Download as PDF, PPTX































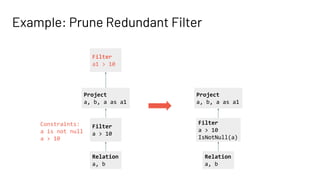




![Optimized Constraint Propagation (SPARK-33152)
• Traverses tree from bottom to top
• On Filter node, create additional null constraints
• On Project node, create Lists where
• Each List maintains original attribute and its aliases and constraint is
stored in terms of original attribute
Relation
a, b
Filter
a > 10
Constraints:
a is not null
a > 10
Project
a, b, a as a1
Constraints:
a is not null
a > 10
Aliases:
[a, a1]](https://image.slidesharecdn.com/287lishahid-210610232734/85/Optimizing-the-Catalyst-Optimizer-for-Complex-Plans-39-320.jpg)
![Optimized Constraint Propagation (SPARK-33152)
• To prune filter
• Rewrite expression in terms of original attribute
• a1 > 10 becomes a > 10
• Check if canonical version already exists in constraints
Relation
a, b
Filter
a > 10
Project
a, b, a as a1
Constraints:
a is not null
a > 10
Aliases:
[a, a1]
Filter
a1 > 10
Relation
a, b
Filter
a > 10
Project
a, b, a as a1](https://image.slidesharecdn.com/287lishahid-210610232734/85/Optimizing-the-Catalyst-Optimizer-for-Complex-Plans-40-320.jpg)
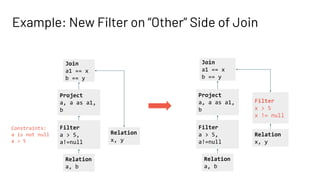
![Optimized Constraint Propagation (SPARK-33152)
• To add a new filter to right hand side of join
• Rewrite expression in terms of original attributes
• Check if any constraint exists on join key
Relation
a, b
Filter
a + b > 5,
a!=null,
b!=null
Project
a, a as a1,
b, b as b1
Constraints:
a is not null
b is not null
a + b > 5
Aliases:
[a, a1]
[b, b1]
Join
a1 == x
b1 == y
Relation
x, y
Filter
x + y > 5
x != null
y != null
Relation
a, b
Filter
a + b > 5,
a!=null,
b!=null
Project
a, a as a1,
b, b as b1
Join
a1 == x
b1 == y
Relation
x, y](https://image.slidesharecdn.com/287lishahid-210610232734/85/Optimizing-the-Catalyst-Optimizer-for-Complex-Plans-41-320.jpg)





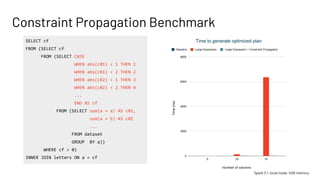
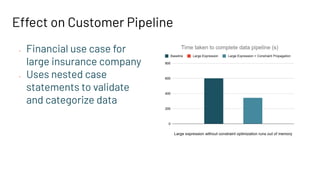






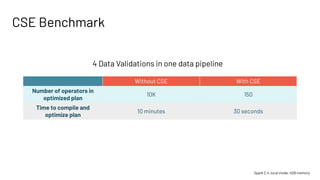
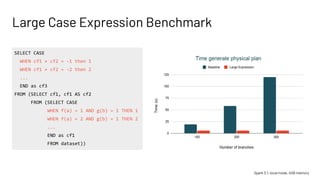
This presentation by Jianneng Li and Asif Shahid focuses on optimizing the Catalyst optimizer for complex plans in Spark, specifically in Workday Prism Analytics. Key topics include common subexpression elimination (CSE), handling large case expressions, and constraint propagation to enhance performance and efficiency. The session also outlines tuning tips and future improvements for the Catalyst rule engine.























































































