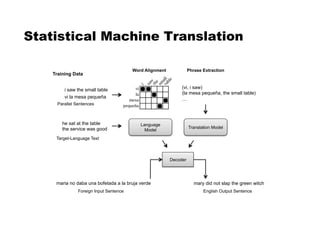
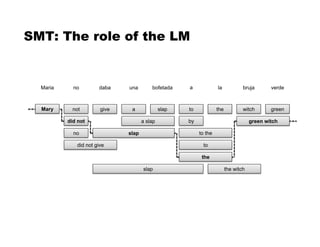
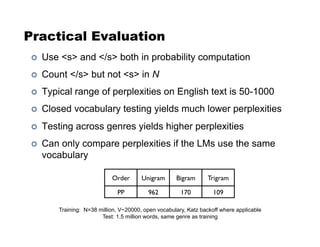
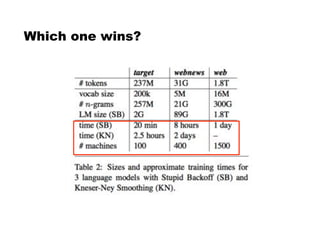
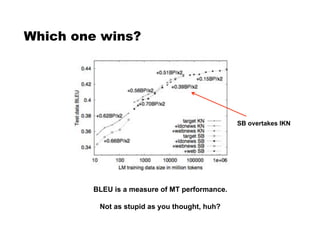
This document discusses language models and their evaluation. It begins with an overview of n-gram language models, which assign probabilities to sequences of tokens based on previous word histories. It then discusses techniques for dealing with data sparsity in language models, such as smoothing methods like Laplace smoothing and Good-Turing estimation. Finally, it covers evaluating language models using perplexity, which measures how surprised a language model is by the next words in a test set. Lower perplexity indicates a better language model.










![Computing Probabilities
Is this practical?
No! Can’t keep track of all possible histories of all words!
[chain rule]](https://image.slidesharecdn.com/lecture6-151215112251/85/Lecture-6-13-320.jpg)







































![Using MapReduce to Train IKN
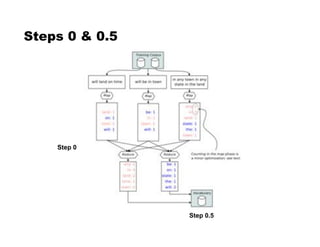
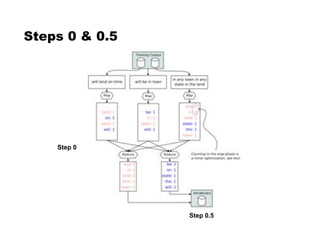
! Step 0: Count words [MR]
! Step 0.5: Assign IDs to words [vocabulary generation]
(more frequent $ smaller IDs)
! Step 1: Compute n-gram counts [MR]
! Step 2: Compute lower order context counts [MR]
! Step 3: Compute unsmoothed probabilities and
interpolation weights [MR]
! Step 4: Compute interpolated probabilities [MR]
[MR] = MapReduce job](https://image.slidesharecdn.com/lecture6-151215112251/85/Lecture-6-54-320.jpg)


![Let’s try something stupid!
! Simplify backoff as much as possible!
! Forget about trying to make the LM be a true probability
distribution!
! Don’t do any discounting of higher order models!
! Have a single backoff weight independent of context!
[(•) = ]
“Stupid Backoff (SB)”](https://image.slidesharecdn.com/lecture6-151215112251/85/Lecture-6-58-320.jpg)
![Using MapReduce to Train SB
! Step 0: Count words [MR]
! Step 0.5: Assign IDs to words [vocabulary generation]
(more frequent $ smaller IDs)
! Step 1: Compute n-gram counts [MR]
! Step 2: Generate final LM “scores” [MR]
[MR] = MapReduce job](https://image.slidesharecdn.com/lecture6-151215112251/85/Lecture-6-59-320.jpg)
![Steps 1 2
Step 1 Step 2
Input Key DocID
First two words of n-grams
“a b c” and “a b” (“a b”)
Input Value Document Ctotal(“a b c”)
Intermediate
Key
n-grams
“a b c”
“a b c”
Intermediate
Value
Cdoc(“a b c”) S(“a b c”)
Partitioning
first two words (why?)
“a b”
last two words
“b c”
Output Value “a b c”, Ctotal(“a b c”) S(“a b c”) [write to disk]
Count
n-grams
Compute
LM scores
• All unigram counts are replicated in all partitions in both steps
• The clever partitioning in Step 2 is the key to efficient use at runtime!
• The trained LM model is composed of partitions written to disk
MapperInput
MapperOutput
ReducerInput
Reducer
Output](https://image.slidesharecdn.com/lecture6-151215112251/85/Lecture-6-61-320.jpg)






















































![[Book Reading] 機械翻訳 - Section 3 No.1](https://cdn.slidesharecdn.com/ss_thumbnails/languagemodel-150903031654-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
































