Download as PDF, PPTX



















































![English Tokenization
(small problem)
* Simplest regex:
[^s]+
* More advanced regex:
w+|[!"#$%&'*+,./:;<=>?@^`~…() {}[|] «»“”‘’-]⟨⟩ ‒–—―
* Even more advanced regex:
[+-]?[0-9](?:[0-9,.]*[0-9])?
|[w@](?:[w'’`@-][w']|[w'][w@'’`-])*[w']?
|["#$%&*+,/:;<=>@^`~…() {}[|] «»“”‘’']⟨⟩ ‒–—―
|[.!?]+
|-+
Add post-processing:
* concatenate abbreviations and decimals
* split contractions with regexes
- 2-character abbreviations regex:
i['‘’`]m|(?:s?he|it)['‘’`]s|(?:i|you|s?he|we|they)['‘’`]d$
- 3-character abbreviations regex:
(?:i|you|s?he|we|they)['‘’`](?:ll|[vr]e)|n['‘’`]t$
https://github.com/lang-uk/tokenize-uk/blob/master/tokenize_uk/tokeni
ze_uk.py](https://image.slidesharecdn.com/dataspring18-nlp-full-circle-180601070146/85/NLP-Project-Full-Circle-56-320.jpg)
![Error Correction
(inherently rule-based)
LanguageTool:<category name=" " id="STYLE" type="style">Стиль
<rulegroup id="BILSH_WITH_ADJ" name=" ">Більш з прикметниками
<rule>
<pattern>
<token> </token>більш
<token postag_regexp="yes" postag="ad[jv]:.*compc.*">
<exception> </exception>менш
</token>
</pattern>
<message> « » </message>Після більш не може стояти вища форма прикметника
<!-- TODO: when we can bind comparative forms togher again
<suggestion><match no="2"/></suggestion>
<suggestion><match no="1"/> <match no="2" postag_regexp="yes"
postag="(.*):compc(.*)" postag_replace="$1:compb$2"/></suggestion>
<example correction=" | "><marker>Світліший Більш світлий Більш
</marker>.</example>світліший
-->
<example correction=""><marker> </marker>.</example>Більш світліший
<example> </example>все закінчилось більш менш
</rule>
...
https://github.com/languagetool-org/languagetool/blob/master/languagetool-language-modu
les/uk/src/main/resources/org/languagetool/rules/uk/](https://image.slidesharecdn.com/dataspring18-nlp-full-circle-180601070146/85/NLP-Project-Full-Circle-57-320.jpg)


























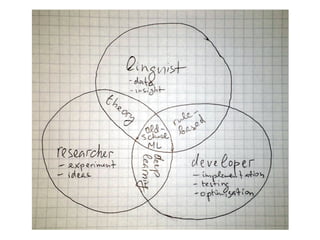
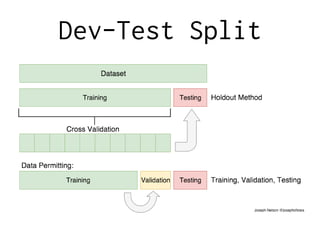
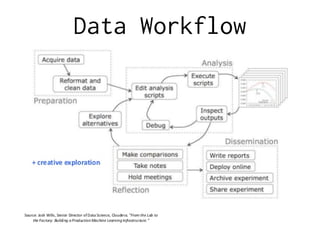
This document summarizes a presentation on different approaches to solving natural language processing problems. It discusses rule-based, counting-based, and deep learning-based approaches. For each approach, it provides examples including English tokenization, error correction, dialogue systems, and spam filtering. The presentation covers key stages of an NLP project including domain analysis, data preparation and collection, iterating on solutions, and gathering feedback. It emphasizes the importance of data and discusses techniques for data acquisition such as scraping, annotation, and crowdsourcing.

















































































