Download as PDF, PPTX

![What is BigBench (TPCx-BB1)?
• Specification-based benchmark with an open-source implementation, proposed as
the first Big Data benchmark standard.
• BigBench covers all major Big Data characteristics
• Volume -> Scale factor.
• Velocity -> Table refresh.
• Variety -> Data type disparity.
• Extension of TPC-DS.
• Borrows 10 pure QL queries from TCP-DS.
• Added BigData tables and use cases: Machine Learning, Natural Language Processing, ...
• Can support multiple implementations, multiple BigData engines and table formats.
• Can execute multiple parallel streams.
• Defines scale factors for data.
• Tested: 100 GB.
2[1]: http://www.tpc.org/tpc_documents_current_versions/pdf/tpcx-bb_v1.2.0.pdf](https://image.slidesharecdn.com/usingbigbenchtocomparehiveandspark-170205120522/75/Using-BigBench-to-compare-Hive-and-Spark-short-version-2-2048.jpg)
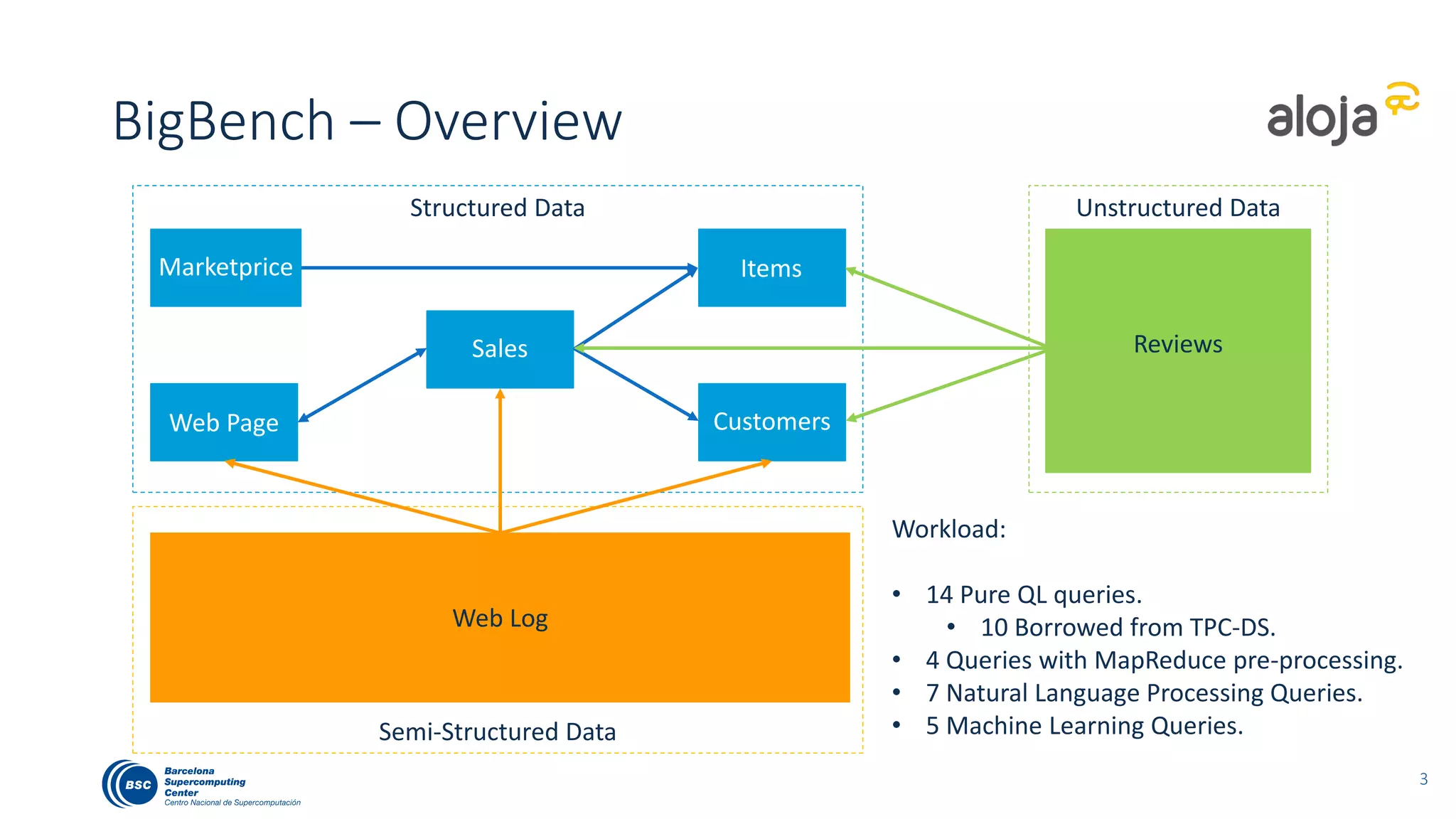
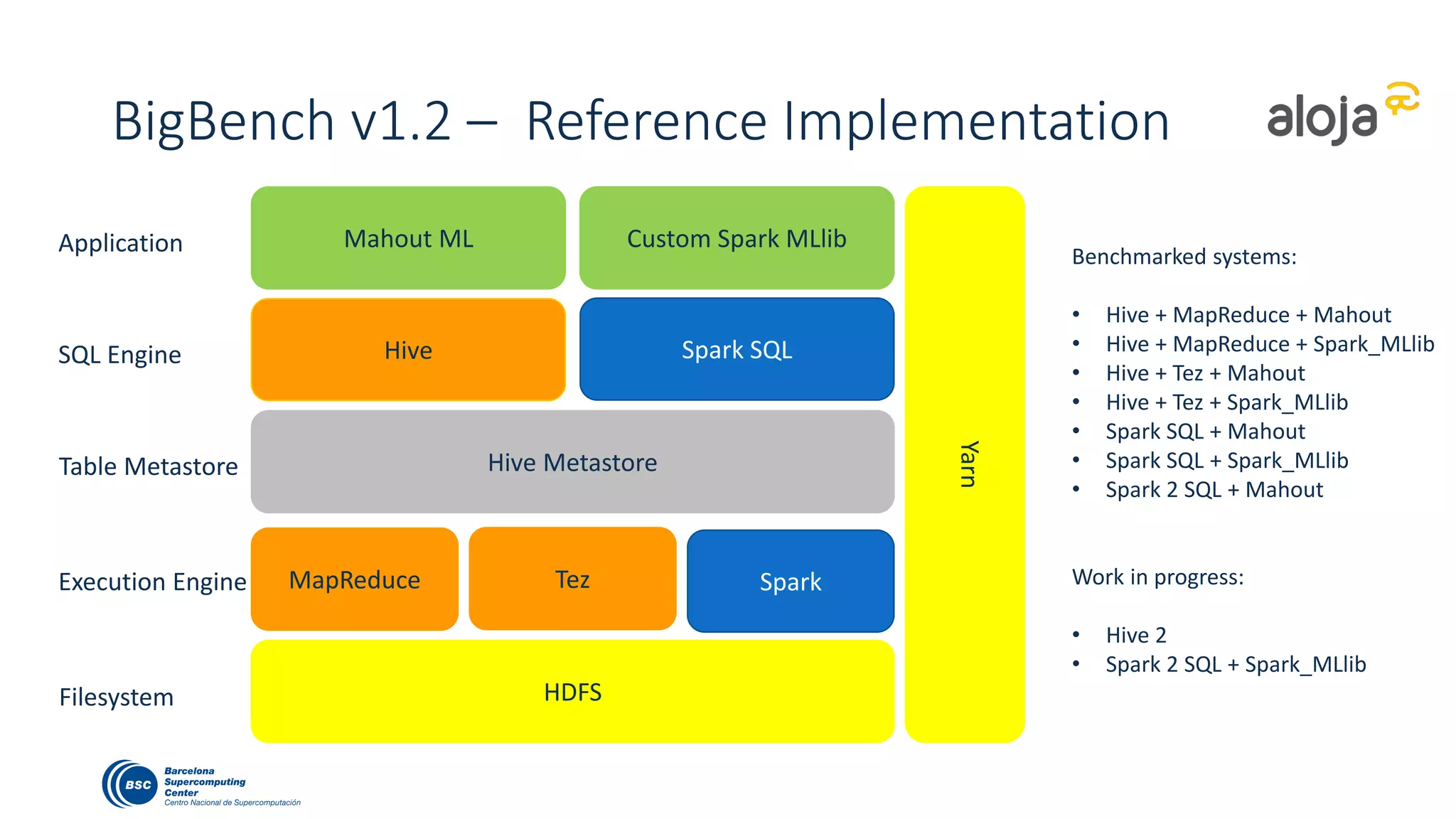

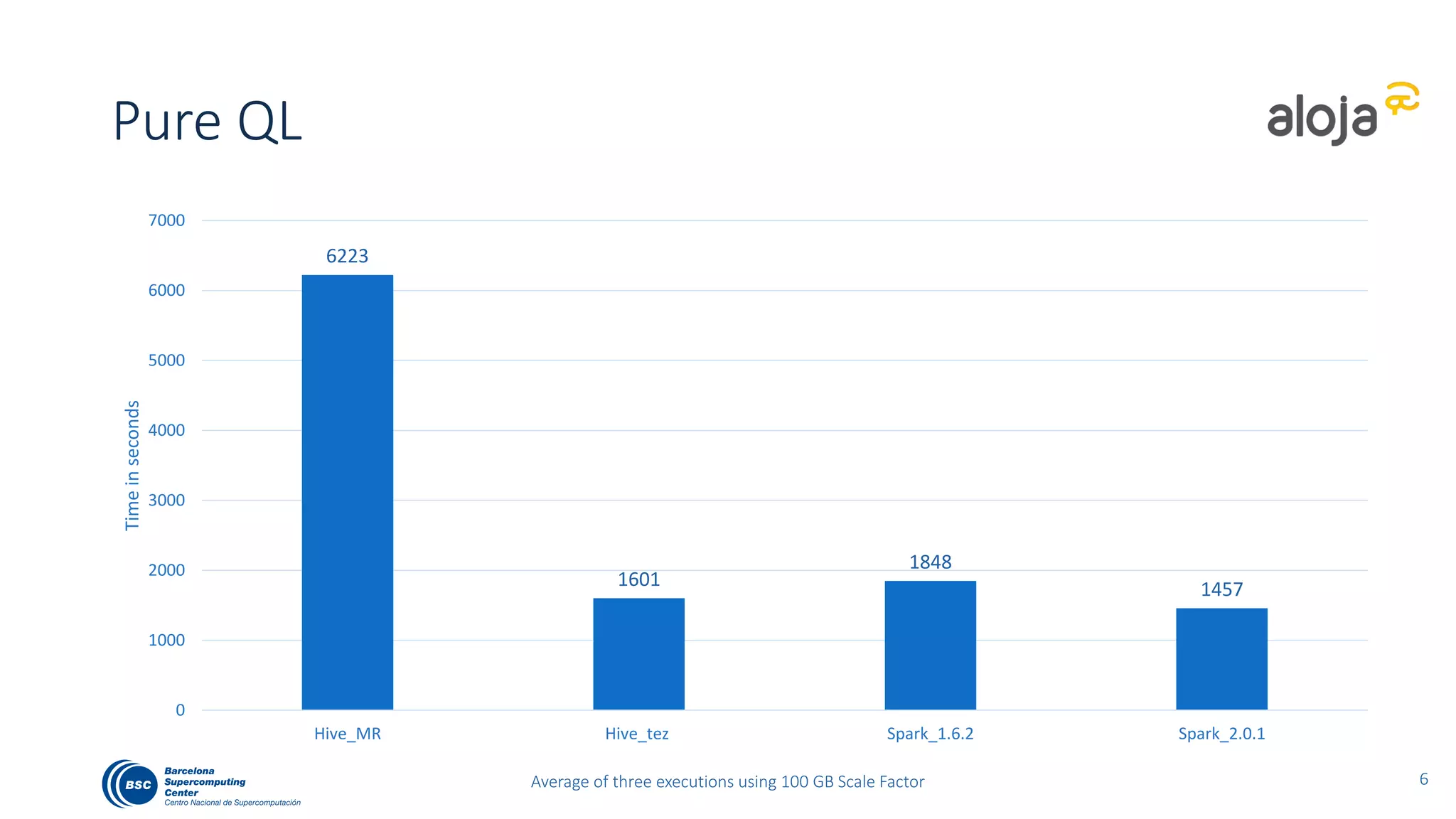
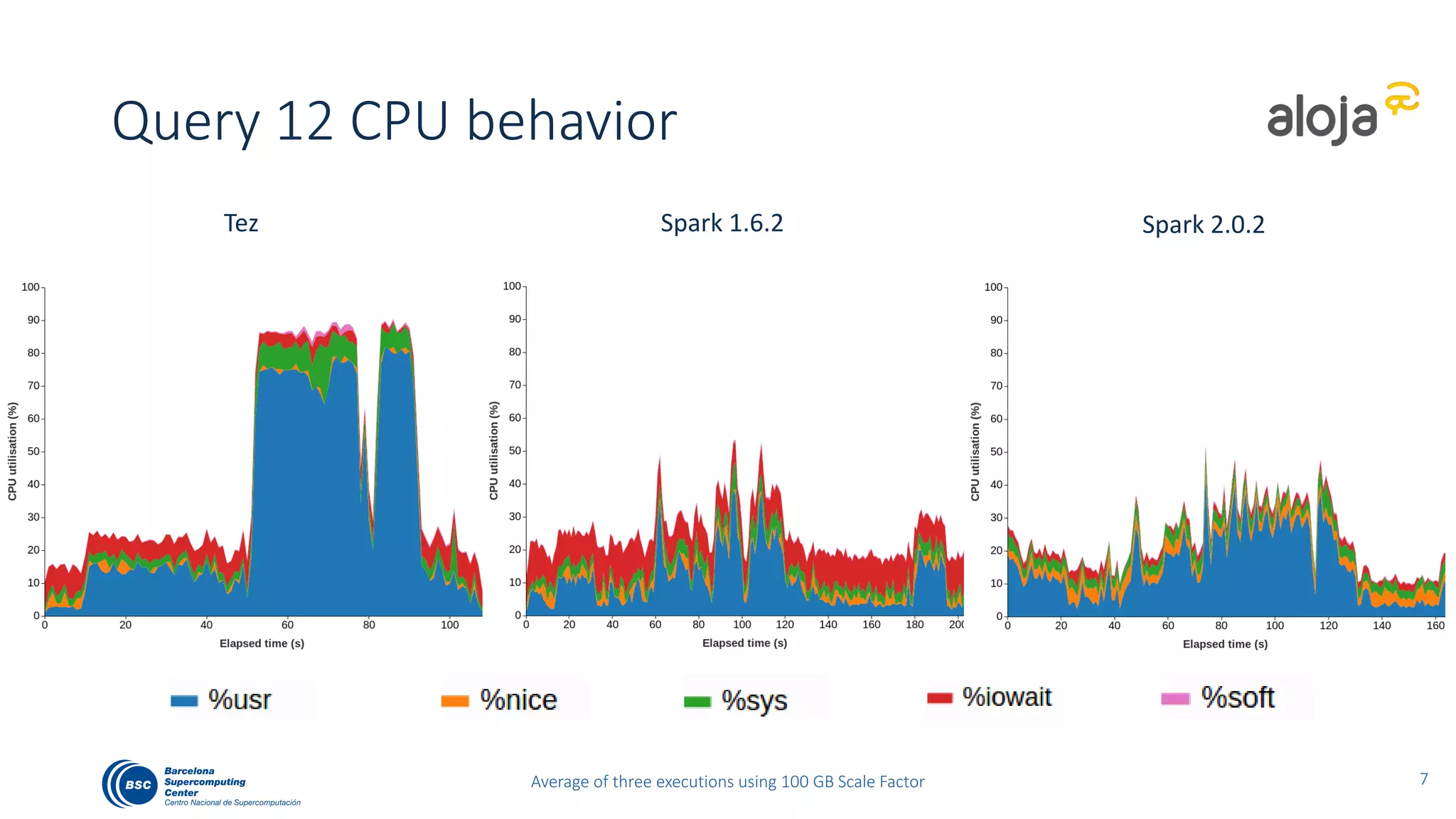
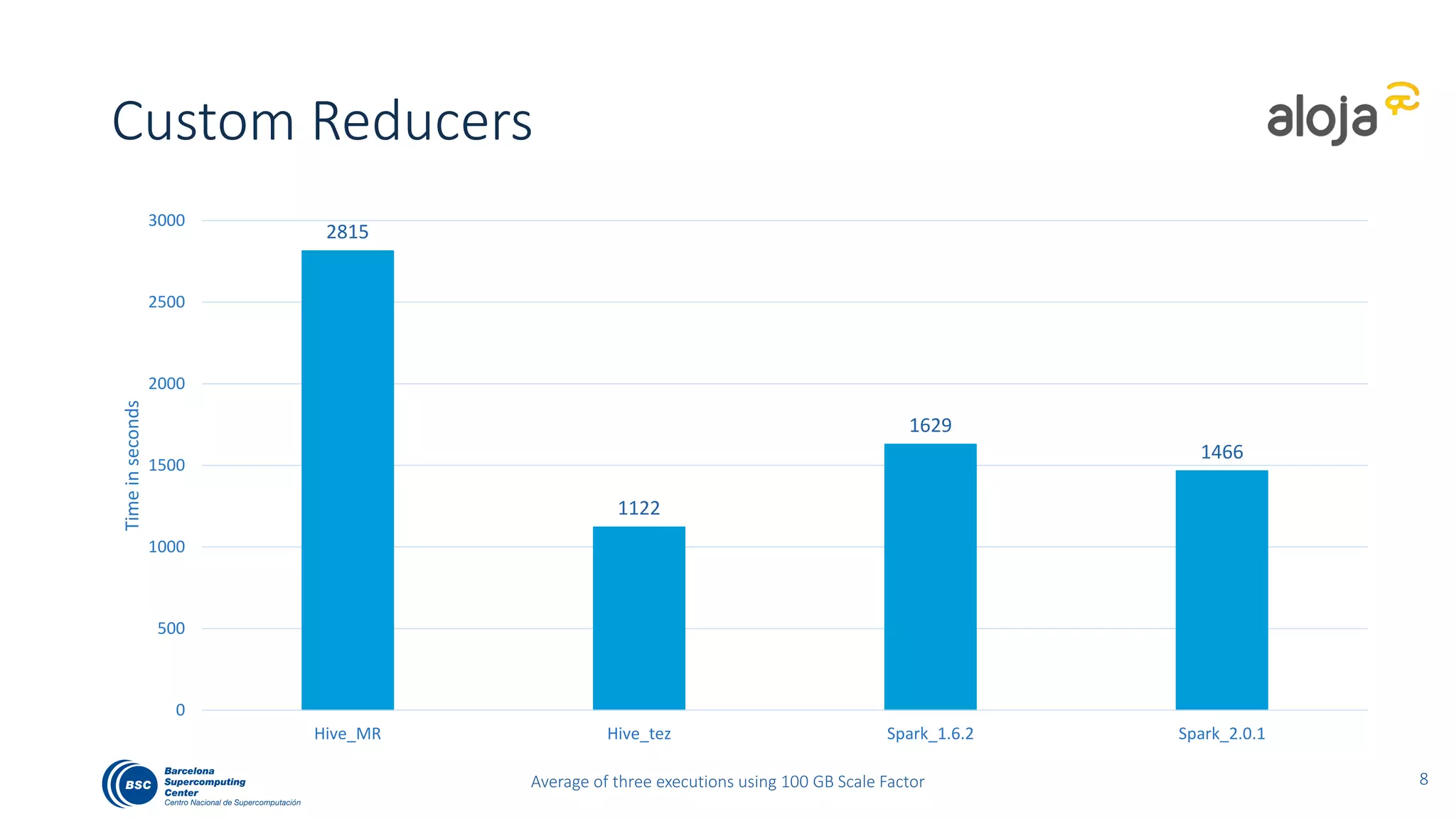
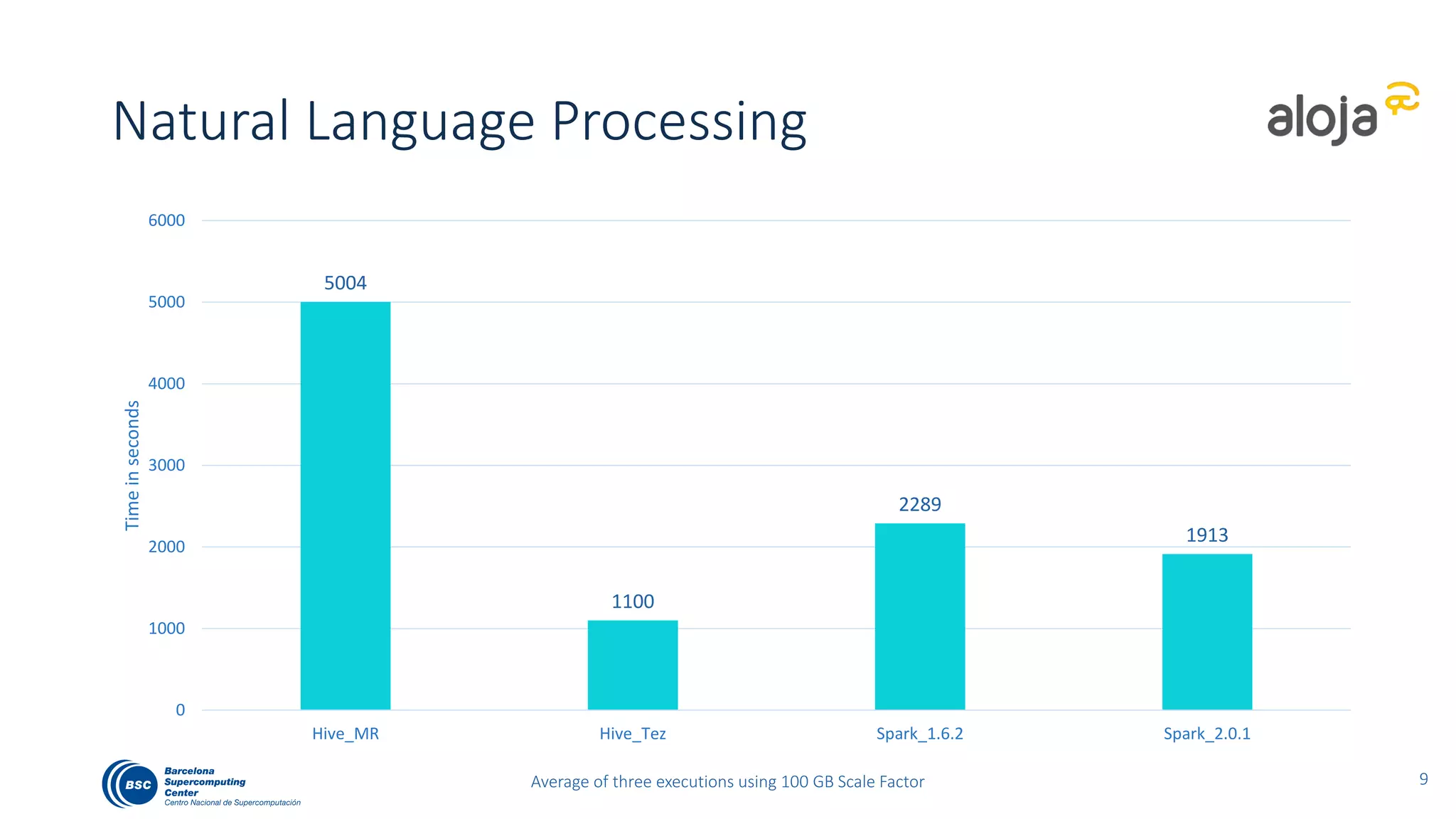
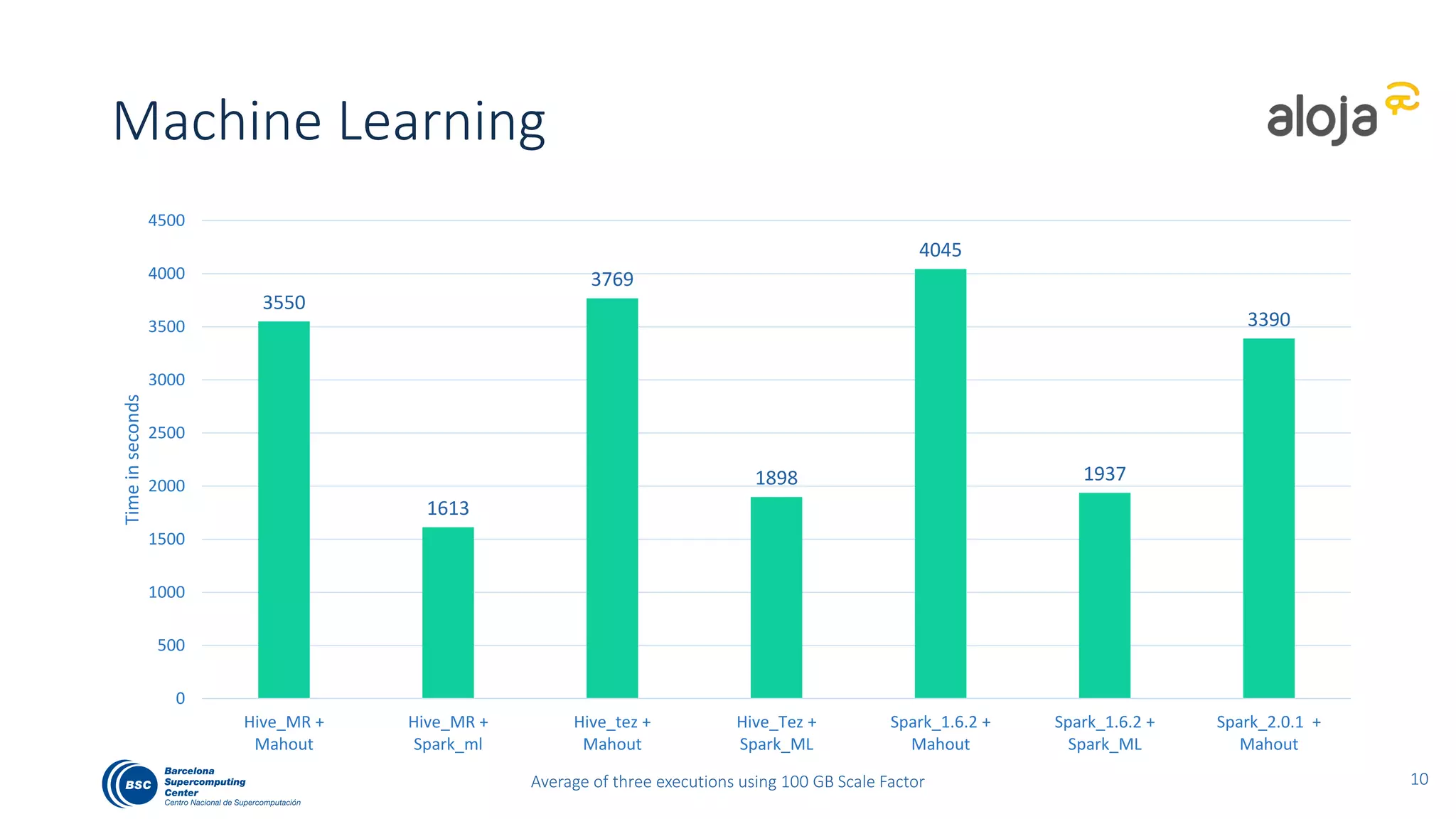
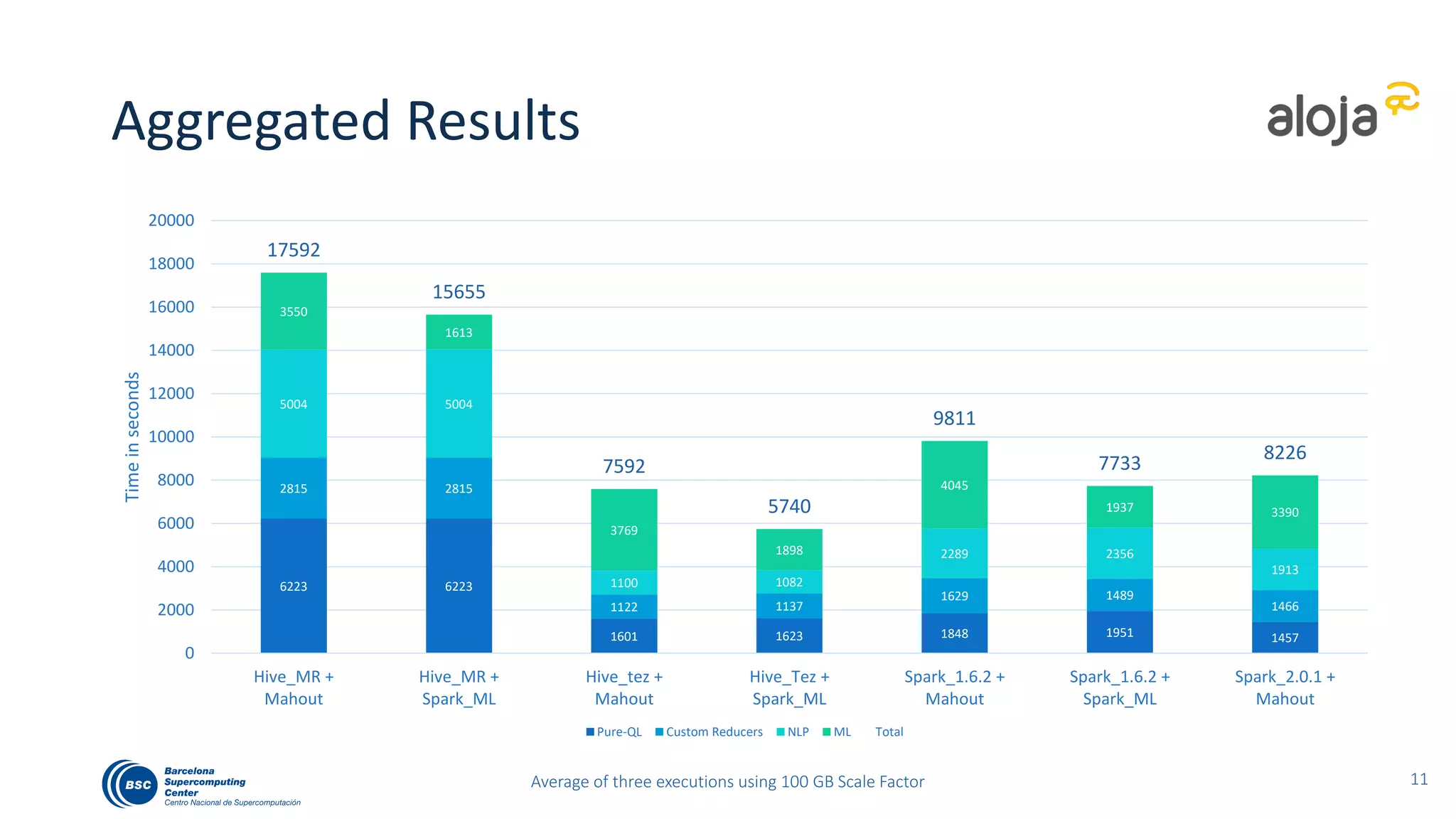


The document discusses BigBench, an open-source benchmark standard for big data that evaluates Hive and Spark using various queries from TPC-DS and additional machine learning and NLP use cases. It highlights the performance improvements of Hive on Tez compared to MapReduce and Spark, and suggests that Apache Tez combined with Spark MLlib is the best approach for production. The benchmark tests a 100 GB dataset across different configurations, revealing Hive on Tez as the most efficient option.






































































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

