Download to read offline















![Lead function (1/3)
SELECT (t1.decimal0803_col_3) / (t1.decimal0803_col_3) AS decimal_col,
CAST(696 AS STRING) AS char_col, t1.decimal0803_col_3,
(COALESCE(CAST('0.02' AS DECIMAL(10,10)),
CAST('0.47' AS DECIMAL(10,10)),
CAST('-0.53' AS DECIMAL(10,10)))) +
(LEAD(-65, 4) OVER (ORDER BY (t1.decimal0803_col_3) / (t1.decimal0803_col_3),
CAST(696 AS STRING))) AS decimal_col_1,
CAST(-349 AS STRING) AS char_col_1
FROM table_16 t1
WHERE (943) > (889)
Error: Column 4 in row 10 does not match:
[1.0, 696, -871.81, <<-64.98>>, -349] SPARK row
[1.0, 696, -871.81, <<None>>, -349] POSTGRESQL row](https://image.slidesharecdn.com/sparksummiteucorrectnessandperformanceofapachesparksql-190123083132/85/Correctness-and-Performance-of-Apache-Spark-SQL-19-320.jpg)














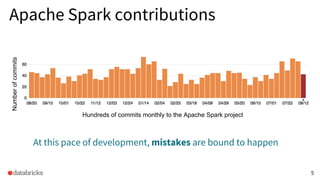
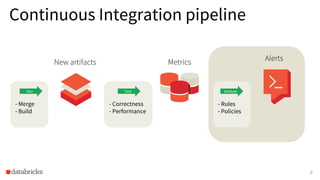
1) The document discusses ensuring correctness and performance of Apache Spark SQL through extensive testing that goes beyond unit and integration testing to include techniques like random query generation, failure testing, and micro and macro benchmarks. 2) It describes Databricks' continuous integration pipeline for Spark that classifies issues, analyzes regressions, and alerts on problems to minimize impacts. 3) As an example, it details an investigation that found a 18% regression in query performance between Spark 2.3 and 2.4 due to changes in hashing functions, and the steps taken like profiling and bisection to root cause and address the issue.


























































![Vagrant + Docker provider [+Puppet]](https://cdn.slidesharecdn.com/ss_thumbnails/npoggivagrant-docker-140725100147-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















