Download as PDF, PPTX





![Pattern and Sequence Detection
● Pattern and sequence detection is the crown-jewel of CEP.
● Addresses a sequence of events that occur in order and are
correlated based on values of their attributes.
● Event patterns are implemented using a specialized state machine
approach.
7
from every (a1 = transactionStream [a1.amountWithdrawed < 100]
→ a2 = transactionStream [(a1.toAccountNo == a2.fromAccountNo) and (amountWithdrawed > 10000)]
within 5 min
select a1.fromAccountNo as suspectAccountNo
insert into possibleMoneyLaunderingActivityStream;](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-7-320.jpg)

![Need for Scaling
● Scaling - Ability for a CEP system to handle larger or complex queries by adding
more resources
● Mostly CEP engines run in a large box, scaling up horizontally.
Scaling CEP has several dimensions:
1. Handling Large no of queries
2. Queries that needs large working memory
3. Handling a complex query that might not fit within a single machine
4. Handling large number of events
9
● S. Perera, How to scale Complex Event Processing (CEP) Systems? [online]. Available:
http://srinathsview.blogspot.com/2012/05/how-to-scale-complex-event-processing.html. [Dec. 23, 2014].](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-9-320.jpg)


![Partition Based Scaling
13
● R. Mayer, B. Koldehofe, and K. Rothermel, “Meeting Predictable Buffer Limits in the Parallel Execution of Event Processing Operators,” In Proc. IEEE BigData ‟04,
Washington, USA, Oct 2014, pp. 402–411.
● S. Perera, How to scale Complex Event Processing (CEP) Systems? [online]. Available: http://srinathsview.blogspot.com/2012/05/how-to-scale-complex-
event-processing.html.](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-13-320.jpg)
![Storm-Based Scaling
● T. Dudziak, Storm & Esper [online], Available: https://tomdzk.wordpress.com/2011/09/28/storm-esper/. [Jan. 06, 2015].
● S. Ravindra, WSO2 CEP 4.0.0 in Distributed Mode [online]. Available: http://sajithr.blogspot.com/2015/09/wso2-cep-400-in-distributed-mode.html. [Feb. 23,
2017]. 15](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-15-320.jpg)
![Distributed Object Cache Based Scaling
● Magmasystems Blog, CEP Engines and Object Caches [online]. Available:
http://magmasystems.blogspot.com/2008/02/cep-engines-and-object-caches.html. [Dec. 23, 2014]. 16](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-16-320.jpg)

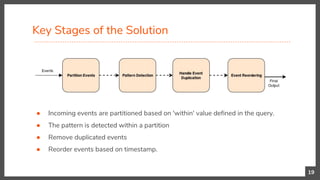
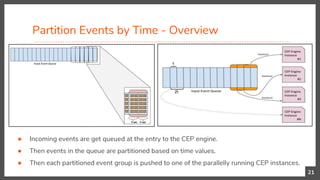
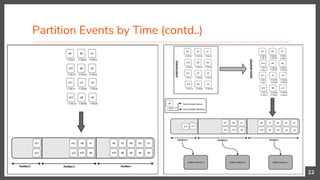
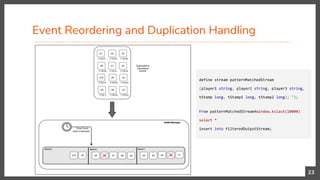
![Partition Events by Time
20
from every h1 = hitStream -> h2 = hitStream[h1.pid != pid and h1.tid == tid] -> h3 = hitStream[h1.pid == pid]
within 5 seconds
select h1.pid as player1, h2.pid as player2, h3.pid as player3, h1.tsr as tStamp1 , h2.tsr as tStamp2 , h3.tsr as
tStamp3
insert into patternMatchedStream;
Here we are looking for following 3 states,
1. Ball hit from a player x of team 1
2. Then, a ball hit from another player y of opponent team 2
3. Finally, a ball hit from the same player x who hit first.
Moreover, these 3 states needs to happen within 5 seconds.](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-20-320.jpg)


![Benchmark
Soccer monitoring benchmark is based on the DEBS (Distributed Event Based Systems) 2013
Grand Challenge
28
● Data used for this benchmark is collected
by the real-time locating system deployed
on a football field in Germany.
● Totally 47 Millions of events.
● Average event size is 365 bytes.
● Every event describes a position of a
given sensor in a 3D coordinate system.
● DEBS Org, DEBS 2013 Grand Challenge: Soccer monitoring [online]. Available: http://debs.org/?p=41. [Jan. 05th, 2017]](https://image.slidesharecdn.com/scaling-pattern-and-sequence-queries-in-complex-event-processing-180603115345/85/Scaling-Pattern-and-Sequence-Queries-in-Complex-Event-Processing-28-320.jpg)

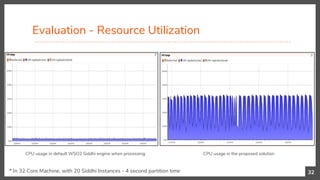
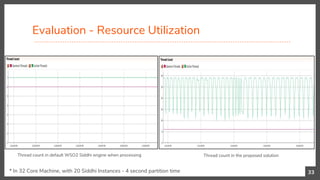
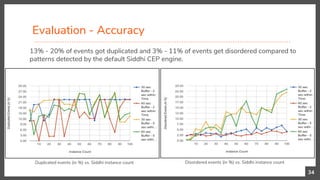
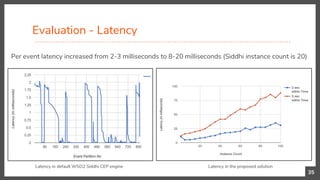






This document presents a research contribution on scaling pattern and sequence detection in complex event processing (CEP) to achieve high event rates through a proposed time-based event partitioning approach. Results show an 800% improvement in throughput while addressing issues of event duplication and reordering. The approach is designed to be independent of the internal implementation of any CEP engine, with potential applications for scaling other CEP queries that can be partitioned by time.














































