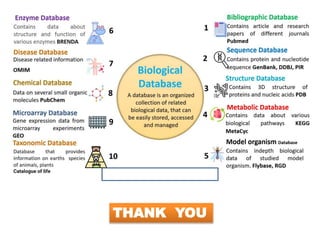
The document discusses biological databases in bioinformatics, explaining their purpose, structure, and types including primary, secondary, and composite databases. Primary databases store original biological data while secondary databases provide processed information derived from primary data. The major public sequence databases mentioned are GenBank, EMBL, and DDBJ, which house raw nucleic acid sequence data from researchers worldwide.





























































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)















