Downloaded 10 times
![White paper on Machine
Learning
(Speech to Text Conversion using Android Platform)
Group 10
[Type the companyname]
Apurva Mittal (20141009)
Ketan Gyanchandani (20141028)
Riya Giri (20141058)
Sanjeev Kumar (20141063)
Saurabh Ojha (20141064)
Vikash Kumar (20141072)](https://image.slidesharecdn.com/finalone-160228200628/85/Machine-Learning-1-320.jpg)
![White paper on Machine
Learning
(Speech to Text Conversion using Android Platform)
Group 10
[Type the companyname]
Apurva Mittal (20141009)
Ketan Gyanchandani (20141028)
Riya Giri (20141058)
Sanjeev Kumar (20141063)
Saurabh Ojha (20141064)
Vikash Kumar (20141072)](https://image.slidesharecdn.com/finalone-160228200628/75/Machine-Learning-1-2048.jpg)







![service is a component that runs in the background to perform long running operations or to
perform work for remote processes. One service can link multiple applications and service is
executed until a connection with all applications is done. A content provider manages a
shared set of application data. Data can be stored in the file system, a SQLite database, on the
web, or any other persistent storage location which application can access [1]. Through the
content provider, other applications can query or even modify the data (if the content
provider allows it).
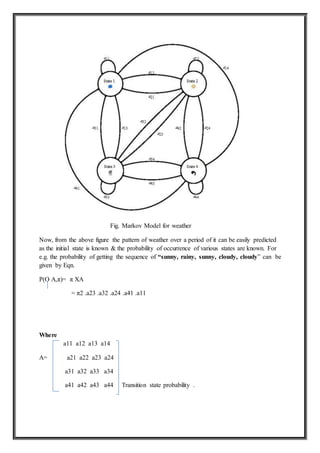
Speech Recognition:
Speech recognition for this application is done on Google server, using the HMM and n-gram
algorithm. The system can be divided into several blocks: feature extraction, acoustic models
database which is built based on the training data, dictionary, language model and the speech
recognition algorithm.
The input audio waveform from a microphone is converted into a sequence of fixed size
acoustic vectors Y 1:T = y1,...,yT in a process called feature extraction. The decoder then
attempts to find the sequence of words w1:L = w1,...,wL which is most likely to have
generated Y , i.e. the decoder tries to find wˆ = arg max w{P(w|Y )}.However, since P(w|Y )
is difficult to model directly,1 Bayes’ Rule is used to transform it into the equivalent problem
of finding:
wˆ = arg max w{p(Y |w)P(w)}
The likelihood p(Y |w) is determined by an acoustic model and the prior P(w) is determined
by a language model.
The basic unit of sound represented by the acoustic model is the phone. For example, the
word “bat” is composed of three phones /b/ /ae/ /t/. About 40 such phones are required for
English.
For any given w, the corresponding acoustic model is synthesized by concatenating phone
models to make words as defined by a pronunciation dictionary. The parameters of these
phone models are estimated from training data consisting of speech waveforms and their
orthographic transcriptions. The language model is typically an N-gram model in which the
probability of each word is conditioned only on its N-1 predecessors. The N-gram parameters
are estimated by counting N-tuples in appropriate text corpora (set of words). The decoder
operates by searching through all possible word sequences using pruning to remove unlikely
hypotheses thereby keeping the search tractable. When the end of the utterance is reached, the](https://image.slidesharecdn.com/finalone-160228200628/85/Machine-Learning-10-320.jpg)





The document provides information on machine learning and speech recognition using the Android platform. It discusses how machine learning allows computers to learn without being explicitly programmed by detecting patterns in data. It then explains how speech recognition works by translating spoken words to text, using algorithms like hidden Markov models and n-gram language models. Finally, it discusses how the Android operating system and its architecture can be used to create a speech to text application to address problems like hands-free computing and assisting the blind.





![NLP Asignment Final Presentation [IIT-Bombay]](https://cdn.slidesharecdn.com/ss_thumbnails/final-presentation-131213084802-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































