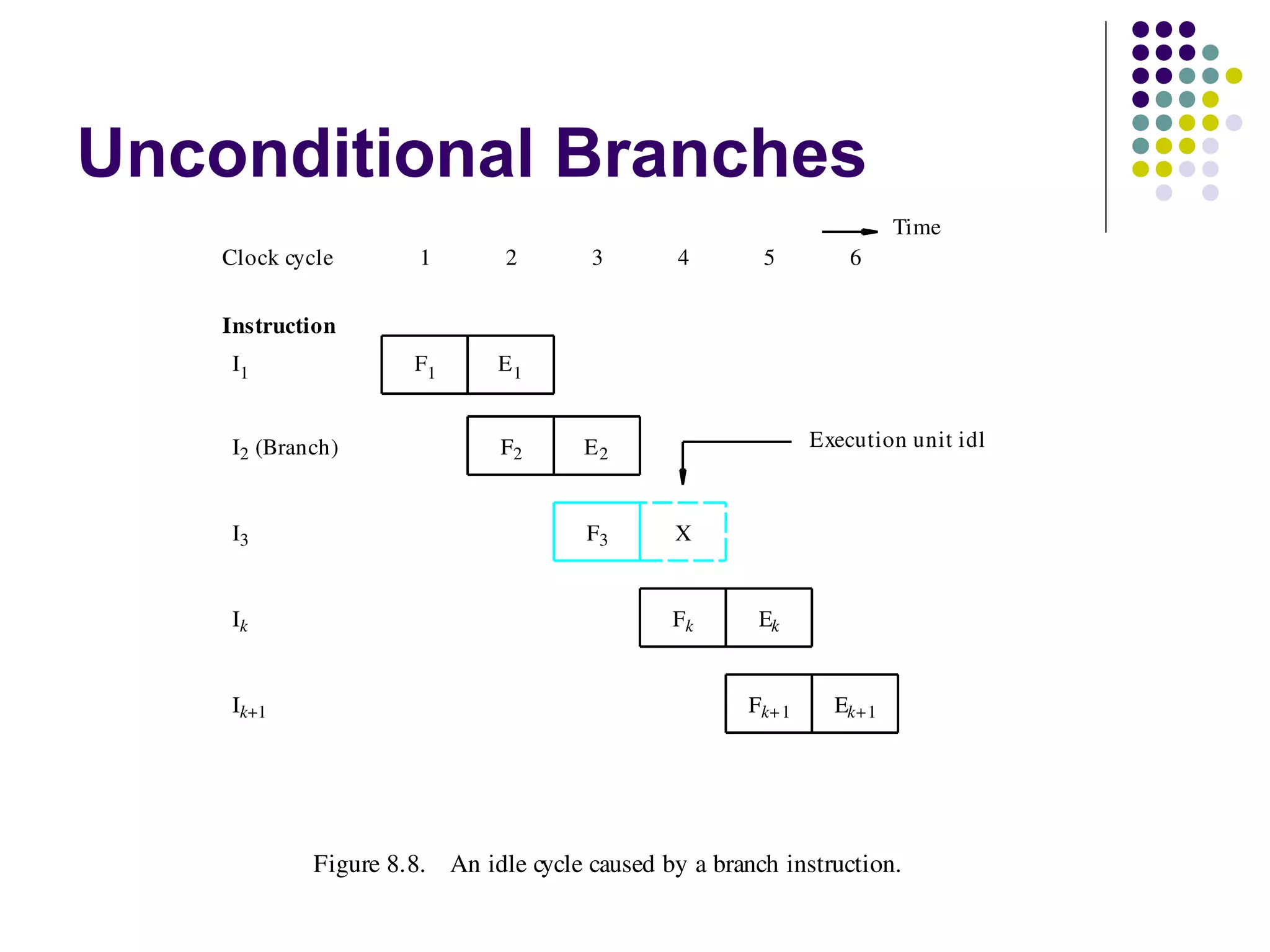
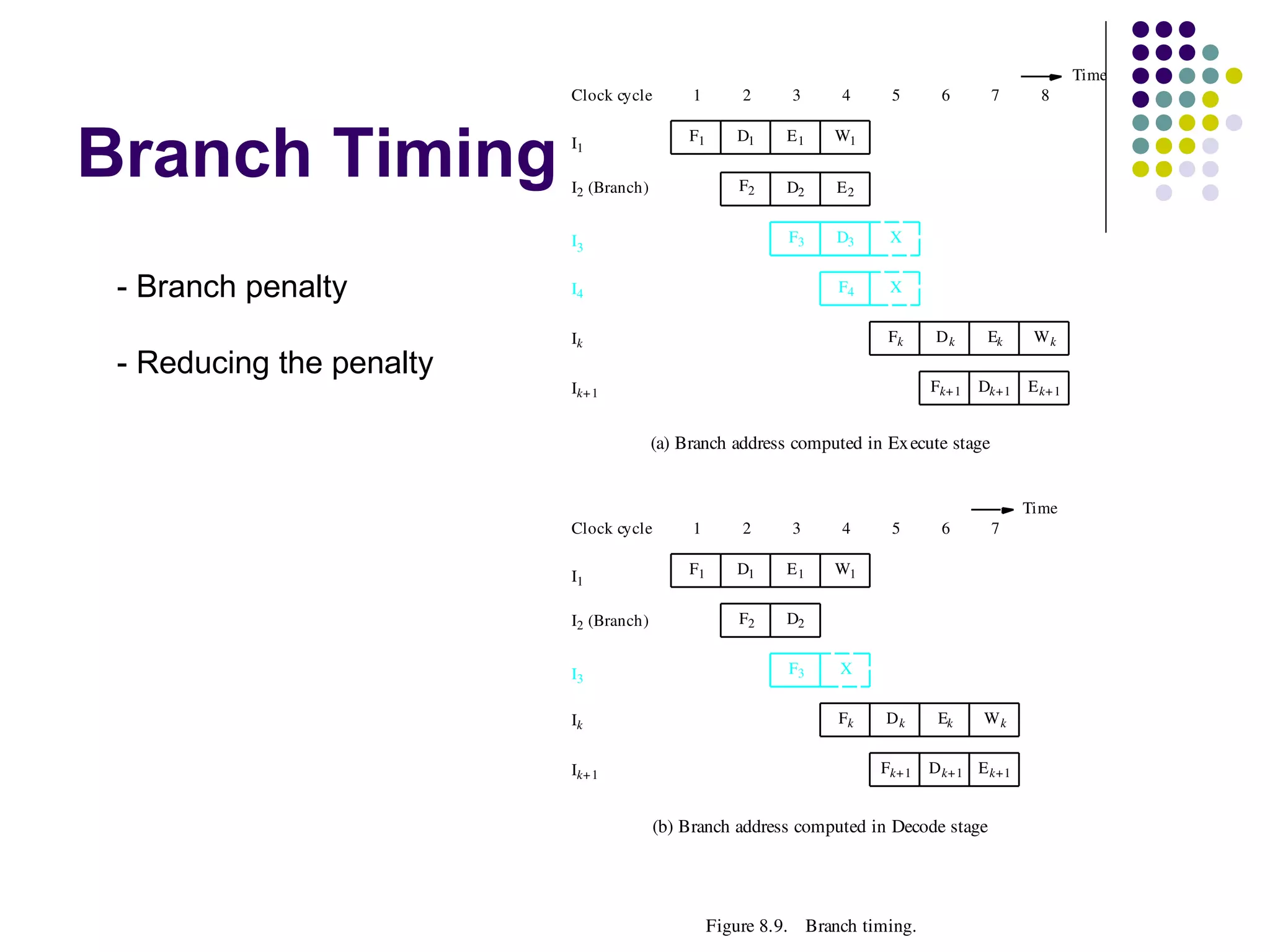
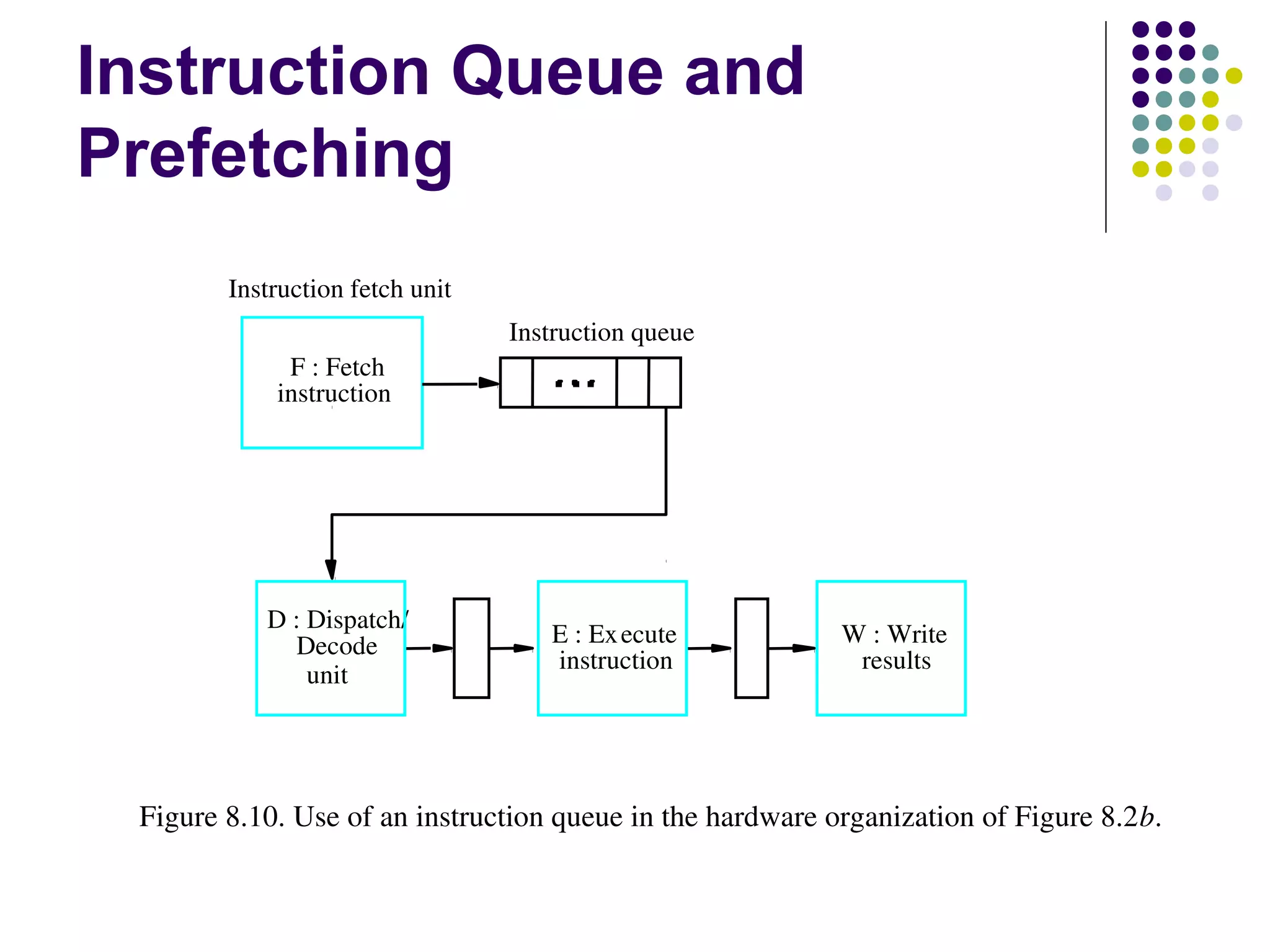


Pipelining is a technique used in modern processors to enhance performance by increasing throughput through simultaneous execution of multiple operations. It breaks instruction execution into stages, but requires careful management to avoid hazards like data and instruction stalls that can degrade performance. Pipelining's effectiveness relies on balancing pipeline stages and minimizing stalls to maintain high instruction throughput.




















































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)














