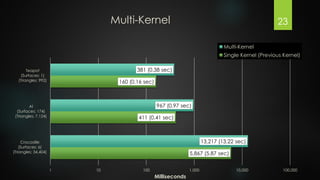
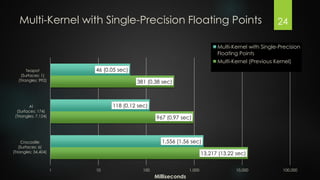
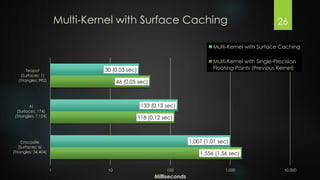
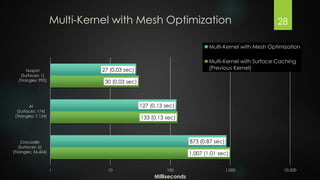
The document presents an exploration of GPU ray tracing using CUDA, detailing the development of both sequential CPU and parallel GPU ray tracers. It outlines the principles of ray tracing, CUDA's architecture, and performance results highlighting the speed differences between CPU and GPU implementations. Future work is suggested to include spatial partitioning and optimization for multiple GPUs.

































































![[2018 GDC] Real-Time Ray-Tracing Techniques for Integration into Existing Ren...](https://cdn.slidesharecdn.com/ss_thumbnails/gdc2018takahiroharada-180330041526-thumbnail.jpg?width=640&height=640&fit=bounds)























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





