Download as PDF, PPTX











![Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
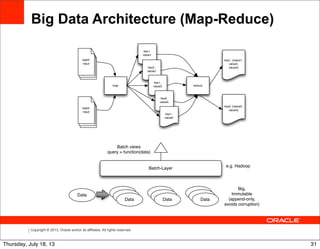
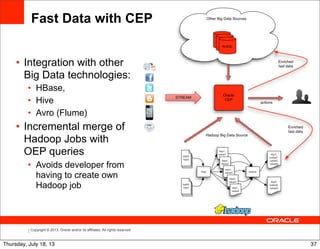
Stream-relation Window Operator
Time (in secs) Input event Output event
00 ∅ {AVG(price) = 0.0}
01 {symbol = “aaa”, price = 4.0} {AVG(price) = 4.0}
10 {symbol = “bbb”, price = 2.0} {AVG(price) = 3.0}
59 {symbol = “aaa”, price = 5.0} {AVG(price) = 3.6}
61 ∅ {AVG(price) = 3.5}
70 ∅ {AVG(price) = 5.0}
80 {symbol = “aaa”, price = 6.0} {AVG(price) = 5.5}
SELECT AVG(price)
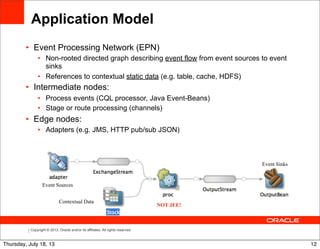
FROM marketFeed [RANGE 1 MINUTE]
19Thursday, July 18, 13](https://image.slidesharecdn.com/speeding-upbigdatawitheventprocessing-130718074209-phpapp01/85/Speeding-up-big-data-with-event-processing-21-320.jpg)

![Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
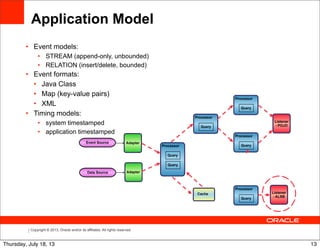
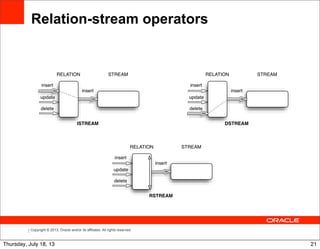
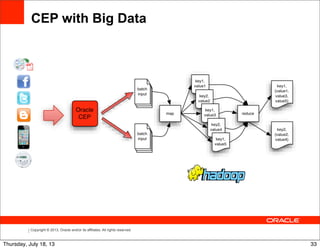
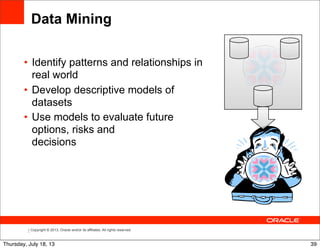
Relation-stream operators
Time Input event WINDOW ISTREAM output
output
00 ∅ +{AVG(price) = 0.0} +{AVG(price) = 0.0}
01 +{price = 4.0} -{AVG(price) = 0.0}, +{AVG(price) = 4.0}
+{AVG(price) = 4.0}
10 +{price = 2.0} -{AVG(price) = 4.0}, +{AVG(price) = 3.0}
+{AVG(price) = 3.0}
59 +{price = 5.0} -{AVG(price) = 3.0}, +{AVG(price) = 3.6}
+{AVG(price) = 3.6}
61 ∅ -{AVG(price) = 3.6}, +{AVG(price) = 3.5}
+{AVG(price) = 3.5}
70 ∅ -{AVG(price) = 3.5}, +{AVG(price) = 5.0}
+{AVG(price) = 5.0}
80 +{price = 6.0} -{AVG(price) = 5.0}, +{AVG(price) = 5.5}
+{AVG(price) = 5.5}
ISTREAM (SELECT AVG(price)
FROM marketFeed [RANGE 1 MINUTE])
DSTREAM (SELECT AVG(price)
FROM marketFeed [RANGE 1 MINUTE])
Time Input event WINDOW DSTREAM output
output
00 ∅ +{AVG(price) = 0.0} ∅
01 +{price = 4.0} -{AVG(price) = 0.0}, +{AVG(price) = 0.0}
+{AVG(price) = 4.0}
10 +{price = 2.0} -{AVG(price) = 4.0}, +{AVG(price) = 4.0}
+{AVG(price) = 3.0}
59 +{price = 5.0} -{AVG(price) = 3.0}, +{AVG(price) = 3.0}
+{AVG(price) = 3.6}
61 ∅ -{AVG(price) = 3.6}, +{AVG(price) = 3.6}
+{AVG(price) = 3.5}
70 ∅ -{AVG(price) = 3.5}, +{AVG(price) = 3.5}
+{AVG(price) = 5.0}
80 +{price = 6.0} -{AVG(price) = 5.0}, +{AVG(price) = 5.0}
+{AVG(price) = 5.5}
22Thursday, July 18, 13](https://image.slidesharecdn.com/speeding-upbigdatawitheventprocessing-130718074209-phpapp01/85/Speeding-up-big-data-with-event-processing-24-320.jpg)
![Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
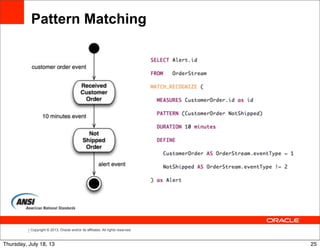
Pattern Matching
• Detect complex relationships amongst events
• State-machine model
• ANSI standards proposal
• IBM, Oracle, Streambase
• Starting to see adoption by other vendors/users (e.g.
MySQL) [1]
23Thursday, July 18, 13](https://image.slidesharecdn.com/speeding-upbigdatawitheventprocessing-130718074209-phpapp01/85/Speeding-up-big-data-with-event-processing-25-320.jpg)









This document discusses event processing and big data. It begins with an introduction to complex event processing (CEP) including key concepts like event streams and windows. It then covers big data scenarios where CEP can be used to analyze large volumes and varieties of event data in real-time. The document also provides an overview of the Oracle CEP architecture and how it can integrate with big data technologies like Hadoop.
























































































