Recommended
PDF
[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction
PPTX
PPTX
PDF
PDF
PPTX
PDF
PPTX
Nl220 Pitman-Yor Hidden Semi Markov Model
PPTX
Go-ICP: グローバル最適(Globally optimal) なICPの解説
PPTX
FLAT CAM: Replacing Lenses with Masks and Computationの解説
PPTX
PPTX
PPTX
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究
PDF
DSIRNLP06 Nested Pitman-Yor Language Model
PPTX
PDF
Swift 2 (& lldb) シンポジウム
PPTX
PPTX
テキスト前処理用Pythonモジュールneologdnの紹介
PPT
PPTX
Vanishing Component Analysisの試作(補足)
PPT
Notes on the low rank matrix approximation of kernel
PDF
On the eigenstructure of dft matrices(in japanese only)
PDF
PDF
PPTX
Vanishing Component Analysisの試作と簡単な実験
PDF
Holonomic Gradient Descent
PPTX
PDF
PPTX
More Related Content
PDF
[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction
PPTX
PPTX
PDF
PDF
PPTX
PDF
PPTX
Nl220 Pitman-Yor Hidden Semi Markov Model
Viewers also liked
PPTX
Go-ICP: グローバル最適(Globally optimal) なICPの解説
PPTX
FLAT CAM: Replacing Lenses with Masks and Computationの解説
PPTX
PPTX
PPTX
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究
PDF
DSIRNLP06 Nested Pitman-Yor Language Model
PPTX
PDF
Swift 2 (& lldb) シンポジウム
PPTX
PPTX
テキスト前処理用Pythonモジュールneologdnの紹介
PPT
PPTX
Vanishing Component Analysisの試作(補足)
PPT
Notes on the low rank matrix approximation of kernel
PDF
On the eigenstructure of dft matrices(in japanese only)
PDF
PDF
PPTX
Vanishing Component Analysisの試作と簡単な実験
PDF
Holonomic Gradient Descent
PPTX
Similar to Dsirnlp#7
PDF
PPTX
PDF
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
PPT
PPTX
dont_count_predict_in_acl2014
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
PDF
Acl yomikai, 1016, 20110903
PDF
TensorFlow math ja 05 word2vec
PPTX
Probabilistic fasttext for multi sense word embeddings
PDF
論文紹介 A Bayesian framework for word segmentation: Exploring the effects of con...
PDF
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
Recently uploaded
PDF
PMBOK 7th Edition_Project Management Context Diagram
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
PDF
PMBOK 7th Edition Project Management Process Scrum
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
Dsirnlp#7 1. 2. 3. 4. 5. 6. 確率率率の計算
2015/04/30 6
我々 名詞
と 助詞
して 動詞
は 助詞
まだ 副詞
希望 名詞
は 助詞
捨てて 動詞
い 接尾辞
ない 接尾辞
。 特殊
正解データ(⼈人⼿手)
P(名詞 | 名詞) =
名詞と名詞の連接回数
名詞の出現回数
n 遷移確率率率
n ⽣生起確率率率
P(我輩 | 名詞) =
名詞と我輩の共起回数
名詞の出現回数
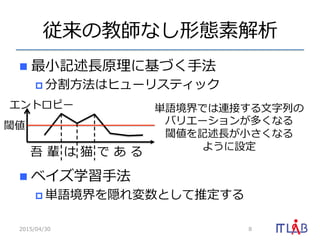
7. 8. 9. 10. 教師なし品詞推定
n 基本的に Hidden Markov Model で⾏行行う
p 事前分布や推定⽅方法がいろいろ
n 単語分割が与えられていることが前提
2015/04/30 10
x i - 1 xi xi + 1
y i - 1 yi yi+1
y: 品詞
x: 単語
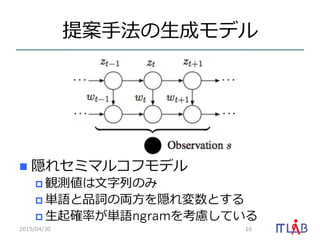
11. 12. 13. 形態素解析の定式化
n 形態素解析:
n :単語, :品詞, :⽂文字, :⽂文
n 確率率率 を最⼤大化するような w を推
定する問題
ˆw = argmax
w
p(w|s)
s : c1, c2, . . . , cN
p(w|s)
wn cn szn
13
w = {w1, w2, . . . , wM , z1, z2, . . . , zM }
14. 部分問題に分割
n 形態素解析 w の確率率率を以下とおく
n 以下のように変形
2015/04/30 14
P(w|s) =
M
i=1
P(wi, zi|hi 1)
hi = {w1, w2, . . . , wi, z1, z2, . . . , zi}
P(wi, zi|hi 1) = P(wi|zi, hi 1)P(zi|hi 1)
P(wi|zi, hi 1) = P(wi|wi 1
i N+1, zi)
P(zi|hi 1) = P(zi|zi 1
i N+1)
品詞毎の
単語ngram
品詞ngram
15. 16. 17. 18. 19. Nested Pitman-Yor Language Model
[Mochihashi, 2009]
n 提案⼿手法の品詞数を1にした物がNPYLMと
⼀一致する
n つまり提案法はNPYLMの拡張になっている
n 単語 unigram のスムージングには⽂文字
ngramを⽤用いている
2015/04/30 19
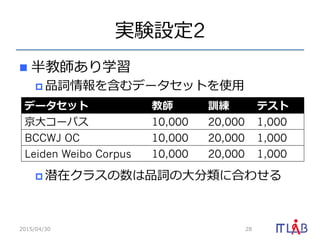
20. 21. 学習アルゴリズム
1. 各⽂文にランダムに品詞を割当てる
2. ⽂文を単語と⾒見見なし,単語/品詞HPYLMを更更新
3. 収束するまで以下を繰り返す
1. ランダムに⽂文sを選択し,sの形態素解析結果w(s)を
パラメータから除去
2. 除去後のパラメータを⽤用いて形態素解析結果をサン
プリング
3. w’(s)を⽤用いてパラメータを更更新
2015/04/30 21
w (s) P(w|s; z, )
※⾔言語モデルの更更新は以下を参照
Y. W. Teh. A Bayesian Interpretation of In- terpolated Kneser-Ney.
Technical Report TRA2/06, School of Computing, NUS.
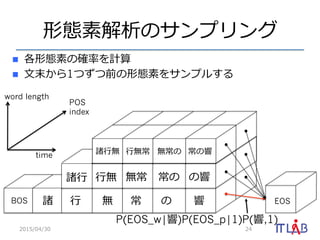
22. 形態素解析のサンプリング
n ⼊入⼒力力:「諸⾏行行無常の響」
n 形態素解析の確率率率に従って1つサンプルす
る
2015/04/30 22
P(諸行, 無常, の, 響, 1, 1, 2, 1) = 0.1
P(諸, 行, 無常, の響, 1, 1, 1, 2) = 0.01
・
・
・
組合せが膨⼤大なので効率率率が悪い
動的計画法で効率率率的に解く
23. 形態素解析のサンプリング
n 各単語候補と品詞の同時確率率率を計算
2015/04/30 23
周辺化
P(諸, 行, 無, 常, の,響, 1, 1, 1, 1, 2, 1)
+P(諸行, 無常, の,響, 1, 1, 2, 1)
+P(諸行無常, の,響, 1, 2, 1)
+ · · ·
= P(響, 1)
24. 25. 前向き確率率率の計算
2015/04/30 25
[t][k][z] =
t k
j=1
Z
r=0
P(ct
t k|ct k
t k j+1, z)P(z|r) [t k][j][r]
EOSBOS 諸 ⾏行行 無 常 の 響
諸⾏行行 ⾏行行無 無常 常の の響
word length
POS
index
time 諸⾏行行無 ⾏行行無常 無常の 常の響
α[6][1][1] →(α[響][1])
つまり周辺化して を求めている P(響, 1)
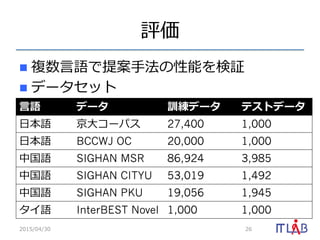
26. 評価
n 複数⾔言語で提案⼿手法の性能を検証
n データセット
2015/04/30 26
⾔言語 データ 訓練データ テストデータ
⽇日本語 京⼤大コーパス 27,400 1,000
⽇日本語 BCCWJ OC 20,000 1,000
中国語 SIGHAN MSR 86,924 3,985
中国語 SIGHAN CITYU 53,019 1,492
中国語 SIGHAN PKU 19,056 1,945
タイ語 InterBEST Novel 1,000 1,000
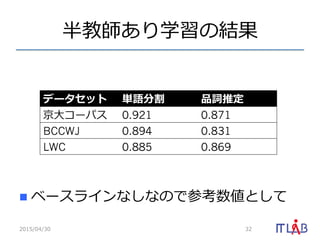
27. 28. 29. 30. 教師なし単語分割の評価
2015/04/30 30
データ PYHSMM NPYLM BE+MDL HDP+HMM
京⼤大コーパス 0.715 0.621 0.713 -
BCCWJ 0.705 - - -
MSR 0.829 0.802 0.782 0.817
CITYU 0.817 0.824 0.787 -
PKU 0.816 - 0.808 0.811
BEST 0.821 - 0.821 -
31. 32. 33. 解析結果の例例
n 三河弁の例例(K=50)
ウェーブスタジアム/34 刈⾕谷/28 に/2 FC/1 刈⾕谷/28 の/2 試 合/
31 を/2 観/35 に/2 ⾏行行/27 って/40 み/35 りん/3 フォロバ/17
ありがと/19 ございます/19 ! /2 よろしく/19 頼 む/35 のん/
3 。/10
これ/20 ぎし/37 しか/37 ない/12 だ/12 かん/3 ? /10 あけお
め/19 だ/12 ぞん/3 !! /10 今年年/18 も/2 よろしく /19 頼む/35
ぞん/3 !! /10
おま/13 ー/5 の/2 頭/25 、/2 ちんじゅう/35 だのん/3 !! /8 w/
8
ぐろ/36 と/24 も/2 ⾔言/15 う/12 のん/3 !! /8 とちんこで/35 結
んで/19 まったもん/12 で/12 、/2 と/37 れ /12 や/45 せん/
13 に/13 ー/5 (^_^;)/10
のんほい/12 は/2 若若い/24 ⼈人/20 は/2 あんまし/30 使/15 わ
ん/12 ぞん/3 !/10 じいさん/24 、/2 ばあさん/37 世代/25 の /
2 ⾔言葉葉/27 だ/12 のん/3 ! /8 /6
2015/04/30 33
34. 35. 36. 37. 参考⽂文献
n Miaohong Chen, et al. 2014. A Joint Model for Unsupervised Chinese Word
Segmentation. In EMNLP 2014, pages 854–1 863.
n Sharon Goldwater, et al. A Fully Bayesian Approach to Unsupervised Part-of-Speech
Tagging. In Proceedings of ACL 2007, pages 744– 751.
n Sharon Goldwater, et al. Contextual Dependencies in Un- supervised Word
Segmentation. In Proceedings of ACL/COLING 2006, pages 673–680.
n Matthew J. Johnson et al. Bayesian Nonparametric Hidden Semi-Markov Models.
Journal of Machine Learning Research, 14:673–701.
n Pierre Magistry et al. Can MDL Improve Unsupervised Chinese Word Segmenta- tion?
In Proceedings of the Seventh SIGHAN Work- shop on Chinese Language Processing,
pages 2–10.
n Daichi Mochihashi, et al. Bayesian Unsupervised Word Seg- mentation with Nested
Pitman-Yor Language Mod- eling. In Proceedings of ACL-IJCNLP 2009, pages 100–108.
n Yee Whye Teh. A Bayesian Interpretation of In- terpolated Kneser-Ney. Technical
Report TRA2/06, School of Computing, NUS.
n Valentin Zhikov, et al. An Efficient Algorithm for Unsuper- vised Word Segmentation
with Branching Entropy and MDL. In EMNLP 2010, pages 832–842.
2015/04/30 37
















![Nested Pitman-Yor Language Model
[Mochihashi, 2009]
n 提案⼿手法の品詞数を1にした物がNPYLMと
⼀一致する
n つまり提案法はNPYLMの拡張になっている
n 単語 unigram のスムージングには⽂文字
ngramを⽤用いている
2015/04/30 19](https://image.slidesharecdn.com/dsirnlp7-150430055828-conversion-gate01/85/Dsirnlp-7-19-320.jpg)




![前向き確率率率の計算
2015/04/30 25
[t][k][z] =
t k
j=1
Z
r=0
P(ct
t k|ct k
t k j+1, z)P(z|r) [t k][j][r]
EOSBOS 諸 ⾏行行 無 常 の 響
諸⾏行行 ⾏行行無 無常 常の の響
word length
POS
index
time 諸⾏行行無 ⾏行行無常 無常の 常の響
α[6][1][1] →(α[響][1])
つまり周辺化して を求めている P(響, 1)](https://image.slidesharecdn.com/dsirnlp7-150430055828-conversion-gate01/85/Dsirnlp-7-25-320.jpg)









![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)



























































