Recommended
PPTX
Windows HPC Server 講習会 第1回 導入編 1/2
PPT
Notes on the low rank matrix approximation of kernel
PDF
PPTX
Windows HPC Server 講習会 第2回 開発編
PPT
PDF
Windows Store アプリをuniversal にして申請する手順
PDF
Stochastic Process Overview (hypothesis)
PPTX
Vanishing Component Analysisの試作(補足)
PDF
DSIRNLP06 Nested Pitman-Yor Language Model
PDF
PPTX
PDF
On the eigenstructure of dft matrices(in japanese only)
PPTX
PPTX
Vanishing Component Analysisの試作と簡単な実験
PDF
PPTX
Go-ICP: グローバル最適(Globally optimal) なICPの解説
PPTX
KeyGraph Analysis on NIPS2013 Papers
PDF
Variational Kalman Filter
PDF
PDF
Holonomic Gradient Descent
PDF
Swift 2 (& lldb) シンポジウム
PPTX
PPTX
FLAT CAM: Replacing Lenses with Masks and Computationの解説
PDF
Kernel entropy component analysis
PDF
PDF
PDF
WWW2018 論文読み会 Web Search and Mining
PDF
10回開催記念 「データマイニング+WEB ~データマイニング・機械学習活用による継続進化~」ー第10回データマイニング+WEB勉強会@東京ー #Toky...
PDF
リクルートライフスタイルにおける深層学習の活用とGCPでの実現方法
PPTX
Kaggle – Airbnb New User Bookingsのアプローチについて(Kaggle Tokyo Meetup #1 20160305)
More Related Content
PPTX
Windows HPC Server 講習会 第1回 導入編 1/2
PPT
Notes on the low rank matrix approximation of kernel
PDF
PPTX
Windows HPC Server 講習会 第2回 開発編
PPT
PDF
Windows Store アプリをuniversal にして申請する手順
PDF
Stochastic Process Overview (hypothesis)
PPTX
Vanishing Component Analysisの試作(補足)
Viewers also liked
PDF
DSIRNLP06 Nested Pitman-Yor Language Model
PDF
PPTX
PDF
On the eigenstructure of dft matrices(in japanese only)
PPTX
PPTX
Vanishing Component Analysisの試作と簡単な実験
PDF
PPTX
Go-ICP: グローバル最適(Globally optimal) なICPの解説
PPTX
KeyGraph Analysis on NIPS2013 Papers
PDF
Variational Kalman Filter
PDF
PDF
Holonomic Gradient Descent
PDF
Swift 2 (& lldb) シンポジウム
PPTX
PPTX
FLAT CAM: Replacing Lenses with Masks and Computationの解説
PDF
Kernel entropy component analysis
PDF
PDF
Similar to Sigir2013 retrieval models-and_ranking_i_pub
PDF
WWW2018 論文読み会 Web Search and Mining
PDF
10回開催記念 「データマイニング+WEB ~データマイニング・機械学習活用による継続進化~」ー第10回データマイニング+WEB勉強会@東京ー #Toky...
PDF
リクルートライフスタイルにおける深層学習の活用とGCPでの実現方法
PPTX
Kaggle – Airbnb New User Bookingsのアプローチについて(Kaggle Tokyo Meetup #1 20160305)
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
PDF
SIGIR2012勉強会 23 Learning to Rank
PDF
RecSys2023論文読み会_LLMRec_佐藤.pdf
PPTX
Optimizing Search Engines using Clickthrough Data
PPTX
Introduction to search_and_recommend_algolithm
PDF
PDF
PDF
WSDM2016報告会−論文紹介(Beyond Ranking:Optimizing Whole-Page Presentation)#yjwsdm
PDF
learningtorank meetup-vol4-pt1
PDF
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
PDF
PDF
PDF
Topic Model Survey (wsdm2012)
PDF
マイニング探検会#09 情報レコメンデーションとは
PDF
SIGIR2011読み会 3. Learning to Rank
PDF
Sigir2013 retrieval models-and_ranking_i_pub 1. 2. title list
H. Wang et al. Personalized ranking model
adaptation for web search
F. Raiber et al. Ranking document clusters
using markov random fields
J. H. Paik, A novel TF-IDF weighting
scheme for effective ranking
S. Kamali et al. Retrieving Documents with
mathematical content
3. title list
H. Wang et al. Personalized ranking model
adaptation for web search
F. Raiber et al. Ranking document clusters
using markov random fields
J. H. Paik, A novel TF-IDF weighting
scheme for effective ranking
S. Kamali et al. Retrieving Documents with
mathematical content
やたら複雑なTF-IDFやMathMLとか出てきて正直面白くなさそ
う..
4. Personalized Ranking Model
Adaptation for Web Search
概要
従来のパーソナライズ手法は各ユーザごとにリッチな履歴を必要としていて,
ユーザの興味の変化に対応できなかった.また,クエリとURLの間の関係を直
接学習するためにカバー率が低い,多くの手法がPRFベースのためにそもそも
1段目の検索で上位に来ない物はリランキング結果に出てこない等という問題
があった.そこで著者らはグローバルランキングモデルをパーソナライズする
手法を提案.加えて,ユーザの興味の変化の早さに追随するために適応効率に
ついても考慮している.
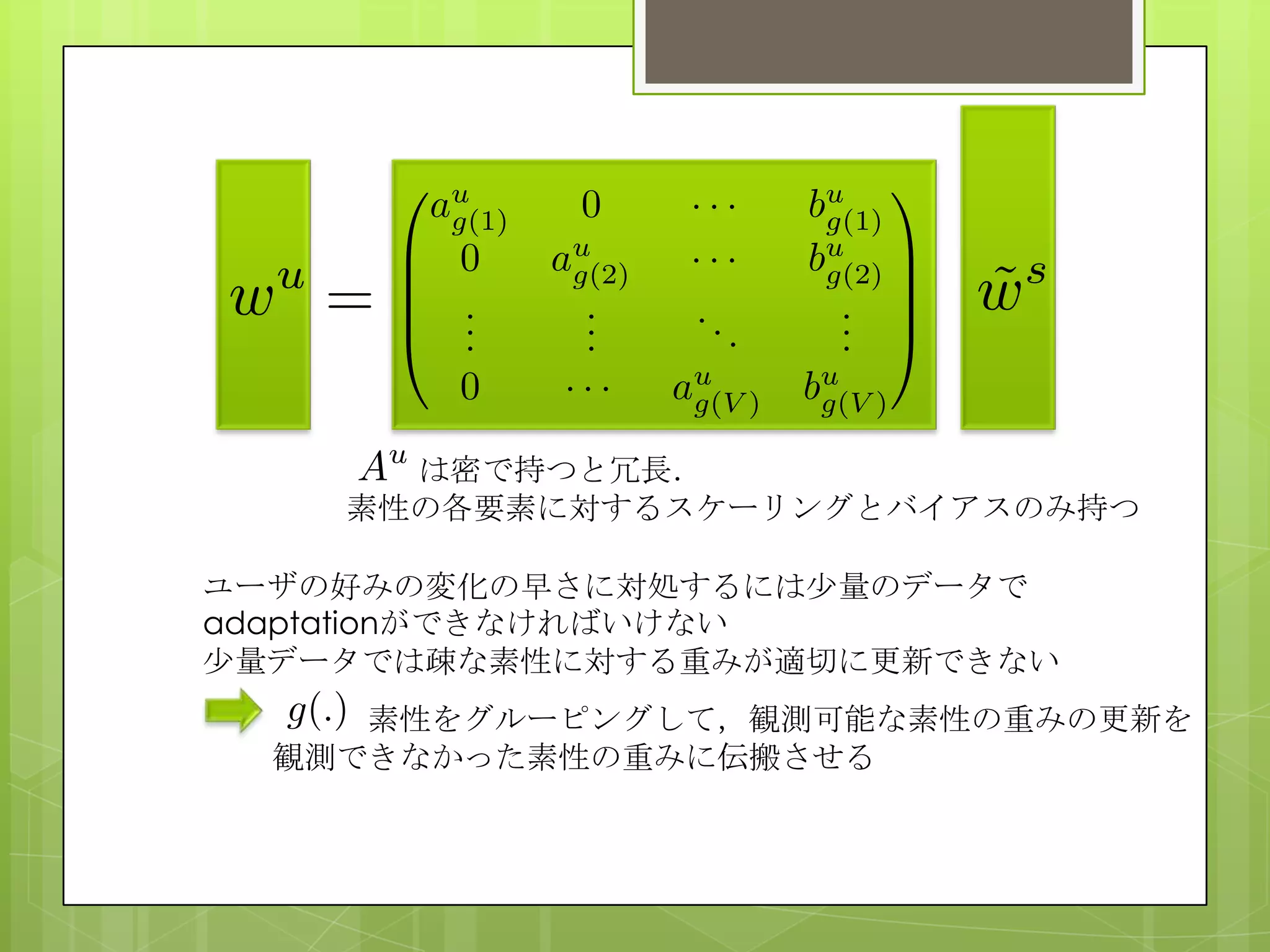
提案手法では,グローバルランキングモデルのパラメータに線形変換を掛ける
ことでパーソナライズモデルを作る.ユーザごとに変換行列を密で持つのは上
長なため,各素性ごとにスケーリングとバイアスの2つの項だけを持つような
行列とすることで空間オーダーを下げている.また,パーソナライズのデータ
が尐ない場合に観測できる素性が疎になってしまい,パラメータが適切に更新
できなくなる問題を,素性をグルーピングしてしまい,観測できた素性につい
ての更新を観測できなかった素性の重みにも伝搬させるという方法で対処して
いる.注目すべきはグローバルランキングモデルのパラメータとパーソナライ
ズランキングモデルの構造が同じ(両方共線形モデル)であるならば,ランキ
ングの学習アルゴリズムが異なっていても良く,グローバルモデルの再学習の
必要はない作りとなっている.
5. 6. 従来 vs 提案
リッチな情報が必要 素性のグルーピングによって
スパースネスの問題に対処
効率的なadaptation
カバー率の問題
(メモリベース,PRF)
グローバルランキングモデル
を線形変換でパーソナライズ
することで対処
7. 8. 9. 10. RankNet の目的関数を変更
として目的関数を書換える
を正則化項に追加
LambdaRank の目的関数を変更
RankNetの導関数に評価尺度のゲインを追加するのみ
RankSVM の目的関数を変更
正則化項を に変更
に変更
その他
目的関数が線形モデルであれば w を書換えるのみ
11. 12. Feature Grouping
Name
素性の名前でまとめあげるパターンを人手で用意し
てグルーピング
SVD
特異値分解で低次元に圧縮した後にk-meansでクラ
スタリング
Cross
学習データをN分割して各データごとにモデルを学
習.モデルパラメータをまとめたV×N行列を作り,
k-means クラスタリング
13. 評価
データセット
bing.com の検索ログ(2012/5/27-2012/5/31)
ユーザはランダムにサンプル
ユーザID, query, timestamp, top10 document lists, clicks
queryをtimestampでソート
document listsも検索エンジンが返した元の順番に戻している
ユーザ非依存のアノテーション済みデータ
5段階のrelevance scoreが付けられている
1,830 ranking features
BM25, LM score, PageRank 等のよく使われる素性も含む
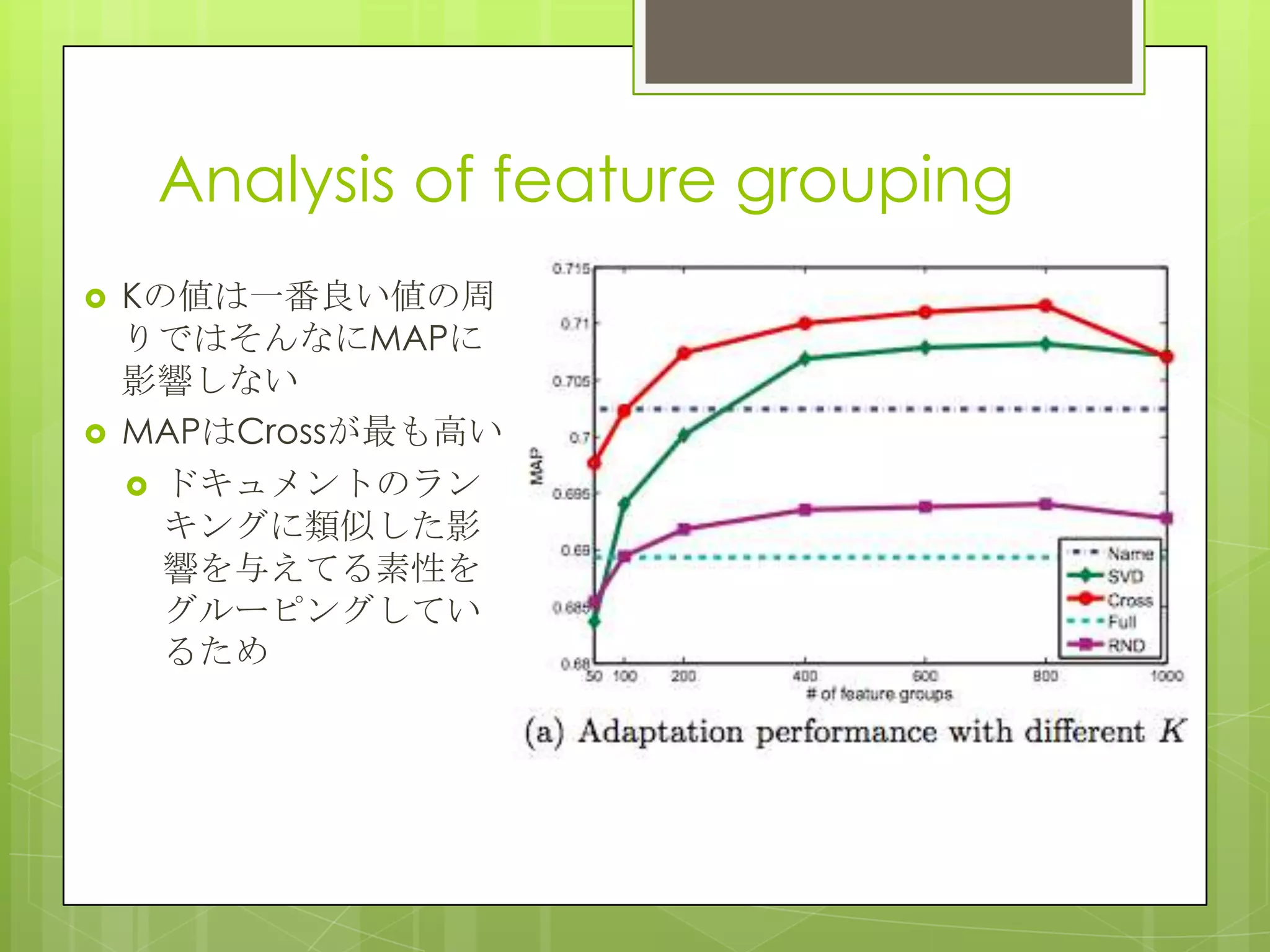
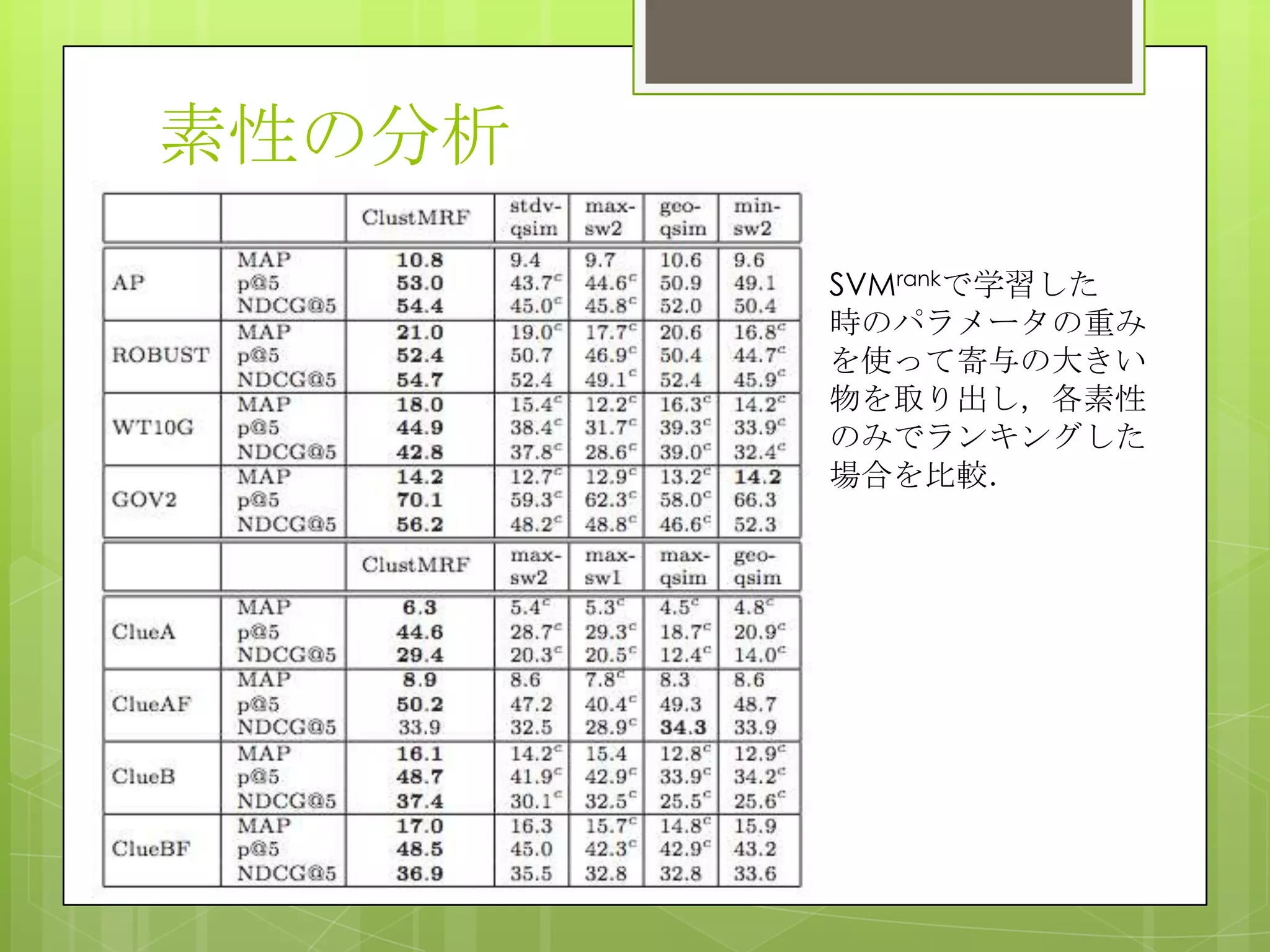
14. Analysis of feature grouping
Kの値は一番良い値の周
りではそんなにMAPに
影響しない
MAPはCrossが最も高い
ドキュメントのラン
キングに類似した影
響を与えてる素性を
グルーピングしてい
るため
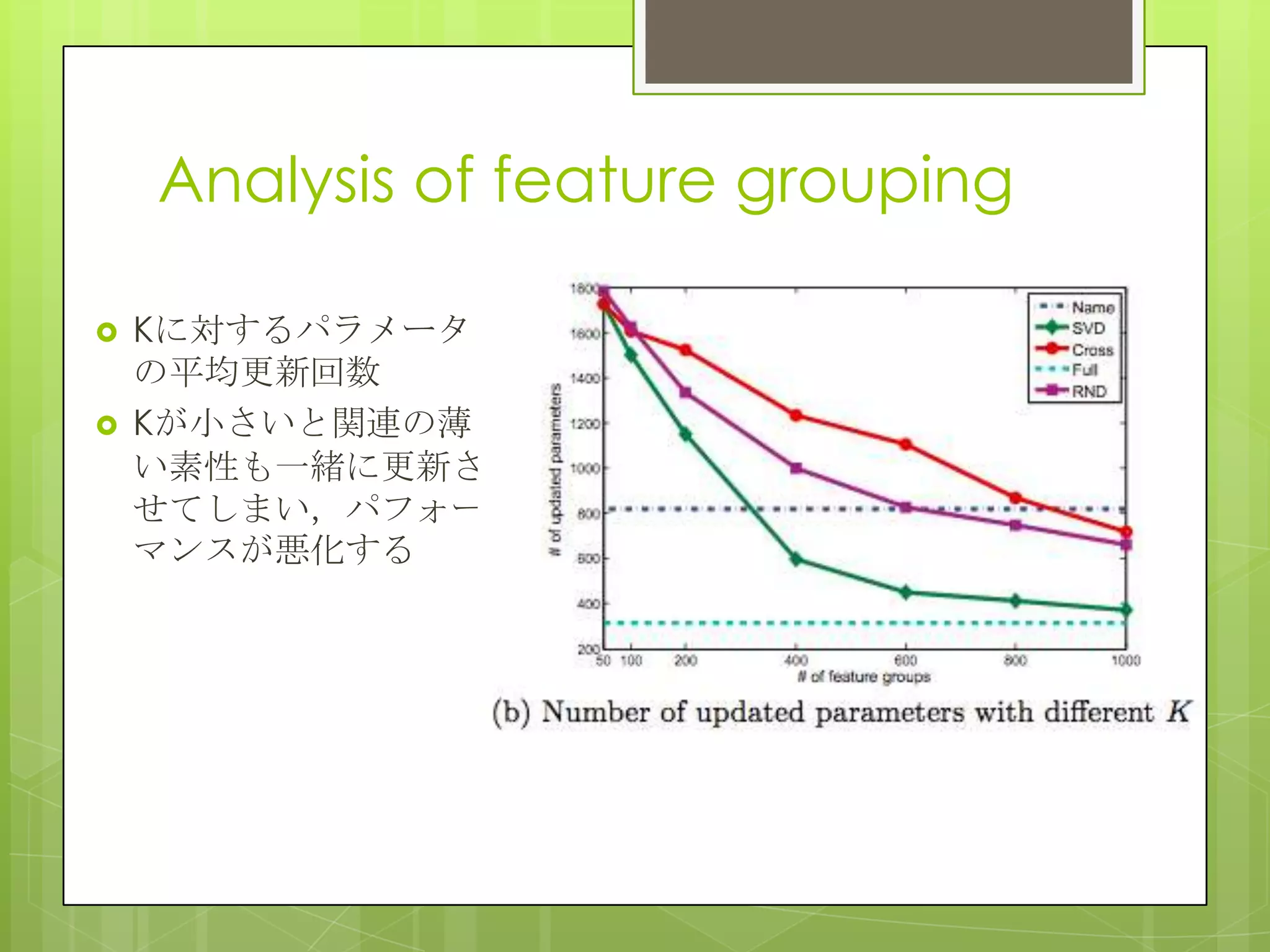
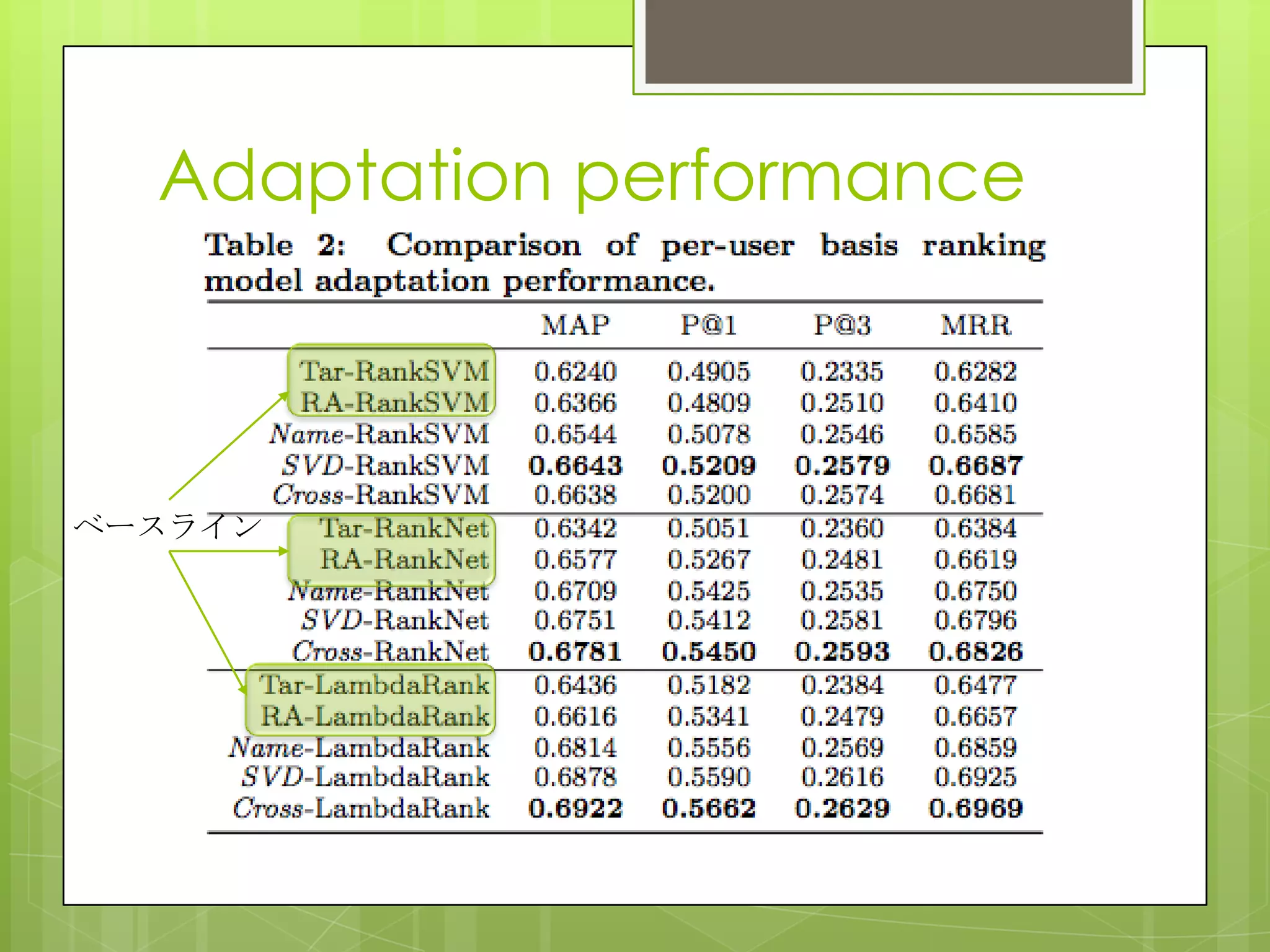
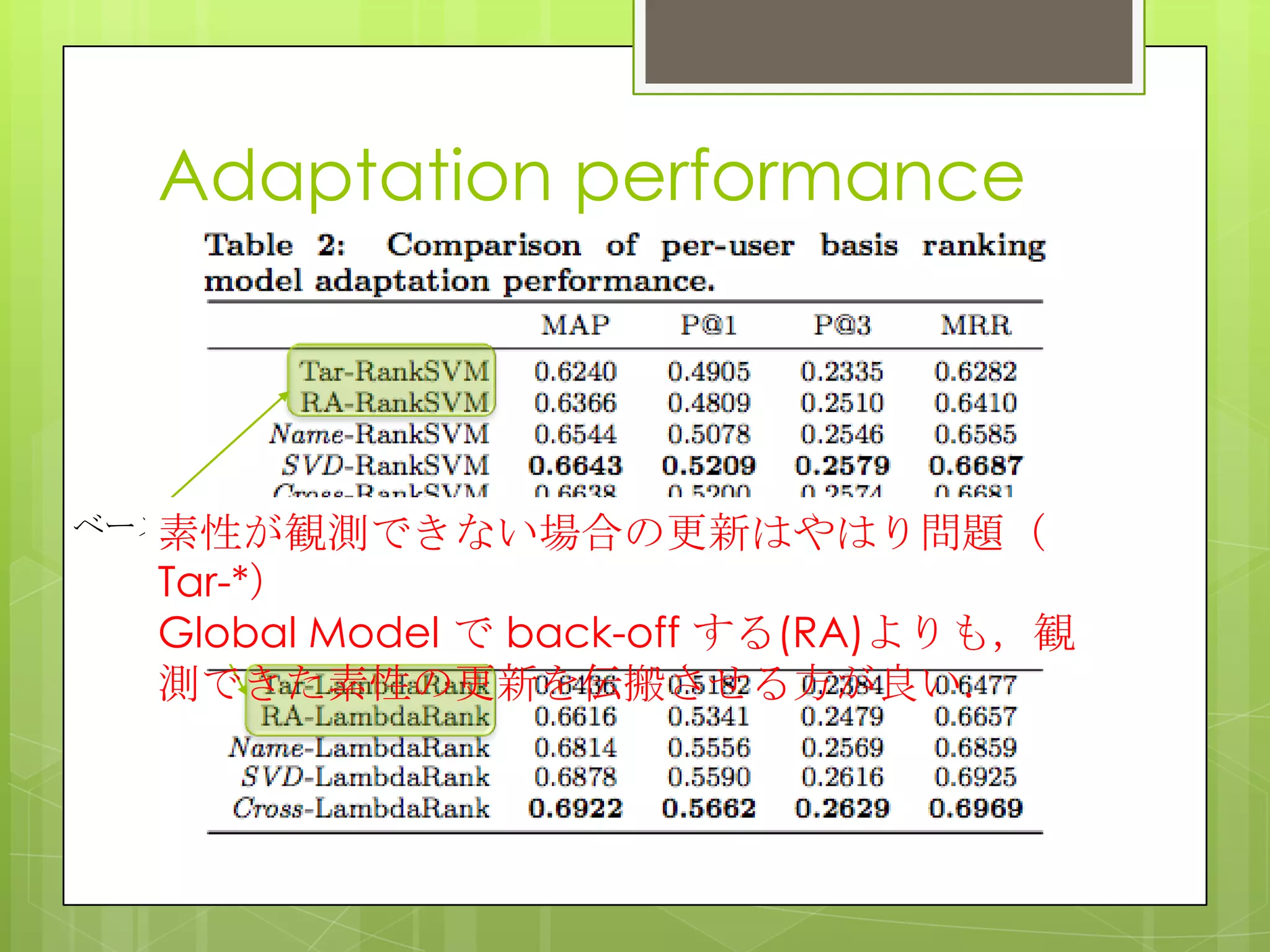
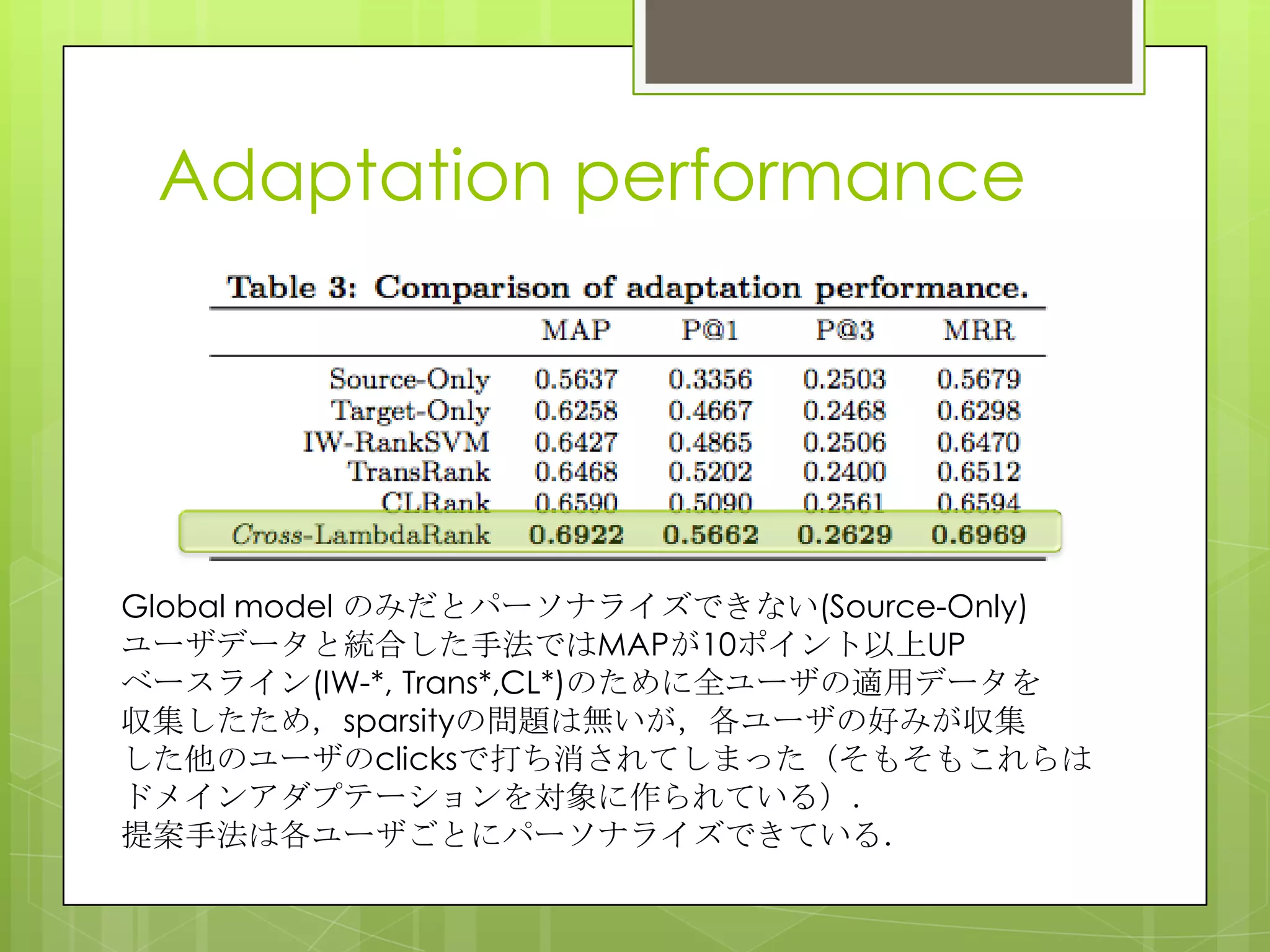
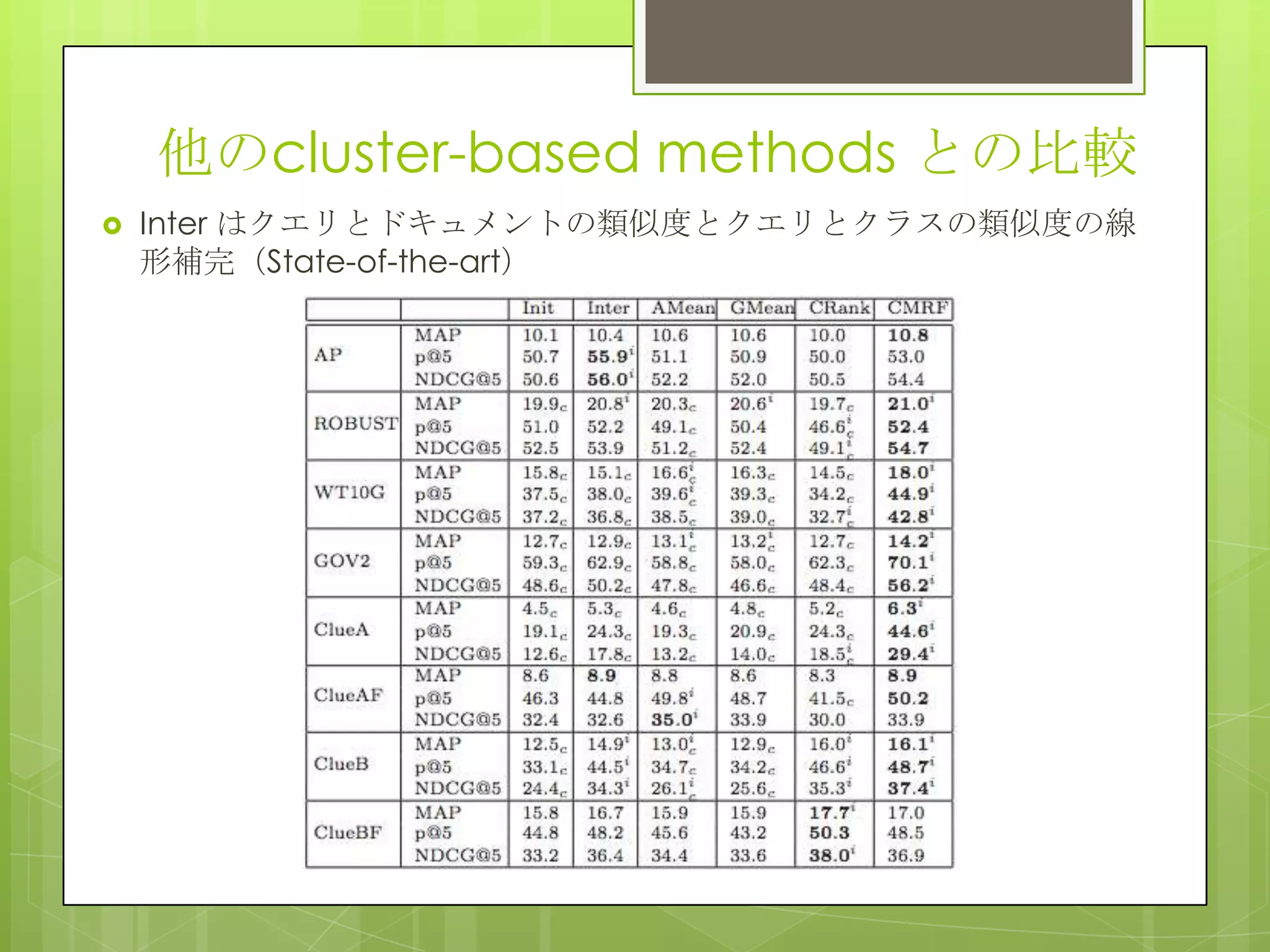
15. 16. 17. 18. Adaptation performance
Global model のみだとパーソナライズできない(Source-Only)
ユーザデータと統合した手法ではMAPが10ポイント以上UP
ベースライン(IW-*, Trans*,CL*)のために全ユーザの適用データを
収集したため,sparsityの問題は無いが,各ユーザの好みが収集
した他のユーザのclicksで打ち消されてしまった(そもそもこれらは
ドメインアダプテーションを対象に作られている).
提案手法は各ユーザごとにパーソナライズできている.
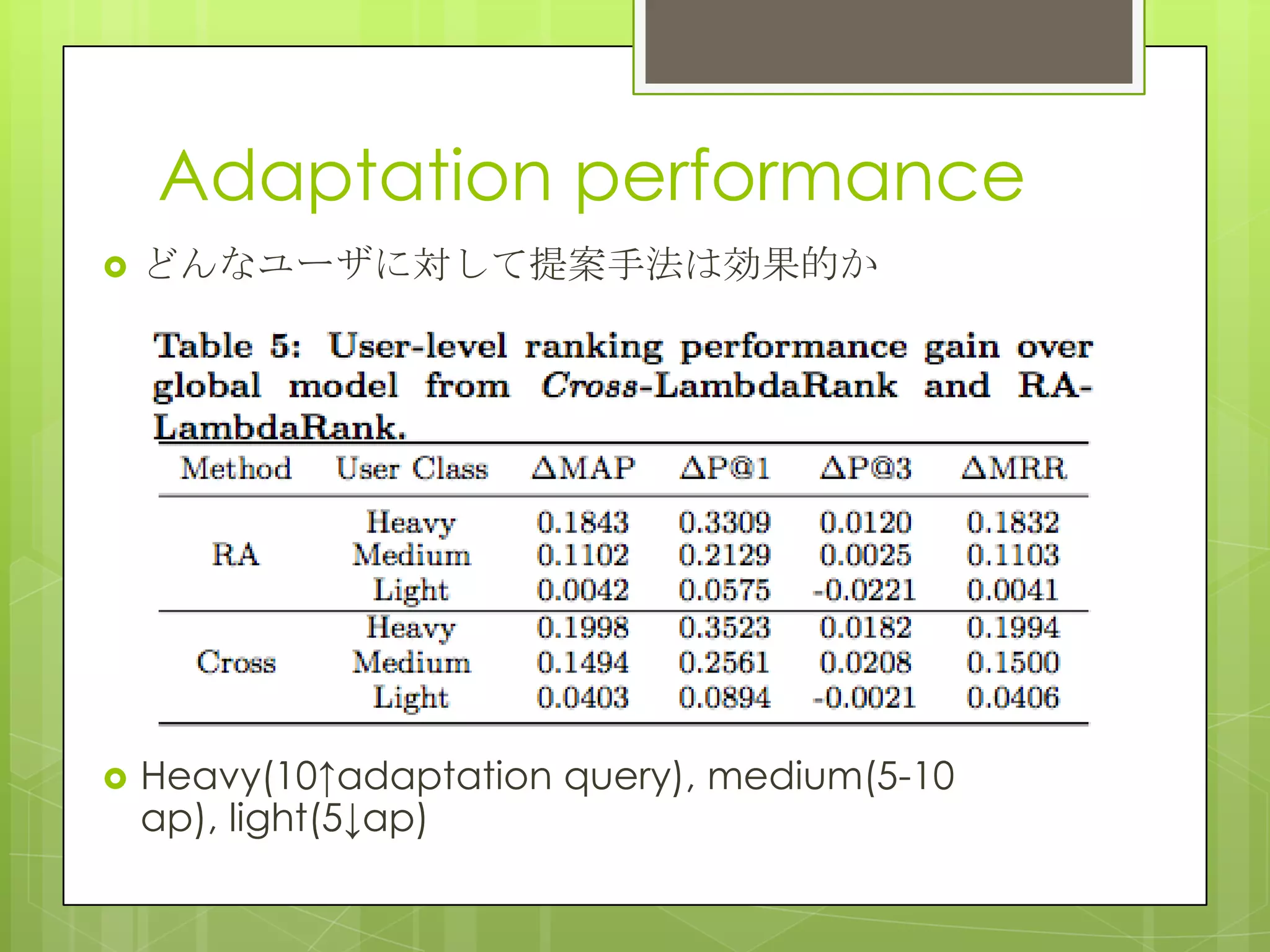
19. 20. Adaptation performance
どのタイプのクエリに効果があるのか
主にナビゲーショナルクエリに対して効果が見
られた
global model の44.9%のナビゲーショナルク
エリでMAPが向上
MAPが下がったのは10.2%のみだった
“HowTo,”, “Health”, “Q&A”はランキングが悪
化した
これらのインフォメーショナルクエリは調査目的
クリックがばらけている
ユーザが明確な答えを持っていない
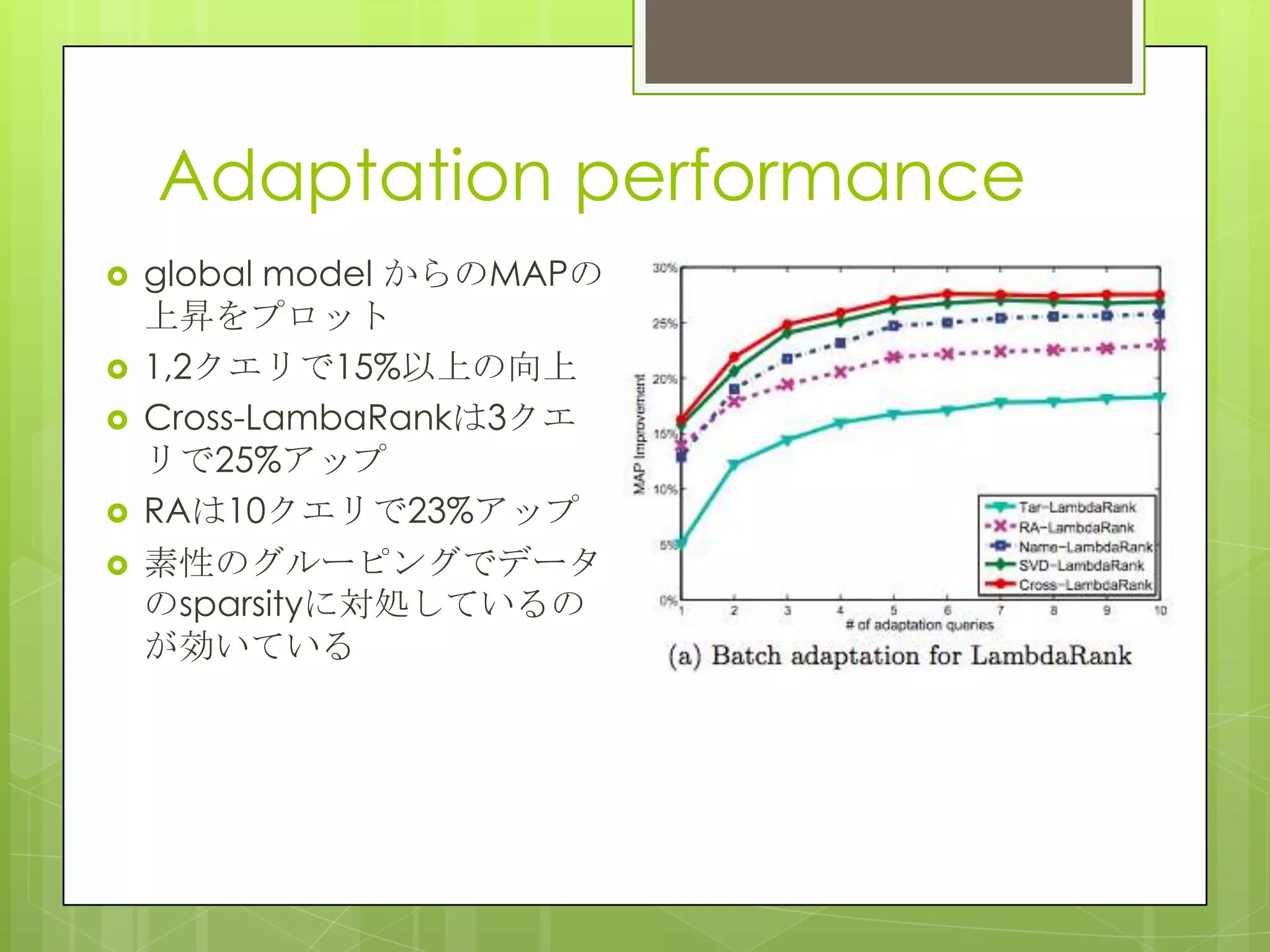
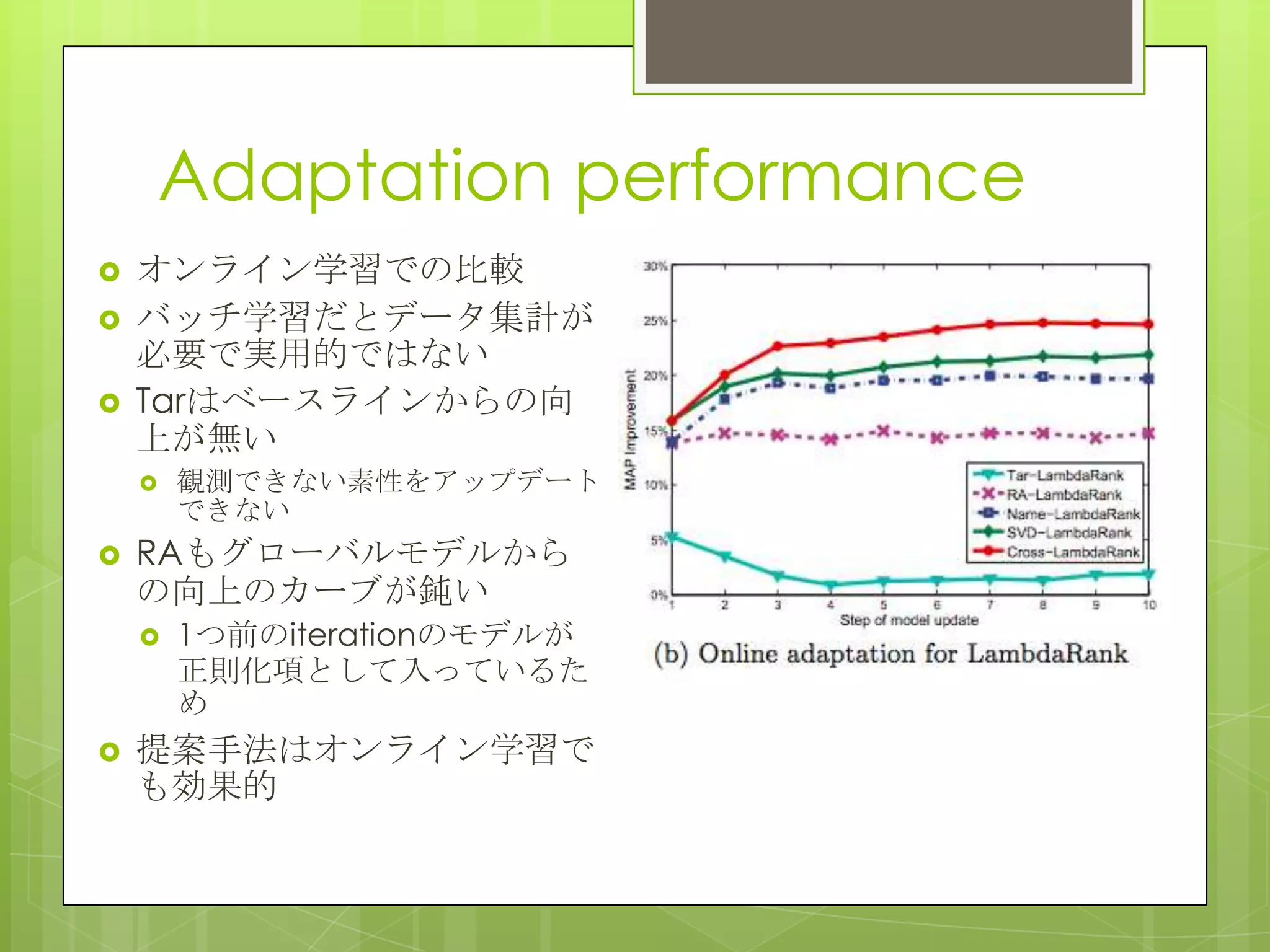
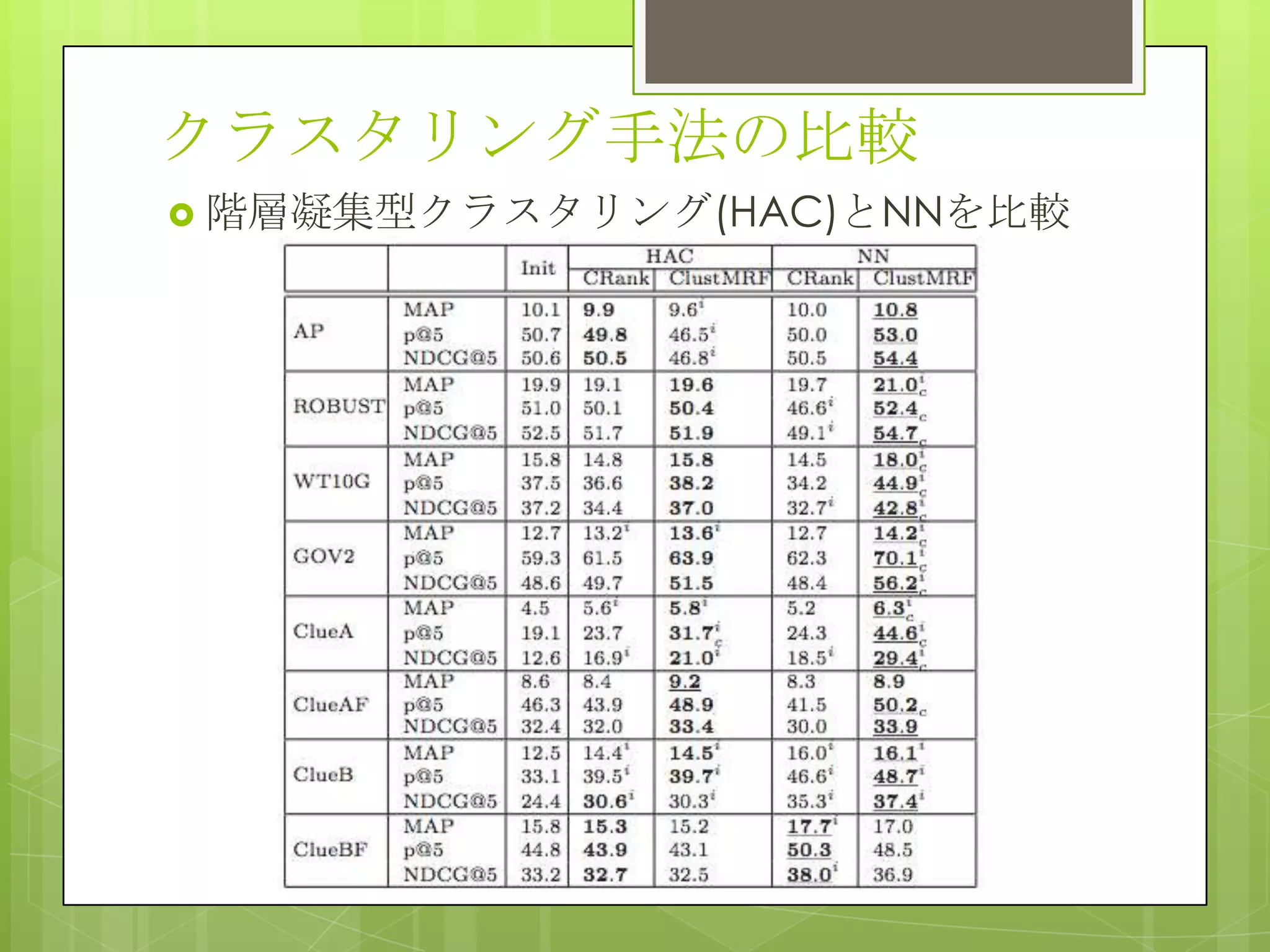
21. 22. Adaptation performance
global model からのMAPの
上昇をプロット
1,2クエリで15%以上の向上
Cross-LambaRankは3クエ
リで25%アップ
RAは10クエリで23%アップ
素性のグルーピングでデータ
のsparsityに対処しているの
が効いている
23. Adaptation performance
オンライン学習での比較
バッチ学習だとデータ集計が
必要で実用的ではない
Tarはベースラインからの向
上が無い
観測できない素性をアップデート
できない
RAもグローバルモデルから
の向上のカーブが鈍い
1つ前のiterationのモデルが
正則化項として入っているた
め
提案手法はオンライン学習で
も効果的
24. Conclusions
パーソナライズのためのgeneral ranking model
adaptation frameworkを提案
全体のランキングモデルの線形変換でパーソナライズ
モデルを作る
適応効率だけではなく,性能でも従来手法を上回った
future work
feature grouping と線形変換を同時に推定
線形変換にユーザの興味をより反映させるuser-specific
な素性を追加する
25. title list
H. Wang et al. Personalized ranking model
adaptation for web search
F. Raiber et al. Ranking document clusters
using markov random fields
J. H. Paik, A novel TF-IDF weighting
scheme for effective ranking
S. Kamali et al. Retrieving Documents with
mathematical content
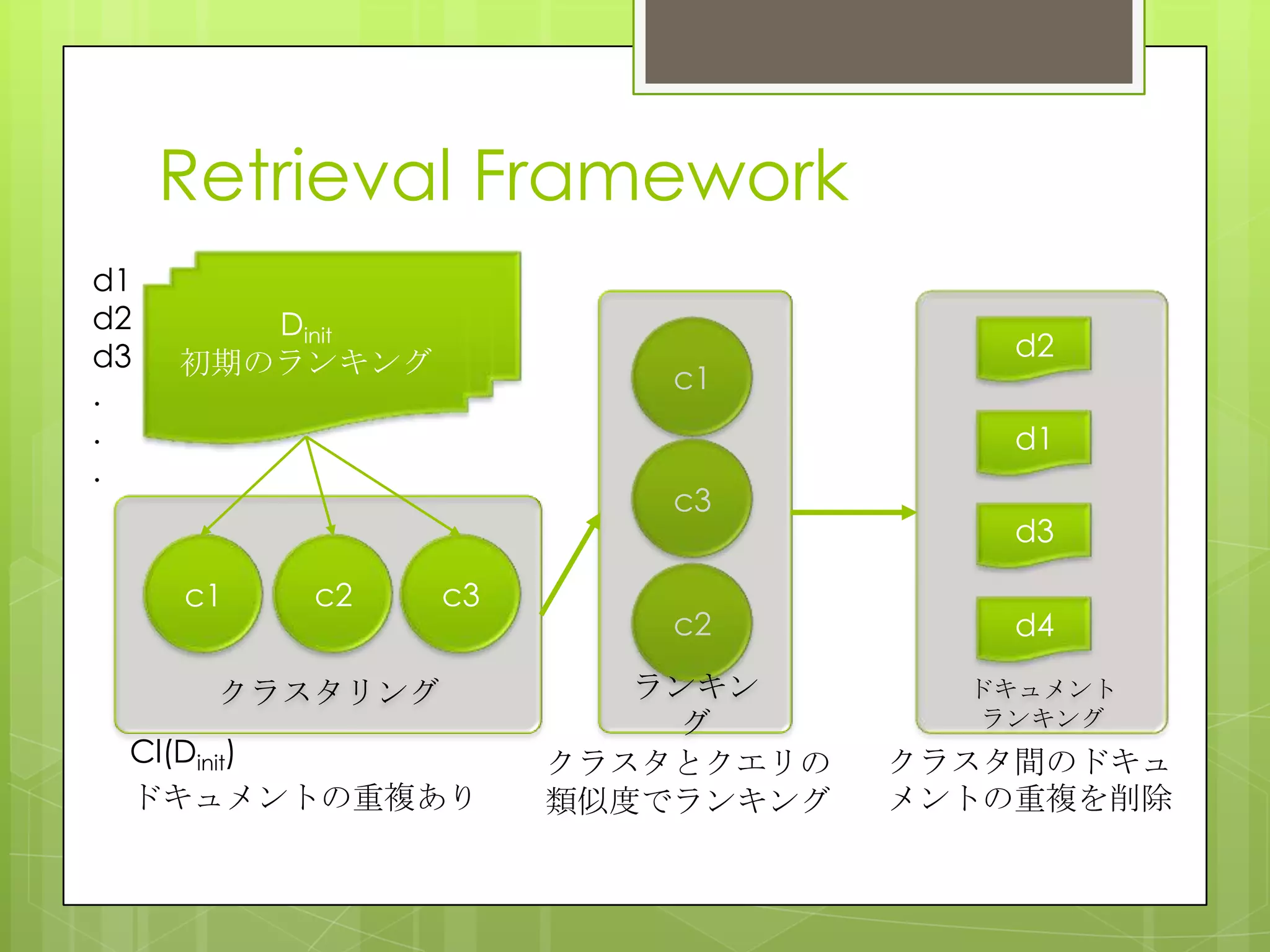
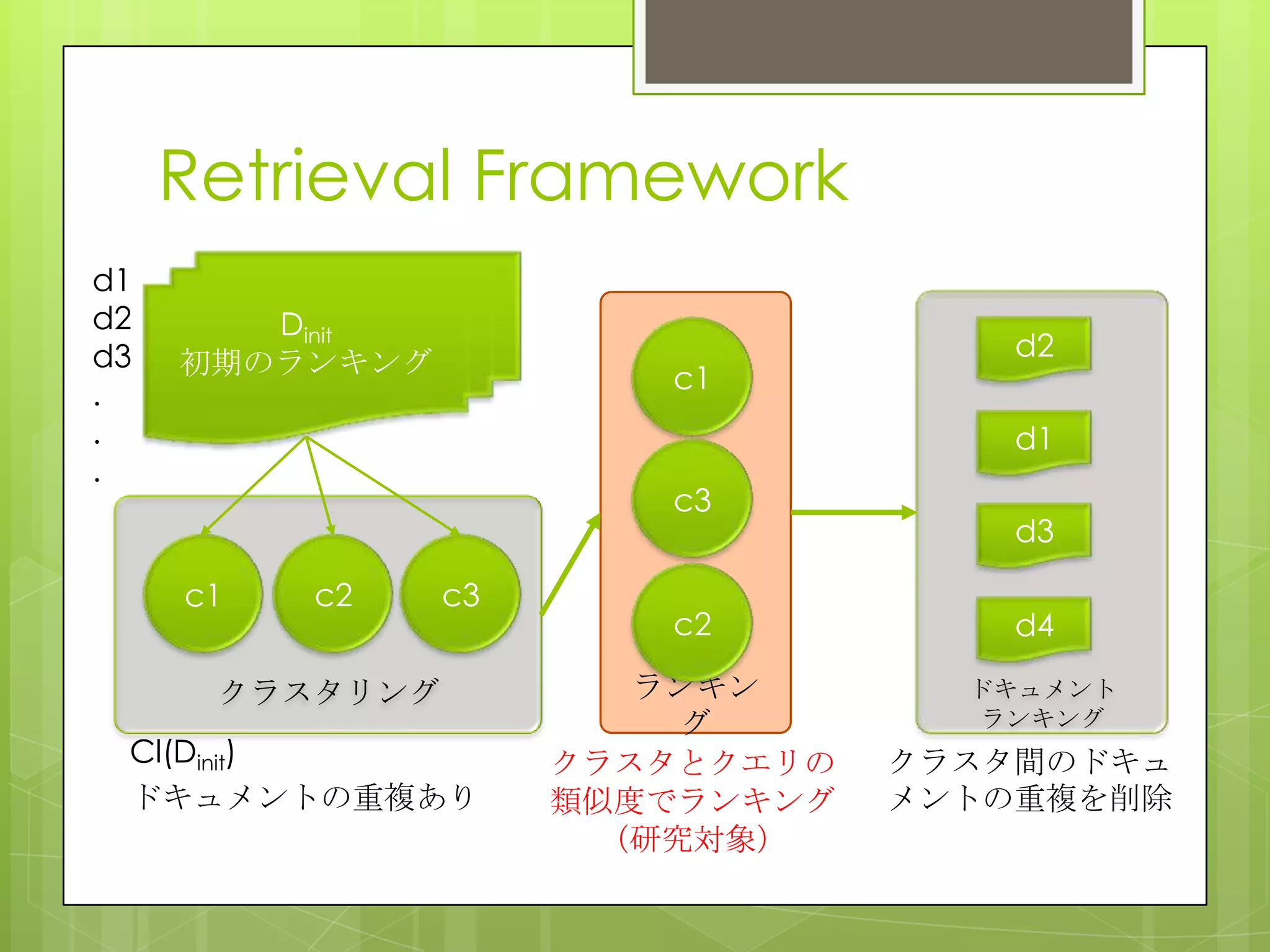
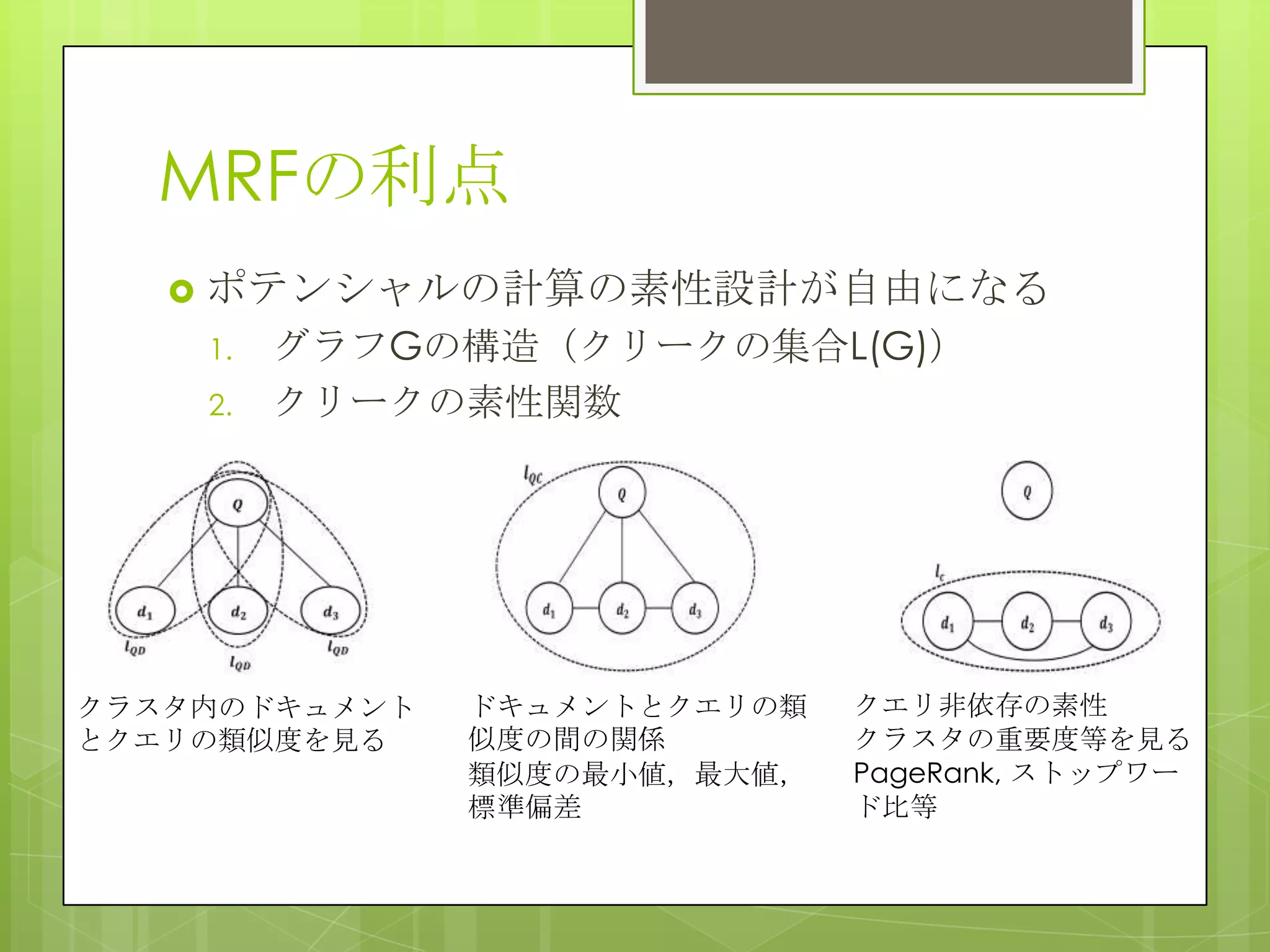
26. Ranking Document Clusters
Using Markov Random Fields
概要
クラスタランキングはクエリとクラスタを比較
する.いくつかの手法はクラスタ間やクラスタ
とドキュメントの類似度等の情報を追加してい
るが,様々なクラスタとクエリの関係を表す情
報を効率的に統合可能にする抜本的なフレーム
ワークはまだない.そこでMRFを用いて様々な
情報を取り込むことが可能なクラスタランキン
グ手法を提案している.
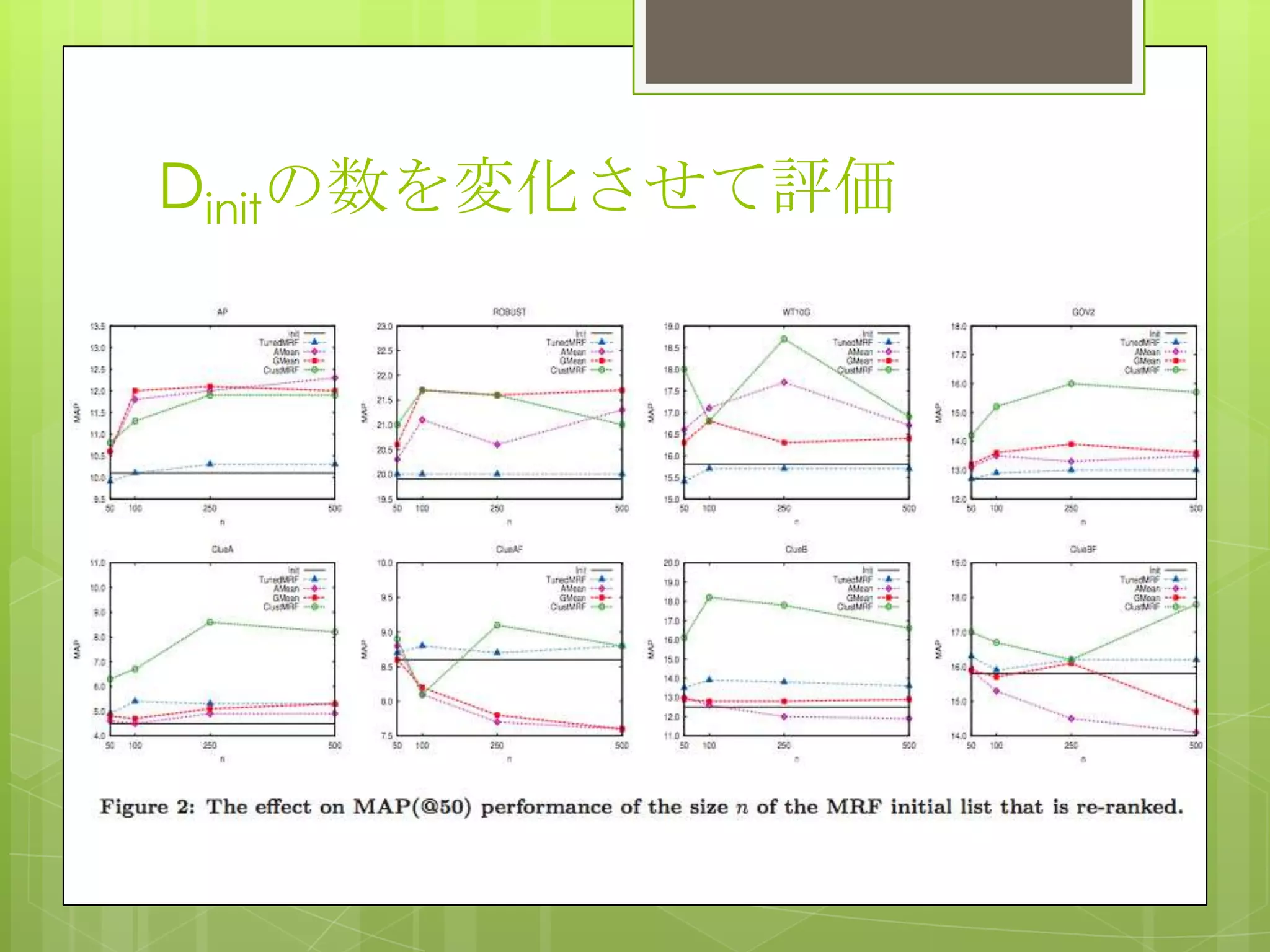
27. 28. 29. 30. 31. 評価
Dinit はMRF with SDM,DocMRF,LMの3パターンで評価
SDM の free parameter
既存研究にある値を使用
train data を使った交差検定で決定
DocMRF: クエリ比依存のドキュメント素性を加えたSDM
LM: Unigram language model
クラスタリングにはNNを使用
各クラスタはk個のドキュメントを持つ(k={5,10,20}からCVで決定)
提案手法(ClustMRF)の free parameter もCVで学習
評価データ
32. 33. 34. 35. 36. 37. 38. 39.






















































![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)














