
Downloaded 11 times







![Regular expressions Some more Natural Language Processing Take-home message & next steps
What is a regexp?
An example
From last week’s task
• We wanted to remove everything but words from a tweet
• We did so by calling the .replace() method
• We could do this with a regular expression as well:
[ˆa-zA-Z] would match anything that is not a letter
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-9-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
What is a regexp?
Basic regexp elements
Alternatives
[TtFf] matches either T or t or F or f
Twitter|Facebook matches either Twitter or Facebook
. matches any character
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-10-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
What is a regexp?
Basic regexp elements
Alternatives
[TtFf] matches either T or t or F or f
Twitter|Facebook matches either Twitter or Facebook
. matches any character
Repetition
* the expression before occurs 0 or more times
+ the expression before occurs 1 or more times
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-11-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
What is a regexp?
regexp quizz
Which words would be matched?
1 [Pp]ython
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-12-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
What is a regexp?
regexp quizz
Which words would be matched?
1 [Pp]ython
2 [A-Z]+
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-13-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
What is a regexp?
regexp quizz
Which words would be matched?
1 [Pp]ython
2 [A-Z]+
3 RT ?:? @[a-zA-Z0-9]*
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-14-320.jpg)

![Regular expressions Some more Natural Language Processing Take-home message & next steps
Using a regexp in Python
How to use regular expressions in Python
The module re
re.findall("[Tt]witter|[Ff]acebook",testo) returns a list
with all occurances of Twitter or Facebook in the
string called testo
re.findall("[0-9]+[a-zA-Z]+",testo) returns a list with all
words that start with one or more numbers followed
by one or more letters in the string called testo
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-16-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
Using a regexp in Python
How to use regular expressions in Python
The module re
re.findall("[Tt]witter|[Ff]acebook",testo) returns a list
with all occurances of Twitter or Facebook in the
string called testo
re.findall("[0-9]+[a-zA-Z]+",testo) returns a list with all
words that start with one or more numbers followed
by one or more letters in the string called testo
re.sub("[Tt]witter|[Ff]acebook","a social medium",testo)
returns a string in which all all occurances of Twitter
or Facebook are replaced by "a social medium"
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-17-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
Using a regexp in Python
How to use regular expressions in Python
The module re
re.match(" +([0-9]+) of ([0-9]+) points",line) returns
None unless it exactly matches the string line. If it
does, you can access the part between () with the
.group() method.
Example:
1 line=" 2 of 25 points"
2 result=re.match(" +([0-9]+) of ([0-9]+) points",line)
3 if result:
4 print ("Your points:",result.group(1))
5 print ("Maximum points:",result.group(2))
Your points: 2
Maximum points: 25
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-18-320.jpg)


![Example 1: Counting actors
1 import re, csv
2 from os import listdir, path
3 mypath ="/home/damian/artikelen"
4 matchcount54_list=[]
5 matchcount10_list=[]
6 filename_list = [f for f in listdir(mypath) if path.isfile(path.join(
mypath,f))]
7 for f in filename_list:
8 matchcount54=0
9 matchcount10=0
10 with open(path.join(mypath,f),mode="r",encoding="utf-8") as fi:
11 artikel=fi.readlines()
12 for line in artikel:
13 matches54 = re.findall(’Israel.*(minister|politician.*|[Aa]
uthorit)’,line)
14 matches10 = re.findall(’[Pp]alest’,line)
15 matchcount54+=len(matches54)
16 matchcount10+=len(matches10)
17 matchcount54_list.append(matchcount54)
18 matchcount10_list.append(matchcount10)
19 output=zip(filename_list,matchcount10_list,matchcount54_list)
20 with open("overzichtstabel.csv", mode=’w’,encoding="utf-8") as fo:
21 writer = csv.writer(fo)
22 writer.writerows(output)](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-21-320.jpg)

![Regular expressions Some more Natural Language Processing Take-home message & next steps
Using a regexp in Python
Example 2: Check the number of a lexis nexis article
1 All Rights Reserved
2
3 2 of 200 DOCUMENTS
4
5 De Telegraaf
6
7 21 maart 2014 vrijdag
8
9 Brussel bereikt akkoord aanpak probleembanken;
10 ECB krijgt meer in melk te brokkelen
11
12 SECTION: Finance; Blz. 24
13 LENGTH: 660 woorden
14
15 BRUSSEL Europa heeft gisteren op de valreep een akkoord bereikt
16 over een saneringsfonds voor banken. Daarmee staat de laatste
1 for line in tekst:
2 matchObj=re.match(r" +([0-9]+) of ([0-9]+) DOCUMENTS",line)
3 if matchObj:
4 numberofarticle= int(matchObj.group(1))
5 totalnumberofarticles= int(matchObj.group(2))
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-23-320.jpg)








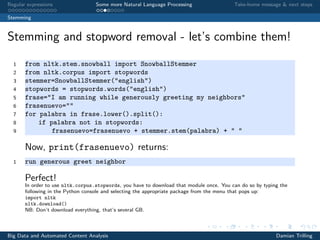
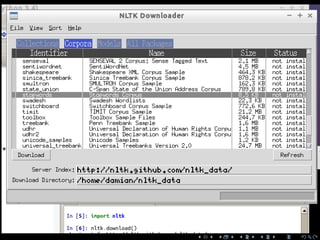

![Regular expressions Some more Natural Language Processing Take-home message & next steps
Parsing sentences
Parsing a sentence
1 import nltk
2 sentence = "At eight o’clock on Thursday morning, Arthur didn’t feel
very good."
3 tokens = nltk.word_tokenize(sentence)
4 print (tokens)
nltk.word_tokenize(sentence) is similar to sentence.split(),
but compare handling of punctuation and the didn’t in the
output:
1 [’At’, ’eight’, "o’clock", ’on’, ’Thursday’, ’morning’,’Arthur’, ’did’,
"n’t", ’feel’, ’very’, ’good’, ’.’]
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-35-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
Parsing sentences
Parsing a sentence
Now, as the next step, you can “tag” the tokenized sentence:
1 tagged = nltk.pos_tag(tokens)
2 print (tagged[0:6])
gives you the following:
1 [(’At’, ’IN’), (’eight’, ’CD’), ("o’clock", ’JJ’), (’on’, ’IN’),
2 (’Thursday’, ’NNP’), (’morning’, ’NN’)]
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-36-320.jpg)
![Regular expressions Some more Natural Language Processing Take-home message & next steps
Parsing sentences
Parsing a sentence
Now, as the next step, you can “tag” the tokenized sentence:
1 tagged = nltk.pos_tag(tokens)
2 print (tagged[0:6])
gives you the following:
1 [(’At’, ’IN’), (’eight’, ’CD’), ("o’clock", ’JJ’), (’on’, ’IN’),
2 (’Thursday’, ’NNP’), (’morning’, ’NN’)]
And you could get the word type of "morning" with
tagged[5][1]!
Big Data and Automated Content Analysis Damian Trilling](https://image.slidesharecdn.com/lecture5-170304115101/85/BDACA1617s2-Lecture5-37-320.jpg)



This document provides an overview of a presentation on automated content analysis using regular expressions and natural language processing. The presentation covers topics like bottom-up vs top-down analysis, what regular expressions are and how they can be used in Python, stemming, parsing sentences, and combining techniques like stemming and stopword removal. Examples are given on using regular expressions to count actors in articles and check the number of a document from LexisNexis. The takeaway message is about an upcoming take-home exam and future meetings.


























































































